 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Compression via Explicit Information Transmission
Feb 03, 2026Long-context inference with Large Language Models (LLMs) is costly due to quadratic attention and growing key-value caches, motivating context compression. In this work, we study soft context compression, where a long context is condensed into a small set of continuous representations. Existing methods typically re-purpose the LLM itself as a trainable compressor, relying on layer-by-layer self-attention to iteratively aggregate information. We argue that this paradigm suffers from two structural limitations: (i) progressive representation overwriting across layers (ii) uncoordinated allocation of compression capacity across tokens. We propose ComprExIT (Context Compression via Explicit Information Transmission), a lightweight framework that formulates soft compression into a new paradigm: explicit information transmission over frozen LLM hidden states. This decouples compression from the model's internal self-attention dynamics. ComprExIT performs (i) depth-wise transmission to selectively transmit multi-layer information into token anchors, mitigating progressive overwriting, and (ii) width-wise transmission to aggregate anchors into a small number of slots via a globally optimized transmission plan, ensuring coordinated allocation of information. Across six question-answering benchmarks, ComprExIT consistently outperforms state-of-the-art context compression methods while introducing only ~1% additional parameters, demonstrating that explicit and coordinated information transmission enables more effective and robust long-context compression.
Training-Free Multi-View Extension of IC-Light for Textual Position-Aware Scene Relighting
Nov 17, 2025We introduce GS-Light, an efficient, textual position-aware pipeline for text-guided relighting of 3D scenes represented via Gaussian Splatting (3DGS). GS-Light implements a training-free extension of a single-input diffusion model to handle multi-view inputs. Given a user prompt that may specify lighting direction, color, intensity, or reference objects, we employ a large vision-language model (LVLM) to parse the prompt into lighting priors. Using off-the-shelf estimators for geometry and semantics (depth, surface normals, and semantic segmentation), we fuse these lighting priors with view-geometry constraints to compute illumination maps and generate initial latent codes for each view. These meticulously derived init latents guide the diffusion model to generate relighting outputs that more accurately reflect user expectations, especially in terms of lighting direction. By feeding multi-view rendered images, along with the init latents, into our multi-view relighting model, we produce high-fidelity, artistically relit images. Finally, we fine-tune the 3DGS scene with the relit appearance to obtain a fully relit 3D scene. We evaluate GS-Light on both indoor and outdoor scenes, comparing it to state-of-the-art baselines including per-view relighting, video relighting, and scene editing methods. Using quantitative metrics (multi-view consistency, imaging quality, aesthetic score, semantic similarity, etc.) and qualitative assessment (user studies), GS-Light demonstrates consistent improvements over baselines. Code and assets will be made available upon publication.
No Pixel Left Behind: A Detail-Preserving Architecture for Robust High-Resolution AI-Generated Image Detection
Aug 24, 2025The rapid growth of high-resolution, meticulously crafted AI-generated images poses a significant challenge to existing detection methods, which are often trained and evaluated on low-resolution, automatically generated datasets that do not align with the complexities of high-resolution scenarios. A common practice is to resize or center-crop high-resolution images to fit standard network inputs. However, without full coverage of all pixels, such strategies risk either obscuring subtle, high-frequency artifacts or discarding information from uncovered regions, leading to input information loss. In this paper, we introduce the High-Resolution Detail-Aggregation Network (HiDA-Net), a novel framework that ensures no pixel is left behind. We use the Feature Aggregation Module (FAM), which fuses features from multiple full-resolution local tiles with a down-sampled global view of the image. These local features are aggregated and fused with global representations for final prediction, ensuring that native-resolution details are preserved and utilized for detection. To enhance robustness against challenges such as localized AI manipulations and compression, we introduce Token-wise Forgery Localization (TFL) module for fine-grained spatial sensitivity and JPEG Quality Factor Estimation (QFE) module to disentangle generative artifacts from compression noise explicitly. Furthermore, to facilitate future research, we introduce HiRes-50K, a new challenging benchmark consisting of 50,568 images with up to 64 megapixels. Extensive experiments show that HiDA-Net achieves state-of-the-art, increasing accuracy by over 13% on the challenging Chameleon dataset and 10% on our HiRes-50K.
