 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
WIPES: Wavelet-based Visual Primitives
Aug 18, 2025Pursuing a continuous visual representation that offers flexible frequency modulation and fast rendering speed has recently garnered increasing attention in the fields of 3D vision and graphics. However, existing representations often rely on frequency guidance or complex neural network decoding, leading to spectrum loss or slow rendering. To address these limitations, we propose WIPES, a universal Wavelet-based vIsual PrimitivES for representing multi-dimensional visual signals. Building on the spatial-frequency localization advantages of wavelets, WIPES effectively captures both the low-frequency "forest" and the high-frequency "trees." Additionally, we develop a wavelet-based differentiable rasterizer to achieve fast visual rendering. Experimental results on various visual tasks, including 2D image representation, 5D static and 6D dynamic novel view synthesis, demonstrate that WIPES, as a visual primitive, offers higher rendering quality and faster inference than INR-based methods, and outperforms Gaussian-based representations in rendering quality.
DAGSM: Disentangled Avatar Generation with GS-enhanced Mesh
Nov 20, 2024



Text-driven avatar generation has gained significant attention owing to its convenience. However, existing methods typically model the human body with all garments as a single 3D model, limiting its usability, such as clothing replacement, and reducing user control over the generation process. To overcome the limitations above, we propose DAGSM, a novel pipeline that generates disentangled human bodies and garments from the given text prompts. Specifically, we model each part (e.g., body, upper/lower clothes) of the clothed human as one GS-enhanced mesh (GSM), which is a traditional mesh attached with 2D Gaussians to better handle complicated textures (e.g., woolen, translucent clothes) and produce realistic cloth animations. During the generation, we first create the unclothed body, followed by a sequence of individual cloth generation based on the body, where we introduce a semantic-based algorithm to achieve better human-cloth and garment-garment separation. To improve texture quality, we propose a view-consistent texture refinement module, including a cross-view attention mechanism for texture style consistency and an incident-angle-weighted denoising (IAW-DE) strategy to update the appearance. Extensive experiments have demonstrated that DAGSM generates high-quality disentangled avatars, supports clothing replacement and realistic animation, and outperforms the baselines in visual quality.
UC-NeRF: Uncertainty-aware Conditional Neural Radiance Fields from Endoscopic Sparse Views
Sep 04, 2024Visualizing surgical scenes is crucial for revealing internal anatomical structures during minimally invasive procedures. Novel View Synthesis is a vital technique that offers geometry and appearance reconstruction, enhancing understanding, planning, and decision-making in surgical scenes. Despite the impressive achievements of Neural Radiance Field (NeRF), its direct application to surgical scenes produces unsatisfying results due to two challenges: endoscopic sparse views and significant photometric inconsistencies. In this paper, we propose uncertainty-aware conditional NeRF for novel view synthesis to tackle the severe shape-radiance ambiguity from sparse surgical views. The core of UC-NeRF is to incorporate the multi-view uncertainty estimation to condition the neural radiance field for modeling the severe photometric inconsistencies adaptively. Specifically, our UC-NeRF first builds a consistency learner in the form of multi-view stereo network, to establish the geometric correspondence from sparse views and generate uncertainty estimation and feature priors. In neural rendering, we design a base-adaptive NeRF network to exploit the uncertainty estimation for explicitly handling the photometric inconsistencies. Furthermore, an uncertainty-guided geometry distillation is employed to enhance geometry learning. Experiments on the SCARED and Hamlyn datasets demonstrate our superior performance in rendering appearance and geometry, consistently outperforming the current state-of-the-art approaches. Our code will be released at \url{https://github.com/wrld/UC-NeRF}.
