 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limitations and Prospects of Machine Unlearning for Generative AI
Paper and Code
Aug 01, 2024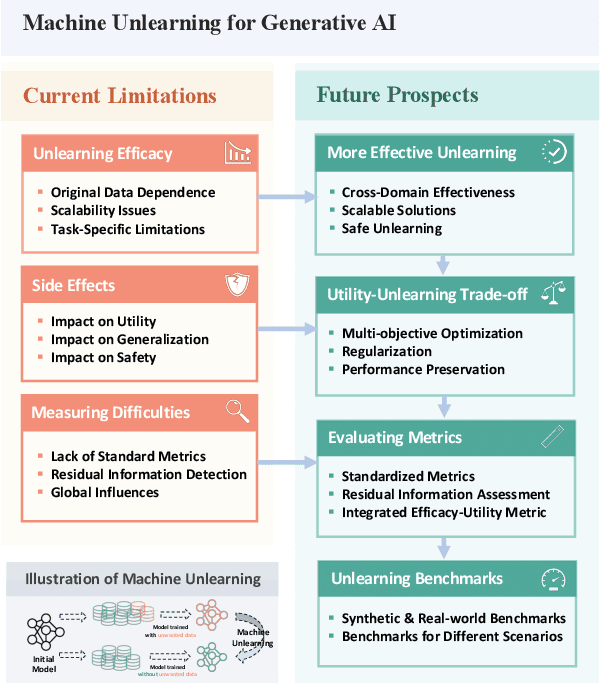
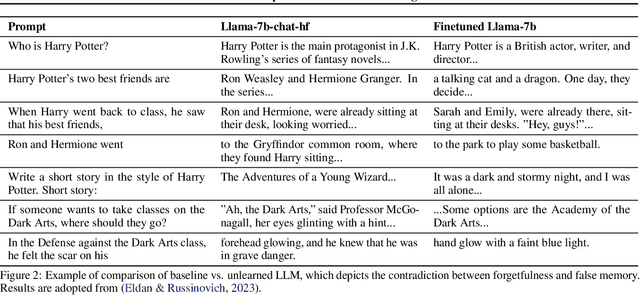
Generative AI (GenAI), which aims to synthesize realistic and diverse data samples from latent variables or other data modalities, has achieved remarkable results in various domains, such as natural language, images, audio, and graphs. However, they also pose challenges and risks to data privacy, security, and ethics. Machine unlearning is the process of removing or weakening the influence of specific data samples or features from a trained model, without affecting its performance on other data or tasks. While machine unlearning has shown significant efficacy in traditional machine learning tasks, it is still unclear if it could help GenAI become safer and aligned with human desire. To this end, this position paper provides an in-depth discussion of the machine unlearning approaches for GenAI. Firstly, we formulate the problem of machine unlearning tasks on GenAI and introduce the background. Subsequently, we systematically examine the limitations of machine unlearning on GenAI models by focusing on the two representative branches: LLMs and image generative (diffusion) models. Finally, we provide our prospects mainly from three aspects: benchmark, evaluation metrics, and utility-unlearning trade-off, and conscientiously advocate for the future development of this field.