 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
Learning Audio-Driven Viseme Dynamics for 3D Face Animation
Jan 15, 2023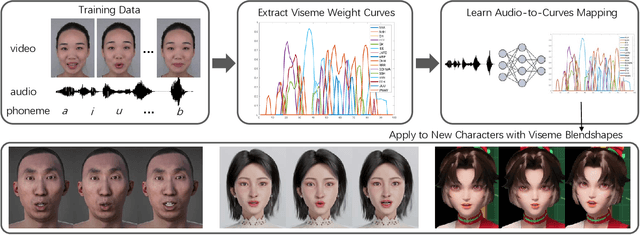
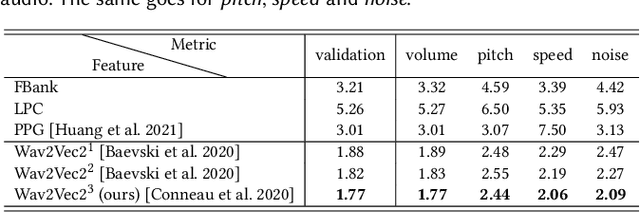
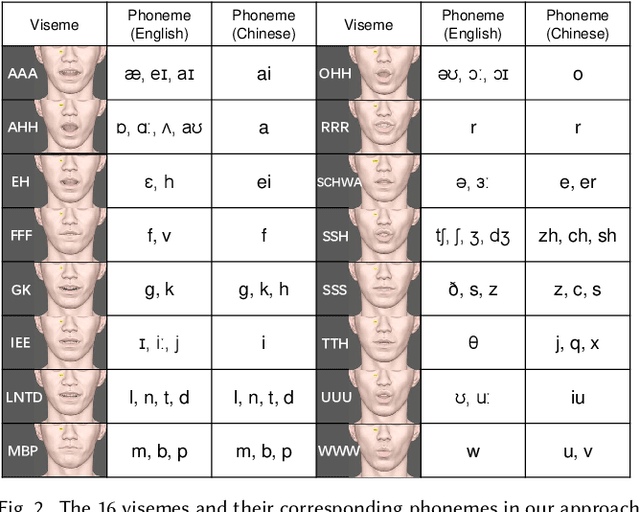
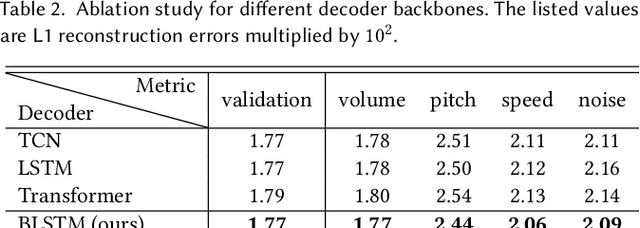
We present a novel audio-driven facial animation approach that can generate realistic lip-synchronized 3D facial animations from the input audio. Our approach learns viseme dynamics from speech videos, produces animator-friendly viseme curves, and supports multilingual speech inputs. The core of our approach is a novel parametric viseme fitting algorithm that utilizes phoneme priors to extract viseme parameters from speech videos. With the guidance of phonemes, the extracted viseme curves can better correlate with phonemes, thus more controllable and friendly to animators. To support multilingual speech inputs and generalizability to unseen voices, we take advantage of deep audio feature models pretrained on multiple languages to learn the mapping from audio to viseme curves. Our audio-to-curves mapping achieves state-of-the-art performance even when the input audio suffers from distortions of volume, pitch, speed, or noise. Lastly, a viseme scanning approach for acquiring high-fidelity viseme assets is presented for efficient speech animation production. We show that the predicted viseme curves can be applied to different viseme-rigged characters to yield various personalized animations with realistic and natural facial motions. Our approach is artist-friendly and can be easily integrated into typical animation production workflows including blendshape or bone based animation.