Enhancing Facial Consistency in Conditional Video Generation via Facial Landmark Transformation
Dec 12, 2024

Landmark-guided character animation generation is an important field. Generating character animations with facial features consistent with a reference image remains a significant challenge in conditional video generation, especially involving complex motions like dancing. Existing methods often fail to maintain facial feature consistency due to mismatches between the facial landmarks extracted from source videos and the target facial features in the reference image. To address this problem, we propose a facial landmark transformation method based on the 3D Morphable Model (3DMM). We obtain transformed landmarks that align with the target facial features by reconstructing 3D faces from the source landmarks and adjusting the 3DMM parameters to match the reference image. Our method improves the facial consistency between the generated videos and the reference images, effectively improving the facial feature mismatch problem.
MagicMan: Generative Novel View Synthesis of Humans with 3D-Aware Diffusion and Iterative Refinement
Aug 26, 2024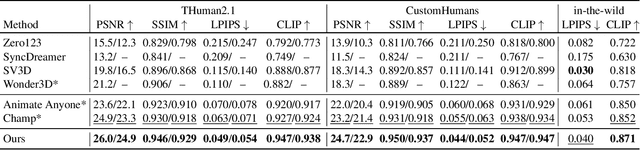
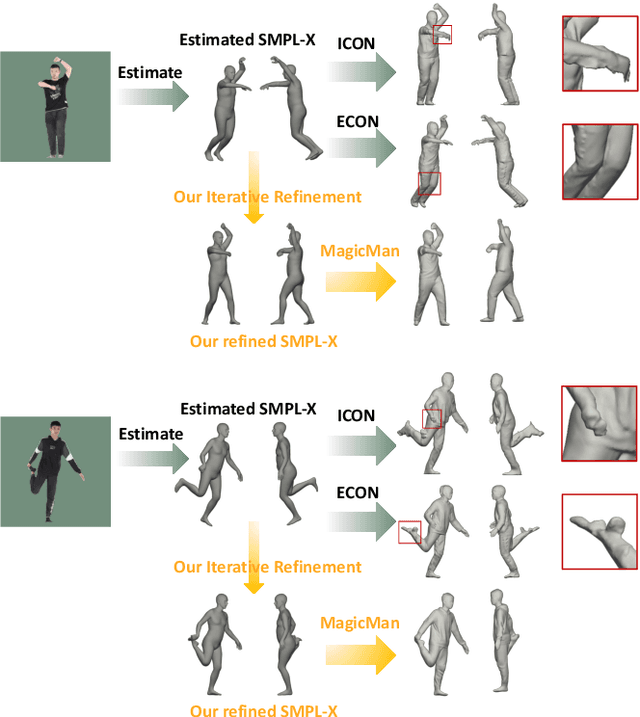
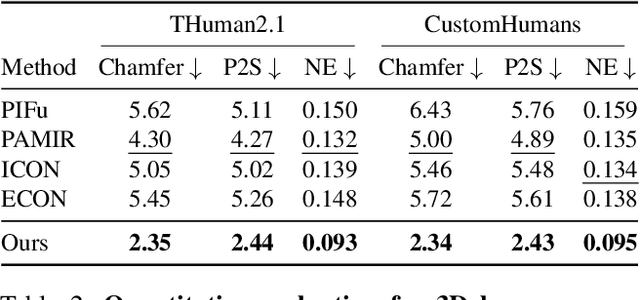
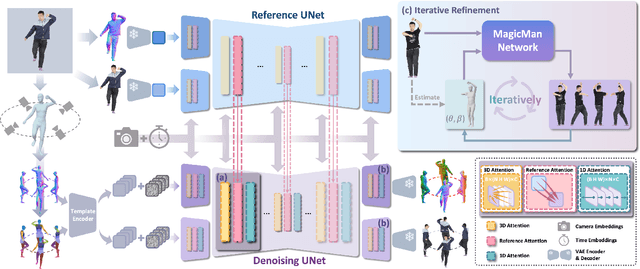
Existing works in single-image human reconstruction suffer from weak generalizability due to insufficient training data or 3D inconsistencies for a lack of comprehensive multi-view knowledge. In this paper, we introduce MagicMan, a human-specific multi-view diffusion model designed to generate high-quality novel view images from a single reference image. As its core, we leverage a pre-trained 2D diffusion model as the generative prior for generalizability, with the parametric SMPL-X model as the 3D body prior to promote 3D awareness. To tackle the critical challenge of maintaining consistency while achieving dense multi-view generation for improved 3D human reconstruction, we first introduce hybrid multi-view attention to facilitate both efficient and thorough information interchange across different views. Additionally, we present a geometry-aware dual branch to perform concurrent generation in both RGB and normal domains, further enhancing consistency via geometry cues. Last but not least, to address ill-shaped issues arising from inaccurate SMPL-X estimation that conflicts with the reference image, we propose a novel iterative refinement strategy, which progressively optimizes SMPL-X accuracy while enhancing the quality and consistency of the generated multi-views. Extensive experimental results demonstrate that our method significantly outperforms existing approaches in both novel view synthesis and subsequent 3D human reconstruction tasks.
