 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Query-Specific Rubrics from Human Preferences for DeepResearch Report Generation
Feb 03, 2026Nowadays, training and evaluating DeepResearch-generated reports remain challenging due to the lack of verifiable reward signals. Accordingly, rubric-based evaluation has become a common practice. However, existing approaches either rely on coarse, pre-defined rubrics that lack sufficient granularity, or depend on manually constructed query-specific rubrics that are costly and difficult to scale. In this paper, we propose a pipeline to train human-preference-aligned query-specific rubric generators tailored for DeepResearch report generation. We first construct a dataset of DeepResearch-style queries annotated with human preferences over paired reports, and train rubric generators via reinforcement learning with a hybrid reward combining human preference supervision and LLM-based rubric evaluation. To better handle long-horizon reasoning, we further introduce a Multi-agent Markov-state (MaMs) workflow for report generation. We empirically show that our proposed rubric generators deliver more discriminative and better human-aligned supervision than existing rubric design strategies. Moreover, when integrated into the MaMs training framework, DeepResearch systems equipped with our rubric generators consistently outperform all open-source baselines on the DeepResearch Bench and achieve performance comparable to that of leading closed-source models.
WED-Net: A Weather-Effect Disentanglement Network with Causal Augmentation for Urban Flow Prediction
Jan 30, 2026Urban spatio-temporal prediction under extreme conditions (e.g., heavy rain) is challenging due to event rarity and dynamics. Existing data-driven approaches that incorporate weather as auxiliary input often rely on coarse-grained descriptors and lack dedicated mechanisms to capture fine-grained spatio-temporal effects. Although recent methods adopt causal techniques to improve out-of-distribution generalization, they typically overlook temporal dynamics or depend on fixed confounder stratification. To address these limitations, we propose WED-Net (Weather-Effect Disentanglement Network), a dual-branch Transformer architecture that separates intrinsic and weather-induced traffic patterns via self- and cross-attention, enhanced with memory banks and fused through adaptive gating. To further promote disentanglement, we introduce a discriminator that explicitly distinguishes weather conditions. Additionally, we design a causal data augmentation strategy that perturbs non-causal parts while preserving causal structures, enabling improved generalization under rare scenarios. Experiments on taxi-flow datasets from three cities demonstrate that WED-Net delivers robust performance under extreme weather conditions, highlighting its potential to support safer mobility, highlighting its potential to support safer mobility, disaster preparedness, and urban resilience in real-world settings. The code is publicly available at https://github.com/HQ-LV/WED-Net.
Intelli-Planner: Towards Customized Urban Planning via Large Language Model Empowered Reinforcement Learning
Jan 29, 2026Effective urban planning is crucial for enhancing residents' quality of life and ensuring societal stability, playing a pivotal role in the sustainable development of cities. Current planning methods heavily rely on human experts, which are time-consuming and labor-intensive, or utilize deep learning algorithms, often limiting stakeholder involvement. To bridge these gaps, we propose Intelli-Planner, a novel framework integrating Deep Reinforcement Learning (DRL) with large language models (LLMs) to facilitate participatory and customized planning scheme generation. Intelli-Planner utilizes demographic, geographic data, and planning preferences to determine high-level planning requirements and demands for each functional type. During training, a knowledge enhancement module is employed to enhance the decision-making capability of the policy network. Additionally, we establish a multi-dimensional evaluation system and employ LLM-based stakeholders for satisfaction scoring. Experimental validation across diverse urban settings shows that Intelli-Planner surpasses traditional baselines and achieves comparable performance to state-of-the-art DRL-based methods in objective metrics, while enhancing stakeholder satisfaction and convergence speed. These findings underscore the effectiveness and superiority of our framework, highlighting the potential for integrating the latest advancements in LLMs with DRL approaches to revolutionize tasks related to functional areas planning.