MC-Nonlocal-PINNs: handling nonlocal operators in PINNs via Monte Carlo sampling
Dec 26, 2022We propose, Monte Carlo Nonlocal physics-informed neural networks (MC-Nonlocal-PINNs), which is a generalization of MC-fPINNs in \cite{guo2022monte}, for solving general nonlocal models such as integral equations and nonlocal PDEs. Similar as in MC-fPINNs, our MC-Nonlocal-PINNs handle the nonlocal operators in a Monte Carlo way, resulting in a very stable approach for high dimensional problems. We present a variety of test problems, including high dimensional Volterra type integral equations, hypersingular integral equations and nonlocal PDEs, to demonstrate the effectiveness of our approach.
Flattening-Net: Deep Regular 2D Representation for 3D Point Cloud Analysis
Dec 17, 2022



Point clouds are characterized by irregularity and unstructuredness, which pose challenges in efficient data exploitation and discriminative feature extraction. In this paper, we present an unsupervised deep neural architecture called Flattening-Net to represent irregular 3D point clouds of arbitrary geometry and topology as a completely regular 2D point geometry image (PGI) structure, in which coordinates of spatial points are captured in colors of image pixels. \mr{Intuitively, Flattening-Net implicitly approximates a locally smooth 3D-to-2D surface flattening process while effectively preserving neighborhood consistency.} \mr{As a generic representation modality, PGI inherently encodes the intrinsic property of the underlying manifold structure and facilitates surface-style point feature aggregation.} To demonstrate its potential, we construct a unified learning framework directly operating on PGIs to achieve \mr{diverse types of high-level and low-level} downstream applications driven by specific task networks, including classification, segmentation, reconstruction, and upsampling. Extensive experiments demonstrate that our methods perform favorably against the current state-of-the-art competitors. We will make the code and data publicly available at https://github.com/keeganhk/Flattening-Net.
Multi-View Vision-to-Geometry Knowledge Transfer for 3D Point Cloud Shape Analysis
Jul 07, 2022



As two fundamental representation modalities of 3D objects, 2D multi-view images and 3D point clouds reflect shape information from different aspects of visual appearances and geometric structures. Unlike deep learning-based 2D multi-view image modeling, which demonstrates leading performances in various 3D shape analysis tasks, 3D point cloud-based geometric modeling still suffers from insufficient learning capacity. In this paper, we innovatively construct a unified cross-modal knowledge transfer framework, which distills discriminative visual descriptors of 2D images into geometric descriptors of 3D point clouds. Technically, under a classic teacher-student learning paradigm, we propose multi-view vision-to-geometry distillation, consisting of a deep 2D image encoder as teacher and a deep 3D point cloud encoder as student. To achieve heterogeneous feature alignment, we further propose visibility-aware feature projection, through which per-point embeddings can be aggregated into multi-view geometric descriptors. Extensive experiments on 3D shape classification, part segmentation, and unsupervised learning validate the superiority of our method. We will make the code and data publicly available.