MagicMan: Generative Novel View Synthesis of Humans with 3D-Aware Diffusion and Iterative Refinement
Aug 26, 2024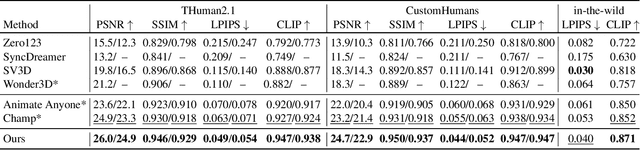
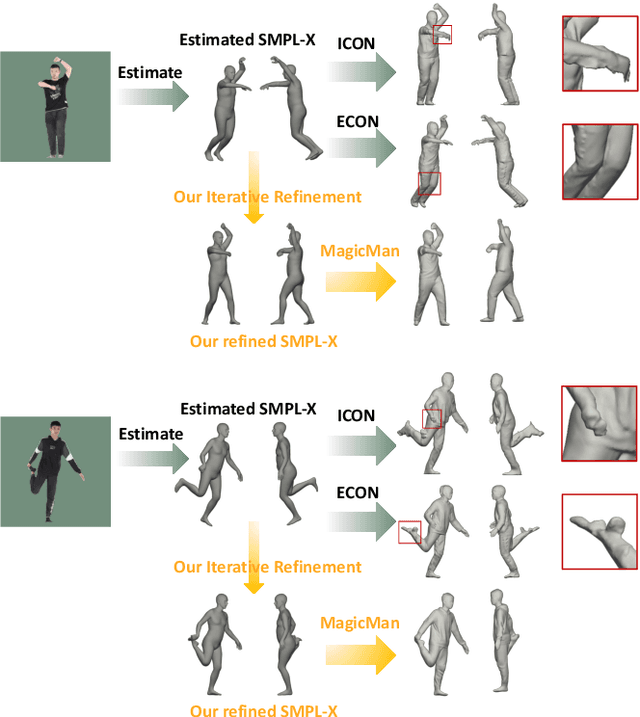
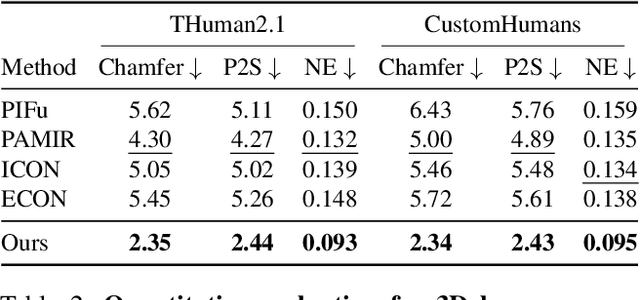
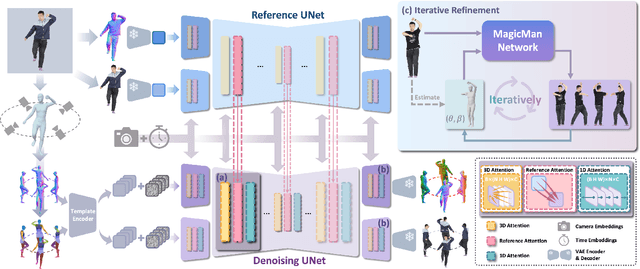
Existing works in single-image human reconstruction suffer from weak generalizability due to insufficient training data or 3D inconsistencies for a lack of comprehensive multi-view knowledge. In this paper, we introduce MagicMan, a human-specific multi-view diffusion model designed to generate high-quality novel view images from a single reference image. As its core, we leverage a pre-trained 2D diffusion model as the generative prior for generalizability, with the parametric SMPL-X model as the 3D body prior to promote 3D awareness. To tackle the critical challenge of maintaining consistency while achieving dense multi-view generation for improved 3D human reconstruction, we first introduce hybrid multi-view attention to facilitate both efficient and thorough information interchange across different views. Additionally, we present a geometry-aware dual branch to perform concurrent generation in both RGB and normal domains, further enhancing consistency via geometry cues. Last but not least, to address ill-shaped issues arising from inaccurate SMPL-X estimation that conflicts with the reference image, we propose a novel iterative refinement strategy, which progressively optimizes SMPL-X accuracy while enhancing the quality and consistency of the generated multi-views. Extensive experimental results demonstrate that our method significantly outperforms existing approaches in both novel view synthesis and subsequent 3D human reconstruction tasks.
GRAPE: Generalizable and Robust Multi-view Facial Capture
Jul 14, 2024



Deep learning-based multi-view facial capture methods have shown impressive accuracy while being several orders of magnitude faster than a traditional mesh registration pipeline. However, the existing systems (e.g. TEMPEH) are strictly restricted to inference on the data captured by the same camera array used to capture their training data. In this study, we aim to improve the generalization ability so that a trained model can be readily used for inference (i.e. capture new data) on a different camera array. To this end, we propose a more generalizable initialization module to extract the camera array-agnostic 3D feature, including a visual hull-based head localization and a visibility-aware 3D feature aggregation module enabled by the visual hull. In addition, we propose an ``update-by-disagreement'' learning strategy to better handle data noise (e.g. inaccurate registration, scan noise) by discarding potentially inaccurate supervision signals during training. The resultant generalizable and robust topologically consistent multi-view facial capture system (GRAPE) can be readily used to capture data on a different camera array, reducing great effort on data collection and processing. Experiments on the FaMoS and FaceScape datasets demonstrate the effectiveness of the proposed method.