Why not Collaborative Filtering in Dual View? Bridging Sparse and Dense Models
Jan 14, 2026Collaborative Filtering (CF) remains the cornerstone of modern recommender systems, with dense embedding--based methods dominating current practice. However, these approaches suffer from a critical limitation: our theoretical analysis reveals a fundamental signal-to-noise ratio (SNR) ceiling when modeling unpopular items, where parameter-based dense models experience diminishing SNR under severe data sparsity. To overcome this bottleneck, we propose SaD (Sparse and Dense), a unified framework that integrates the semantic expressiveness of dense embeddings with the structural reliability of sparse interaction patterns. We theoretically show that aligning these dual views yields a strictly superior global SNR. Concretely, SaD introduces a lightweight bidirectional alignment mechanism: the dense view enriches the sparse view by injecting semantic correlations, while the sparse view regularizes the dense model through explicit structural signals. Extensive experiments demonstrate that, under this dual-view alignment, even a simple matrix factorization--style dense model can achieve state-of-the-art performance. Moreover, SaD is plug-and-play and can be seamlessly applied to a wide range of existing recommender models, highlighting the enduring power of collaborative filtering when leveraged from dual perspectives. Further evaluations on real-world benchmarks show that SaD consistently outperforms strong baselines, ranking first on the BarsMatch leaderboard. The code is publicly available at https://github.com/harris26-G/SaD.
WeDLM: Reconciling Diffusion Language Models with Standard Causal Attention for Fast Inference
Dec 28, 2025Autoregressive (AR) generation is the standard decoding paradigm for Large Language Models (LLMs), but its token-by-token nature limits parallelism at inference time. Diffusion Language Models (DLLMs) offer parallel decoding by recovering multiple masked tokens per step; however, in practice they often fail to translate this parallelism into deployment speed gains over optimized AR engines (e.g., vLLM). A key reason is that many DLLMs rely on bidirectional attention, which breaks standard prefix KV caching and forces repeated contextualization, undermining efficiency. We propose WeDLM, a diffusion decoding framework built entirely on standard causal attention to make parallel generation prefix-cache friendly. The core idea is to let each masked position condition on all currently observed tokens while keeping a strict causal mask, achieved by Topological Reordering that moves observed tokens to the physical prefix while preserving their logical positions. Building on this property, we introduce a streaming decoding procedure that continuously commits confident tokens into a growing left-to-right prefix and maintains a fixed parallel workload, avoiding the stop-and-wait behavior common in block diffusion methods. Experiments show that WeDLM preserves the quality of strong AR backbones while delivering substantial speedups, approaching 3x on challenging reasoning benchmarks and up to 10x in low-entropy generation regimes; critically, our comparisons are against AR baselines served by vLLM under matched deployment settings, demonstrating that diffusion-style decoding can outperform an optimized AR engine in practice.
The Complete Anatomy of the Madden-Julian Oscillation Revealed by Artificial Intelligence
Dec 14, 2025Accurately defining the life cycle of the Madden-Julian Oscillation (MJO), the dominant mode of intraseasonal climate variability, remains a foundational challenge due to its propagating nature. The established linear-projection method (RMM index) often conflates mathematical artifacts with physical states, while direct clustering in raw data space is confounded by a "propagation penalty." Here, we introduce an "AI-for-theory" paradigm to objectively discover the MJO's intrinsic structure. We develop a deep learning model, PhysAnchor-MJO-AE, to learn a latent representation where vector distance corresponds to physical-feature similarity, enabling objective clustering of MJO dynamical states. Clustering these "MJO fingerprints" reveals the first complete, six-phase anatomical map of its life cycle. This taxonomy refines and critically completes the classical view by objectively isolating two long-hypothesized transitional phases: organizational growth over the Indian Ocean and the northward shift over the Philippine Sea. Derived from this anatomy, we construct a new physics-coherent monitoring framework that decouples location and intensity diagnostics. This framework reduces the rates of spurious propagation and convective misplacement by over an order of magnitude compared to the classical index. Our work transforms AI from a forecasting tool into a discovery microscope, establishing a reproducible template for extracting fundamental dynamical constructs from complex systems.