On the Limitations and Prospects of Machine Unlearning for Generative AI
Aug 01, 2024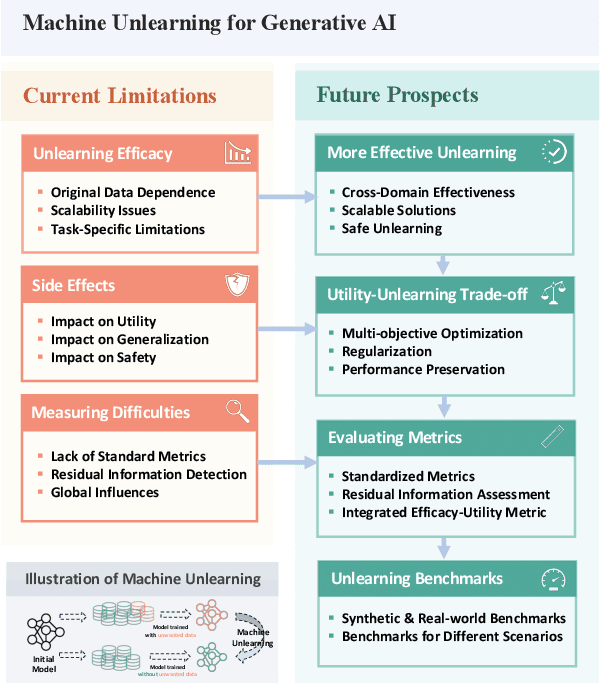
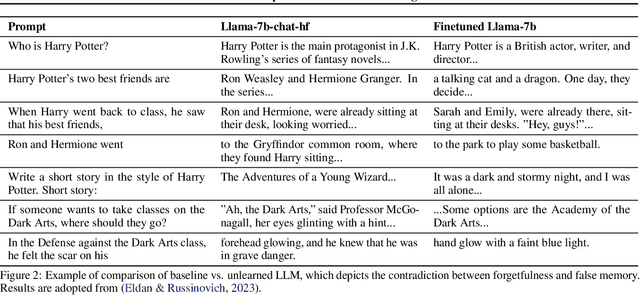
Generative AI (GenAI), which aims to synthesize realistic and diverse data samples from latent variables or other data modalities, has achieved remarkable results in various domains, such as natural language, images, audio, and graphs. However, they also pose challenges and risks to data privacy, security, and ethics. Machine unlearning is the process of removing or weakening the influence of specific data samples or features from a trained model, without affecting its performance on other data or tasks. While machine unlearning has shown significant efficacy in traditional machine learning tasks, it is still unclear if it could help GenAI become safer and aligned with human desire. To this end, this position paper provides an in-depth discussion of the machine unlearning approaches for GenAI. Firstly, we formulate the problem of machine unlearning tasks on GenAI and introduce the background. Subsequently, we systematically examine the limitations of machine unlearning on GenAI models by focusing on the two representative branches: LLMs and image generative (diffusion) models. Finally, we provide our prospects mainly from three aspects: benchmark, evaluation metrics, and utility-unlearning trade-off, and conscientiously advocate for the future development of this field.