Semi-signed neural fitting for surface reconstruction from unoriented point clouds
Jun 14, 2022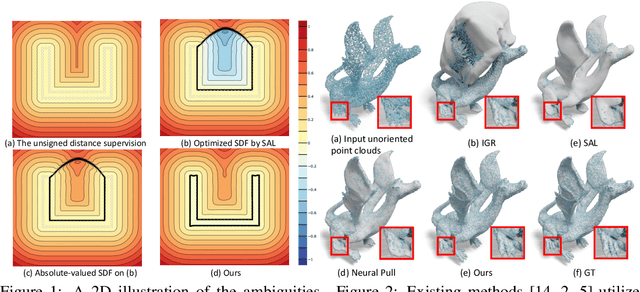
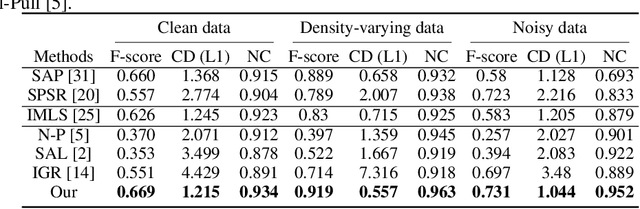
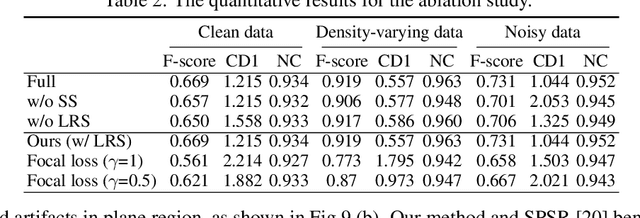
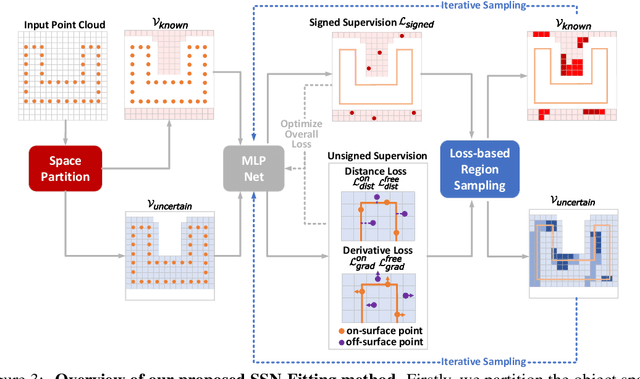
Reconstructing 3D geometry from \emph{unoriented} point clouds can benefit many downstream tasks. Recent methods mostly adopt a neural shape representation with a neural network to represent a signed distance field and fit the point cloud with an unsigned supervision. However, we observe that using unsigned supervision may cause severe ambiguities and often leads to \emph{unexpected} failures such as generating undesired surfaces in free space when reconstructing complex structures and struggle with reconstructing accurate surfaces. To reconstruct a better signed distance field, we propose semi-signed neural fitting (SSN-Fitting), which consists of a semi-signed supervision and a loss-based region sampling strategy. Our key insight is that signed supervision is more informative and regions that are obviously outside the object can be easily determined. Meanwhile, a novel importance sampling is proposed to accelerate the optimization and better reconstruct the fine details. Specifically, we voxelize and partition the object space into \emph{sign-known} and \emph{sign-uncertain} regions, in which different supervisions are applied. Also, we adaptively adjust the sampling rate of each voxel according to the tracked reconstruction loss, so that the network can focus more on the complex under-fitting regions. We conduct extensive experiments to demonstrate that SSN-Fitting achieves state-of-the-art performance under different settings on multiple datasets, including clean, density-varying, and noisy data.
WarpingGAN: Warping Multiple Uniform Priors for Adversarial 3D Point Cloud Generation
Mar 24, 2022We propose WarpingGAN, an effective and efficient 3D point cloud generation network. Unlike existing methods that generate point clouds by directly learning the mapping functions between latent codes and 3D shapes, Warping-GAN learns a unified local-warping function to warp multiple identical pre-defined priors (i.e., sets of points uniformly distributed on regular 3D grids) into 3D shapes driven by local structure-aware semantics. In addition, we also ingeniously utilize the principle of the discriminator and tailor a stitching loss to eliminate the gaps between different partitions of a generated shape corresponding to different priors for boosting quality. Owing to the novel generating mechanism, WarpingGAN, a single lightweight network after one-time training, is capable of efficiently generating uniformly distributed 3D point clouds with various resolutions. Extensive experimental results demonstrate the superiority of our WarpingGAN over state-of-the-art methods in terms of quantitative metrics, visual quality, and efficiency. The source code is publicly available at https://github.com/yztang4/WarpingGAN.git.