Advancing Ocean State Estimation with efficient and scalable AI
Nov 08, 2025Accurate and efficient global ocean state estimation remains a grand challenge for Earth system science, hindered by the dual bottlenecks of computational scalability and degraded data fidelity in traditional data assimilation (DA) and deep learning (DL) approaches. Here we present an AI-driven Data Assimilation Framework for Ocean (ADAF-Ocean) that directly assimilates multi-source and multi-scale observations, ranging from sparse in-situ measurements to 4 km satellite swaths, without any interpolation or data thinning. Inspired by Neural Processes, ADAF-Ocean learns a continuous mapping from heterogeneous inputs to ocean states, preserving native data fidelity. Through AI-driven super-resolution, it reconstructs 0.25$^\circ$ mesoscale dynamics from coarse 1$^\circ$ fields, which ensures both efficiency and scalability, with just 3.7\% more parameters than the 1$^\circ$ configuration. When coupled with a DL forecasting system, ADAF-Ocean extends global forecast skill by up to 20 days compared to baselines without assimilation. This framework establishes a computationally viable and scientifically rigorous pathway toward real-time, high-resolution Earth system monitoring.
MRMR: A Realistic and Expert-Level Multidisciplinary Benchmark for Reasoning-Intensive Multimodal Retrieval
Oct 10, 2025We introduce MRMR, the first expert-level multidisciplinary multimodal retrieval benchmark requiring intensive reasoning. MRMR contains 1,502 queries spanning 23 domains, with positive documents carefully verified by human experts. Compared to prior benchmarks, MRMR introduces three key advancements. First, it challenges retrieval systems across diverse areas of expertise, enabling fine-grained model comparison across domains. Second, queries are reasoning-intensive, with images requiring deeper interpretation such as diagnosing microscopic slides. We further introduce Contradiction Retrieval, a novel task requiring models to identify conflicting concepts. Finally, queries and documents are constructed as image-text interleaved sequences. Unlike earlier benchmarks restricted to single images or unimodal documents, MRMR offers a realistic setting with multi-image queries and mixed-modality corpus documents. We conduct an extensive evaluation of 4 categories of multimodal retrieval systems and 14 frontier models on MRMR. The text embedding model Qwen3-Embedding with LLM-generated image captions achieves the highest performance, highlighting substantial room for improving multimodal retrieval models. Although latest multimodal models such as Ops-MM-Embedding perform competitively on expert-domain queries, they fall short on reasoning-intensive tasks. We believe that MRMR paves the way for advancing multimodal retrieval in more realistic and challenging scenarios.
StableToken: A Noise-Robust Semantic Speech Tokenizer for Resilient SpeechLLMs
Sep 26, 2025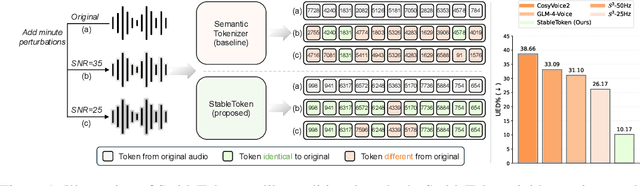
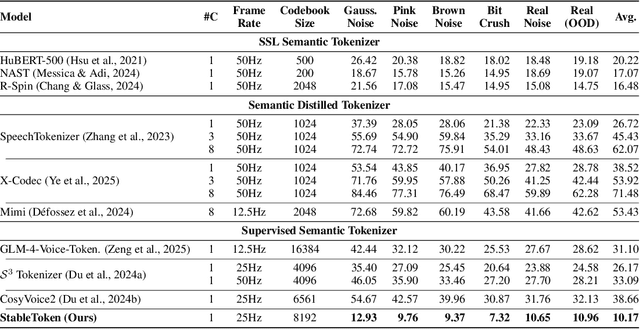
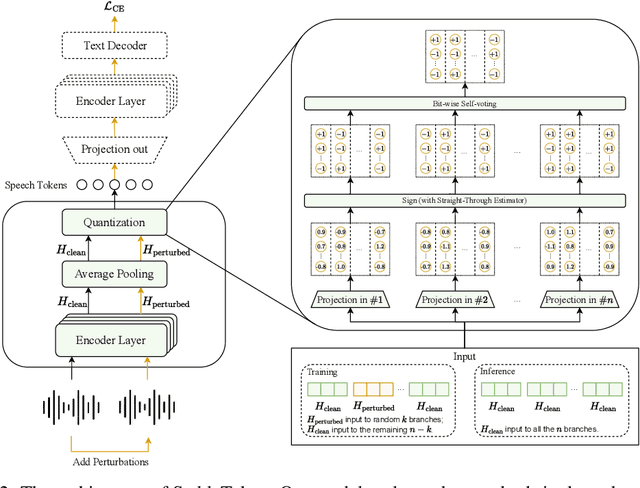

Prevalent semantic speech tokenizers, designed to capture linguistic content, are surprisingly fragile. We find they are not robust to meaning-irrelevant acoustic perturbations; even at high Signal-to-Noise Ratios (SNRs) where speech is perfectly intelligible, their output token sequences can change drastically, increasing the learning burden for downstream LLMs. This instability stems from two flaws: a brittle single-path quantization architecture and a distant training signal indifferent to intermediate token stability. To address this, we introduce StableToken, a tokenizer that achieves stability through a consensus-driven mechanism. Its multi-branch architecture processes audio in parallel, and these representations are merged via a powerful bit-wise voting mechanism to form a single, stable token sequence. StableToken sets a new state-of-the-art in token stability, drastically reducing Unit Edit Distance (UED) under diverse noise conditions. This foundational stability translates directly to downstream benefits, significantly improving the robustness of SpeechLLMs on a variety of tasks.