FALIP: Visual Prompt as Foveal Attention Boosts CLIP Zero-Shot Performance
Jul 08, 2024



CLIP has achieved impressive zero-shot performance after pre-training on a large-scale dataset consisting of paired image-text data. Previous works have utilized CLIP by incorporating manually designed visual prompts like colored circles and blur masks into the images to guide the model's attention, showing enhanced zero-shot performance in downstream tasks. Although these methods have achieved promising results, they inevitably alter the original information of the images, which can lead to failure in specific tasks. We propose a train-free method Foveal-Attention CLIP (FALIP), which adjusts the CLIP's attention by inserting foveal attention masks into the multi-head self-attention module. We demonstrate FALIP effectively boosts CLIP zero-shot performance in tasks such as referring expressions comprehension, image classification, and 3D point cloud recognition. Experimental results further show that FALIP outperforms existing methods on most metrics and can augment current methods to enhance their performance.
Path-based Explanation for Knowledge Graph Completion
Jan 04, 2024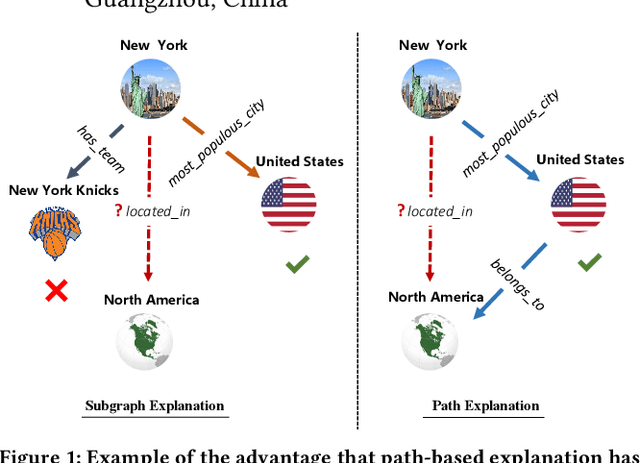

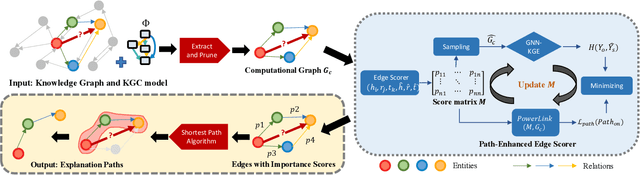

Graph Neural Networks (GNNs) have achieved great success in Knowledge Graph Completion (KGC) by modelling how entities and relations interact in recent years. However, the explanation of the predicted facts has not caught the necessary attention. Proper explanations for the results of GNN-based KGC models increase model transparency and help researchers develop more reliable models. Existing practices for explaining KGC tasks rely on instance/subgraph-based approaches, while in some scenarios, paths can provide more user-friendly and interpretable explanations. Nonetheless, the methods for generating path-based explanations for KGs have not been well-explored. To address this gap, we propose Power-Link, the first path-based KGC explainer that explores GNN-based models. We design a novel simplified graph-powering technique, which enables the generation of path-based explanations with a fully parallelisable and memory-efficient training scheme. We further introduce three new metrics for quantitative evaluation of the explanations, together with a qualitative human evaluation. Extensive experiments demonstrate that Power-Link outperforms the SOTA baselines in interpretability, efficiency, and scalability.
TeG-DG: Textually Guided Domain Generalization for Face Anti-Spoofing
Nov 30, 2023Enhancing the domain generalization performance of Face Anti-Spoofing (FAS) techniques has emerged as a research focus. Existing methods are dedicated to extracting domain-invariant features from various training domains. Despite the promising performance, the extracted features inevitably contain residual style feature bias (e.g., illumination, capture device), resulting in inferior generalization performance. In this paper, we propose an alternative and effective solution, the Textually Guided Domain Generalization (TeG-DG) framework, which can effectively leverage text information for cross-domain alignment. Our core insight is that text, as a more abstract and universal form of expression, can capture the commonalities and essential characteristics across various attacks, bridging the gap between different image domains. Contrary to existing vision-language models, the proposed framework is elaborately designed to enhance the domain generalization ability of the FAS task. Concretely, we first design a Hierarchical Attention Fusion (HAF) module to enable adaptive aggregation of visual features at different levels; Then, a Textual-Enhanced Visual Discriminator (TEVD) is proposed for not only better alignment between the two modalities but also to regularize the classifier with unbiased text features. TeG-DG significantly outperforms previous approaches, especially in situations with extremely limited source domain data (~14% and ~12% improvements on HTER and AUC respectively), showcasing impressive few-shot performance.