Free-SurGS: SfM-Free 3D Gaussian Splatting for Surgical Scene Reconstruction
Jul 03, 2024



Real-time 3D reconstruction of surgical scenes plays a vital role in computer-assisted surgery, holding a promise to enhance surgeons' visibility. Recent advancements in 3D Gaussian Splatting (3DGS) have shown great potential for real-time novel view synthesis of general scenes, which relies on accurate poses and point clouds generated by Structure-from-Motion (SfM) for initialization. However, 3DGS with SfM fails to recover accurate camera poses and geometry in surgical scenes due to the challenges of minimal textures and photometric inconsistencies. To tackle this problem, in this paper, we propose the first SfM-free 3DGS-based method for surgical scene reconstruction by jointly optimizing the camera poses and scene representation. Based on the video continuity, the key of our method is to exploit the immediate optical flow priors to guide the projection flow derived from 3D Gaussians. Unlike most previous methods relying on photometric loss only, we formulate the pose estimation problem as minimizing the flow loss between the projection flow and optical flow. A consistency check is further introduced to filter the flow outliers by detecting the rigid and reliable points that satisfy the epipolar geometry. During 3D Gaussian optimization, we randomly sample frames to optimize the scene representations to grow the 3D Gaussian progressively. Experiments on the SCARED dataset demonstrate our superior performance over existing methods in novel view synthesis and pose estimation with high efficiency. Code is available at https://github.com/wrld/Free-SurGS.
MeGA: Hybrid Mesh-Gaussian Head Avatar for High-Fidelity Rendering and Head Editing
Apr 29, 2024Creating high-fidelity head avatars from multi-view videos is a core issue for many AR/VR applications. However, existing methods usually struggle to obtain high-quality renderings for all different head components simultaneously since they use one single representation to model components with drastically different characteristics (e.g., skin vs. hair). In this paper, we propose a Hybrid Mesh-Gaussian Head Avatar (MeGA) that models different head components with more suitable representations. Specifically, we select an enhanced FLAME mesh as our facial representation and predict a UV displacement map to provide per-vertex offsets for improved personalized geometric details. To achieve photorealistic renderings, we obtain facial colors using deferred neural rendering and disentangle neural textures into three meaningful parts. For hair modeling, we first build a static canonical hair using 3D Gaussian Splatting. A rigid transformation and an MLP-based deformation field are further applied to handle complex dynamic expressions. Combined with our occlusion-aware blending, MeGA generates higher-fidelity renderings for the whole head and naturally supports more downstream tasks. Experiments on the NeRSemble dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods and supporting various editing functionalities, including hairstyle alteration and texture editing.