IDEA-Net: Dynamic 3D Point Cloud Interpolation via Deep Embedding Alignment
Mar 22, 2022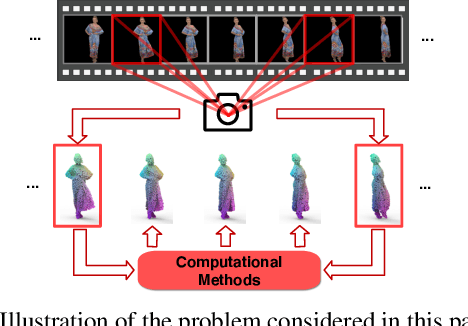

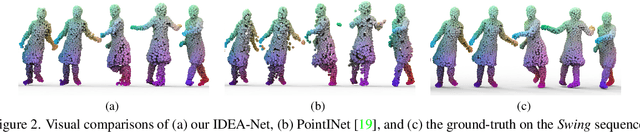

This paper investigates the problem of temporally interpolating dynamic 3D point clouds with large non-rigid deformation. We formulate the problem as estimation of point-wise trajectories (i.e., smooth curves) and further reason that temporal irregularity and under-sampling are two major challenges. To tackle the challenges, we propose IDEA-Net, an end-to-end deep learning framework, which disentangles the problem under the assistance of the explicitly learned temporal consistency. Specifically, we propose a temporal consistency learning module to align two consecutive point cloud frames point-wisely, based on which we can employ linear interpolation to obtain coarse trajectories/in-between frames. To compensate the high-order nonlinear components of trajectories, we apply aligned feature embeddings that encode local geometry properties to regress point-wise increments, which are combined with the coarse estimations. We demonstrate the effectiveness of our method on various point cloud sequences and observe large improvement over state-of-the-art methods both quantitatively and visually. Our framework can bring benefits to 3D motion data acquisition. The source code is publicly available at https://github.com/ZENGYIMING-EAMON/IDEA-Net.git.
CorrNet3D: Unsupervised End-to-end Learning of Dense Correspondence for 3D Point Clouds
Dec 31, 2020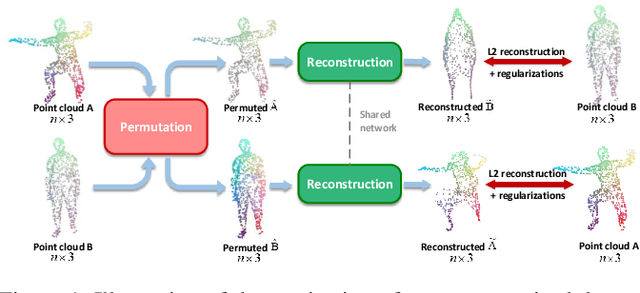

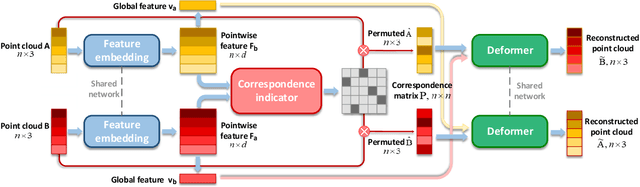
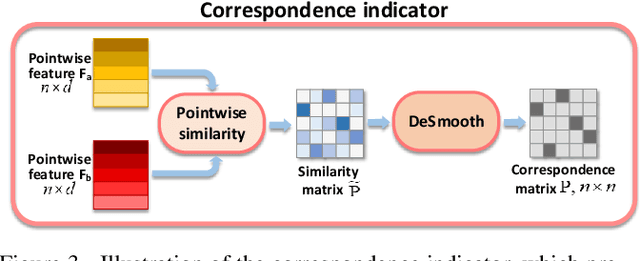
This paper addresses the problem of computing dense correspondence between 3D shapes in the form of point clouds, which is a challenging and fundamental problem in computer vision and digital geometry processing. Conventional approaches often solve the problem in a supervised manner, requiring massive annotated data, which is difficult and/or expensive to obtain. Motivated by the intuition that one can transform two aligned point clouds to each other more easily and meaningfully than a misaligned pair, we propose CorrNet3D -- the first unsupervised and end-to-end deep learning-based framework -- to drive the learning of dense correspondence by means of deformation-like reconstruction to overcome the need for annotated data. Specifically, CorrNet3D consists of a deep feature embedding module and two novel modules called correspondence indicator and symmetric deformation. Feeding a pair of raw point clouds, our model first learns the pointwise features and passes them into the indicator to generate a learnable correspondence matrix used to permute the input pair. The symmetric deformer, with an additional regularized loss, transforms the two permuted point clouds to each other to drive the unsupervised learning of the correspondence. The extensive experiments on both synthetic and real-world datasets of rigid and non-rigid 3D shapes show our CorrNet3D outperforms state-of-the-art methods to a large extent, including those taking meshes as input. CorrNet3D is a flexible framework in that it can be easily adapted to supervised learning if annotated data are available.
