 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Limitations and Prospects of Machine Unlearning for Generative AI
Aug 01, 2024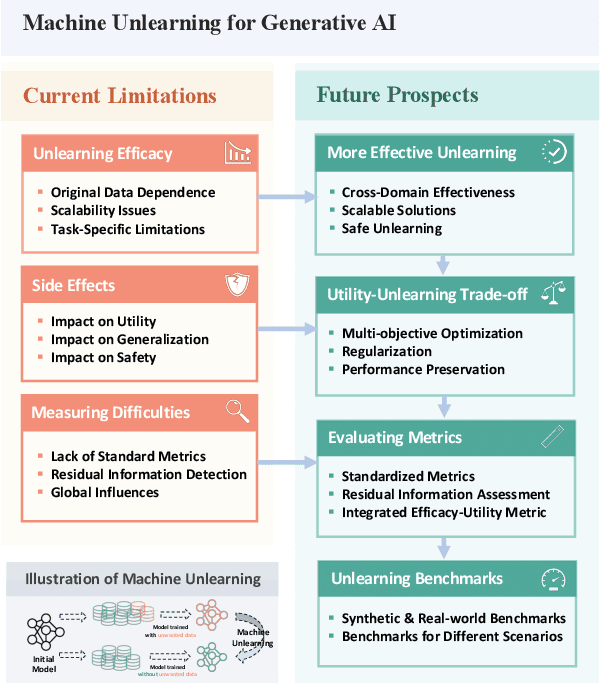
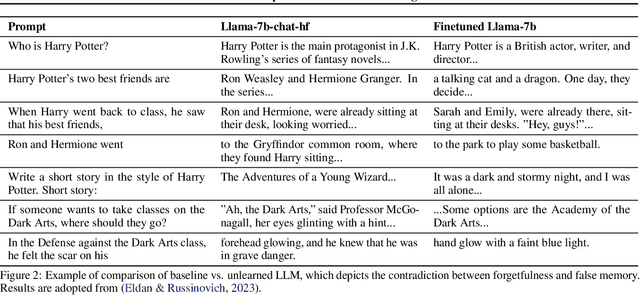
Generative AI (GenAI), which aims to synthesize realistic and diverse data samples from latent variables or other data modalities, has achieved remarkable results in various domains, such as natural language, images, audio, and graphs. However, they also pose challenges and risks to data privacy, security, and ethics. Machine unlearning is the process of removing or weakening the influence of specific data samples or features from a trained model, without affecting its performance on other data or tasks. While machine unlearning has shown significant efficacy in traditional machine learning tasks, it is still unclear if it could help GenAI become safer and aligned with human desire. To this end, this position paper provides an in-depth discussion of the machine unlearning approaches for GenAI. Firstly, we formulate the problem of machine unlearning tasks on GenAI and introduce the background. Subsequently, we systematically examine the limitations of machine unlearning on GenAI models by focusing on the two representative branches: LLMs and image generative (diffusion) models. Finally, we provide our prospects mainly from three aspects: benchmark, evaluation metrics, and utility-unlearning trade-off, and conscientiously advocate for the future development of this field.
Unlearning Concepts in Diffusion Model via Concept Domain Correction and Concept Preserving Gradient
May 24, 2024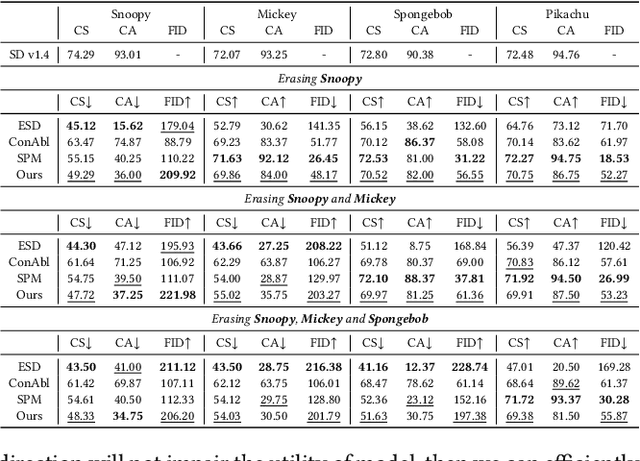
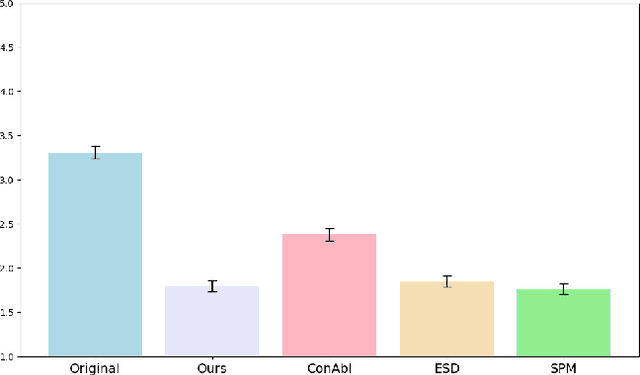

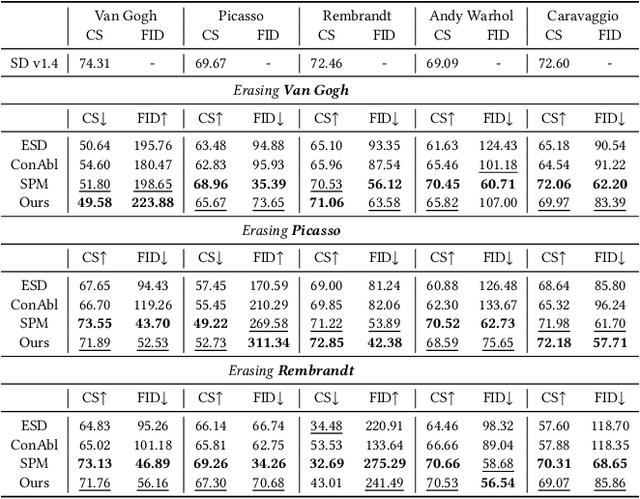
Current text-to-image diffusion models have achieved groundbreaking results in image generation tasks. However, the unavoidable inclusion of sensitive information during pre-training introduces significant risks such as copyright infringement and privacy violations in the generated images. Machine Unlearning (MU) provides a effective way to the sensitive concepts captured by the model, has been shown to be a promising approach to addressing these issues. Nonetheless, existing MU methods for concept erasure encounter two primary bottlenecks: 1) generalization issues, where concept erasure is effective only for the data within the unlearn set, and prompts outside the unlearn set often still result in the generation of sensitive concepts; and 