Advances in 3D Generation: A Survey
Jan 31, 2024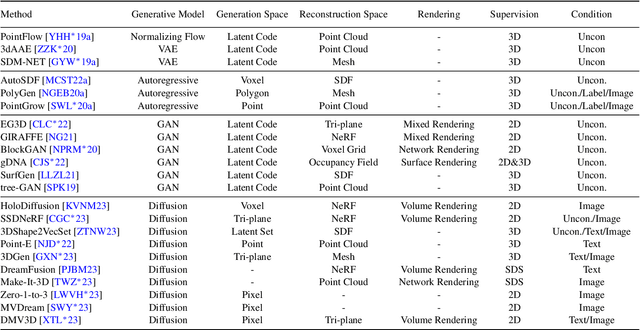
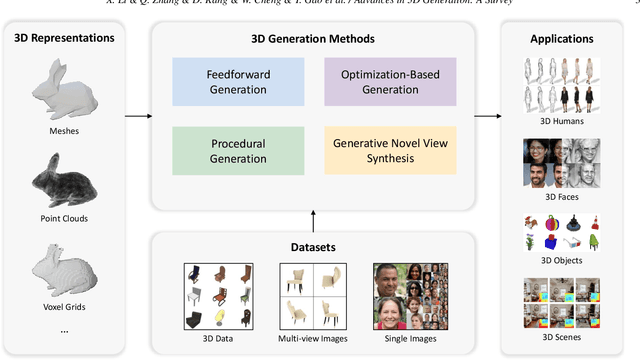
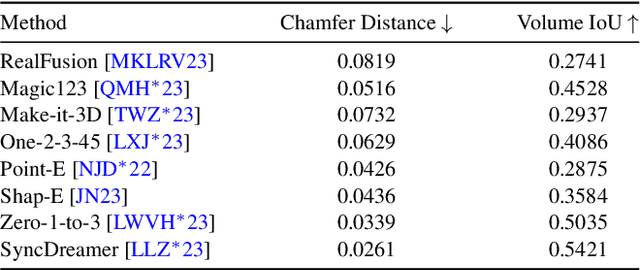
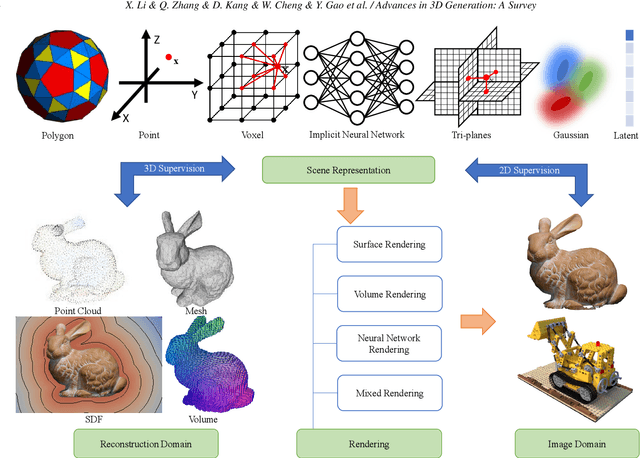
Generating 3D models lies at the core of computer graphics and has been the focus of decades of research. With the emergence of advanced neural representations and generative models, the field of 3D content generation is developing rapidly, enabling the creation of increasingly high-quality and diverse 3D models. The rapid growth of this field makes it difficult to stay abreast of all recent developments. In this survey, we aim to introduce the fundamental methodologies of 3D generation methods and establish a structured roadmap, encompassing 3D representation, generation methods, datasets, and corresponding applications. Specifically, we introduce the 3D representations that serve as the backbone for 3D generation. Furthermore, we provide a comprehensive overview of the rapidly growing literature on generation methods, categorized by the type of algorithmic paradigms, including feedforward generation, optimization-based generation, procedural generation, and generative novel view synthesis. Lastly, we discuss available datasets, applications, and open challenges. We hope this survey will help readers explore this exciting topic and foster further advancements in the field of 3D content generation.
TIP-Editor: An Accurate 3D Editor Following Both Text-Prompts And Image-Prompts
Jan 26, 2024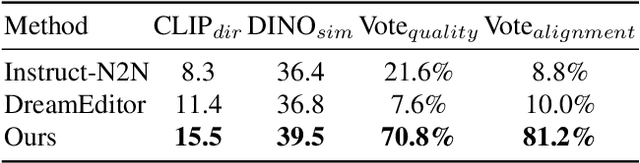


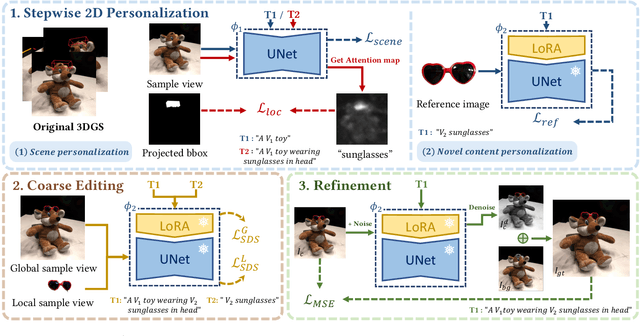
Text-driven 3D scene editing has gained significant attention owing to its convenience and user-friendliness. However, existing methods still lack accurate control of the specified appearance and location of the editing result due to the inherent limitations of the text description. To this end, we propose a 3D scene editing framework, TIPEditor, that accepts both text and image prompts and a 3D bounding box to specify the editing region. With the image prompt, users can conveniently specify the detailed appearance/style of the target content in complement to the text description, enabling accurate control of the appearance. Specifically, TIP-Editor employs a stepwise 2D personalization strategy to better learn the representation of the existing scene and the reference image, in which a localization loss is proposed to encourage correct object placement as specified by the bounding box. Additionally, TIPEditor utilizes explicit and flexible 3D Gaussian splatting as the 3D representation to facilitate local editing while keeping the background unchanged. Extensive experiments have demonstrated that TIP-Editor conducts accurate editing following the text and image prompts in the specified bounding box region, consistently outperforming the baselines in editing quality, and the alignment to the prompts, qualitatively and quantitatively.