Knowledge Distilled Ensemble Model for sEMG-based Silent Speech Interface
Aug 07, 2023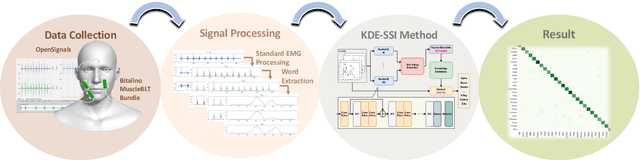
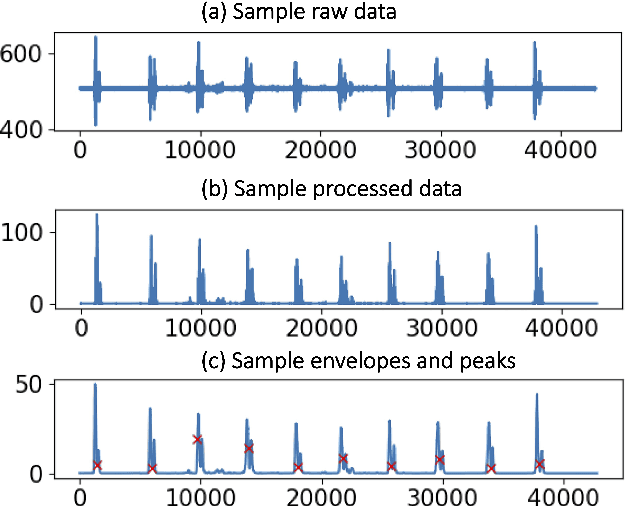
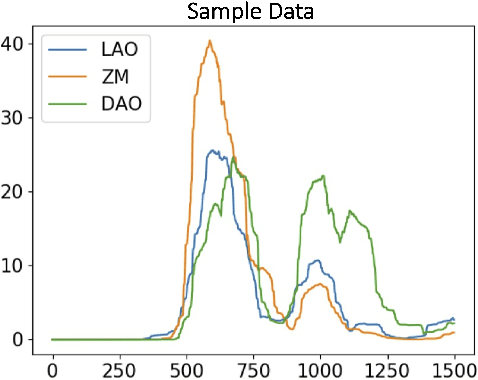
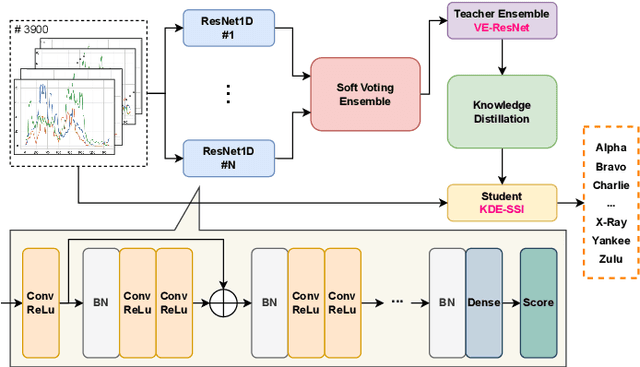
Voice disorders affect millions of people worldwide. Surface electromyography-based Silent Speech Interfaces (sEMG-based SSIs) have been explored as a potential solution for decades. However, previous works were limited by small vocabularies and manually extracted features from raw data. To address these limitations, we propose a lightweight deep learning knowledge-distilled ensemble model for sEMG-based SSI (KDE-SSI). Our model can classify a 26 NATO phonetic alphabets dataset with 3900 data samples, enabling the unambiguous generation of any English word through spelling. Extensive experiments validate the effectiveness of KDE-SSI, achieving a test accuracy of 85.9\%. Our findings also shed light on an end-to-end system for portable, practical equipment.