2) utility drop, where erasing target concepts significantly degrades the model's performance. To this end, this paper first proposes a concept domain correction framework for unlearning concepts in diffusion models. By aligning the output domains of sensitive concepts and anchor concepts through adversarial training, we enhance the generalizability of the unlearning results. Secondly, we devise a concept-preserving scheme based on gradient surgery. This approach alleviates the parts of the unlearning gradient that contradict the relearning gradient, ensuring that the process of unlearning minimally disrupts the model's performance. Finally, extensive experiments validate the effectiveness of our model, demonstrating our method's capability to address the challenges of concept unlearning in diffusion models while preserving model utility.
Online Continual Adaptation with Active Self-Training
Jun 11, 2021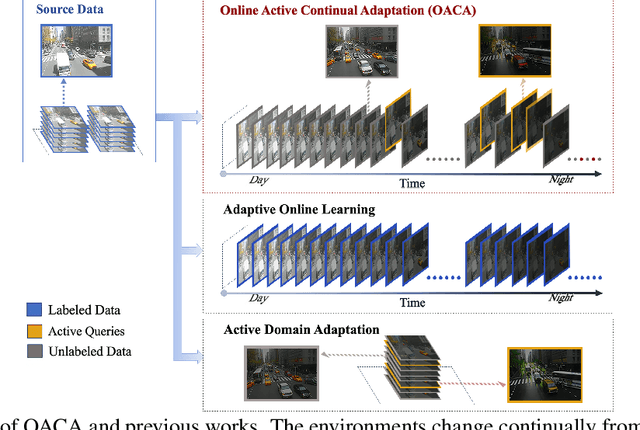
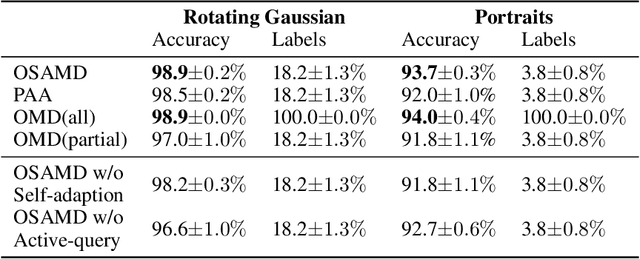

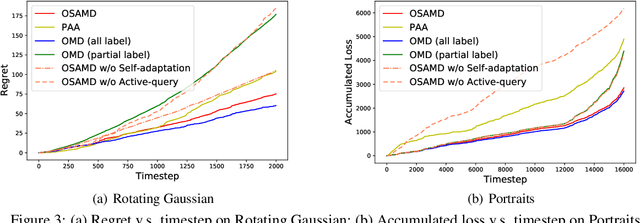
Models trained with offline data often suffer from continual distribution shifts and expensive labeling in changing environments. This calls for a new online learning paradigm where the learner can continually adapt to changing environments with limited labels. In this paper, we propose a new online setting -- Online Active Continual Adaptation, where the learner aims to continually adapt to changing distributions using both unlabeled samples and active queries of limited labels. To this end, we propose Online Self-Adaptive Mirror Descent (OSAMD), which adopts an online teacher-student structure to enable online self-training from unlabeled data, and a margin-based criterion that decides whether to query the labels to track changing distributions. Theoretically, we show that, in the separable case, OSAMD has an $O({T}^{1/2})$ dynamic regret bound under mild assumptions, which is even tighter than the lower bound $\Omega(T^{2/3})$ of traditional online learning with full labels. In the general case, we show a regret bound of $O({\alpha^*}^{1/3} {T}^{2/3} + \alpha^* T)$, where $\alpha^*$ denotes the separability of domains and is usually small. Our theoretical results show that OSAMD can fast adapt to changing environments with active queries. Empirically, we demonstrate that OSAMD achieves favorable regrets under changing environments with limited labels on both simulated and real-world data, which corroborates our theoretical findings.