MotiveBench: How Far Are We From Human-Like Motivational Reasoning in Large Language Models?
Jun 16, 2025
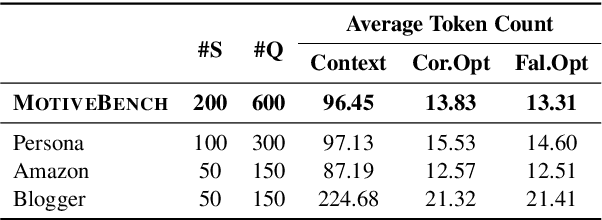
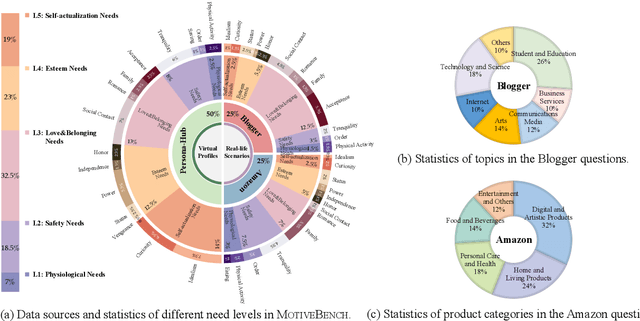
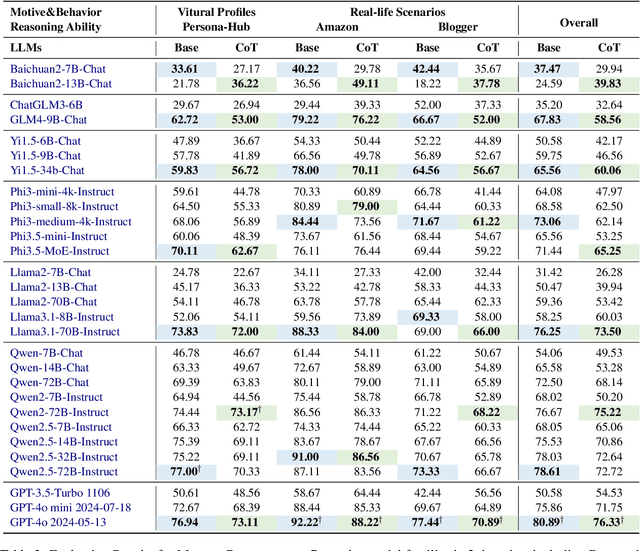
Large language models (LLMs) have been widely adopted as the core of agent frameworks in various scenarios, such as social simulations and AI companions. However, the extent to which they can replicate human-like motivations remains an underexplored question. Existing benchmarks are constrained by simplistic scenarios and the absence of character identities, resulting in an information asymmetry with real-world situations. To address this gap, we propose MotiveBench, which consists of 200 rich contextual scenarios and 600 reasoning tasks covering multiple levels of motivation. Using MotiveBench, we conduct extensive experiments on seven popular model families, comparing different scales and versions within each family. The results show that even the most advanced LLMs still fall short in achieving human-like motivational reasoning. Our analysis reveals key findings, including the difficulty LLMs face in reasoning about "love & belonging" motivations and their tendency toward excessive rationality and idealism. These insights highlight a promising direction for future research on the humanization of LLMs. The dataset, benchmark, and code are available at https://aka.ms/motivebench.