ParaNet: Deep Regular Representation for 3D Point Clouds
Dec 05, 2020
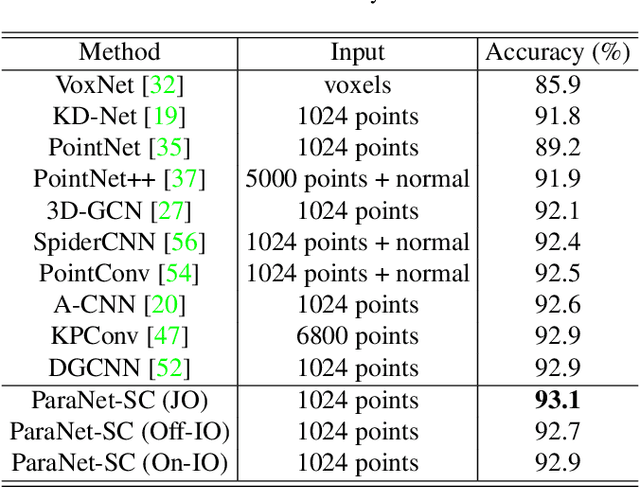
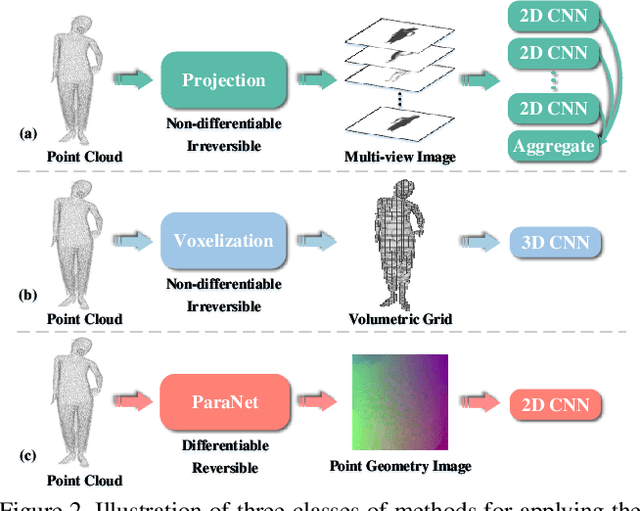

Although convolutional neural networks have achieved remarkable success in analyzing 2D images/videos, it is still non-trivial to apply the well-developed 2D techniques in regular domains to the irregular 3D point cloud data. To bridge this gap, we propose ParaNet, a novel end-to-end deep learning framework, for representing 3D point clouds in a completely regular and nearly lossless manner. To be specific, ParaNet converts an irregular 3D point cloud into a regular 2D color image, named point geometry image (PGI), where each pixel encodes the spatial coordinates of a point. In contrast to conventional regular representation modalities based on multi-view projection and voxelization, the proposed representation is differentiable and reversible. Technically, ParaNet is composed of a surface embedding module, which parameterizes 3D surface points onto a unit square, and a grid resampling module, which resamples the embedded 2D manifold over regular dense grids. Note that ParaNet is unsupervised, i.e., the training simply relies on reference-free geometry constraints. The PGIs can be seamlessly coupled with a task network established upon standard and mature techniques for 2D images/videos to realize a specific task for 3D point clouds. We evaluate ParaNet over shape classification and point cloud upsampling, in which our solutions perform favorably against the existing state-of-the-art methods. We believe such a paradigm will open up many possibilities to advance the progress of deep learning-based point cloud processing and understanding.