 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking the Reasoning Horizon in Entity Alignment Foundation Models
Jan 29, 2026Entity alignment (EA) is critical for knowledge graph (KG) fusion. Existing EA models lack transferability and are incapable of aligning unseen KGs without retraining. While using graph foundation models (GFMs) offer a solution, we find that directly adapting GFMs to EA remains largely ineffective. This stems from a critical "reasoning horizon gap": unlike link prediction in GFMs, EA necessitates capturing long-range dependencies across sparse and heterogeneous KG structuresTo address this challenge, we propose a EA foundation model driven by a parallel encoding strategy. We utilize seed EA pairs as local anchors to guide the information flow, initializing and encoding two parallel streams simultaneously. This facilitates anchor-conditioned message passing and significantly shortens the inference trajectory by leveraging local structural proximity instead of global search. Additionally, we incorporate a merged relation graph to model global dependencies and a learnable interaction module for precise matching. Extensive experiments verify the effectiveness of our framework, highlighting its strong generalizability to unseen KGs.
SafeThinker: Reasoning about Risk to Deepen Safety Beyond Shallow Alignment
Jan 23, 2026Despite the intrinsic risk-awareness of Large Language Models (LLMs), current defenses often result in shallow safety alignment, rendering models vulnerable to disguised attacks (e.g., prefilling) while degrading utility. To bridge this gap, we propose SafeThinker, an adaptive framework that dynamically allocates defensive resources via a lightweight gateway classifier. Based on the gateway's risk assessment, inputs are routed through three distinct mechanisms: (i) a Standardized Refusal Mechanism for explicit threats to maximize efficiency; (ii) a Safety-Aware Twin Expert (SATE) module to intercept deceptive attacks masquerading as benign queries; and (iii) a Distribution-Guided Think (DDGT) component that adaptively intervenes during uncertain generation. Experiments show that SafeThinker significantly lowers attack success rates across diverse jailbreak strategies without compromising utility, demonstrating that coordinating intrinsic judgment throughout the generation process effectively balances robustness and practicality.
KGFR: A Foundation Retriever for Generalized Knowledge Graph Question Answering
Nov 06, 2025Large language models (LLMs) excel at reasoning but struggle with knowledge-intensive questions due to limited context and parametric knowledge. However, existing methods that rely on finetuned LLMs or GNN retrievers are limited by dataset-specific tuning and scalability on large or unseen graphs. We propose the LLM-KGFR collaborative framework, where an LLM works with a structured retriever, the Knowledge Graph Foundation Retriever (KGFR). KGFR encodes relations using LLM-generated descriptions and initializes entities based on their roles in the question, enabling zero-shot generalization to unseen KGs. To handle large graphs efficiently, it employs Asymmetric Progressive Propagation (APP)- a stepwise expansion that selectively limits high-degree nodes while retaining informative paths. Through node-, edge-, and path-level interfaces, the LLM iteratively requests candidate answers, supporting facts, and reasoning paths, forming a controllable reasoning loop. Experiments demonstrate that LLM-KGFR achieves strong performance while maintaining scalability and generalization, providing a practical solution for KG-augmented reasoning.
Benchmarking Recommendation, Classification, and Tracing Based on Hugging Face Knowledge Graph
May 23, 2025The rapid growth of open source machine learning (ML) resources, such as models and datasets, has accelerated IR research. However, existing platforms like Hugging Face do not explicitly utilize structured representations, limiting advanced queries and analyses such as tracing model evolution and recommending relevant datasets. To fill the gap, we construct HuggingKG, the first large-scale knowledge graph built from the Hugging Face community for ML resource management. With 2.6 million nodes and 6.2 million edges, HuggingKG captures domain-specific relations and rich textual attributes. It enables us to further present HuggingBench, a multi-task benchmark with three novel test collections for IR tasks including resource recommendation, classification, and tracing. Our experiments reveal unique characteristics of HuggingKG and the derived tasks. Both resources are publicly available, expected to advance research in open source resource sharing and management.
* 10 pages, 5 figures. Accepted at SIGIR 2025
A Prompt-Based Knowledge Graph Foundation Model for Universal In-Context Reasoning
Oct 16, 2024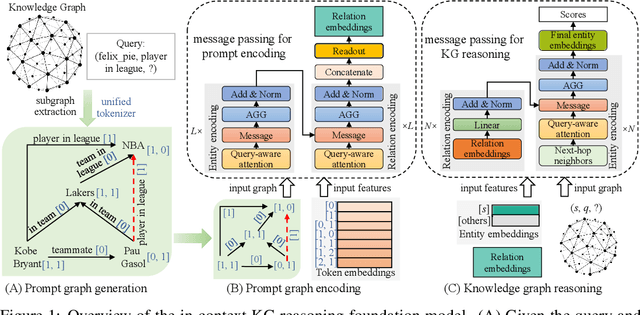
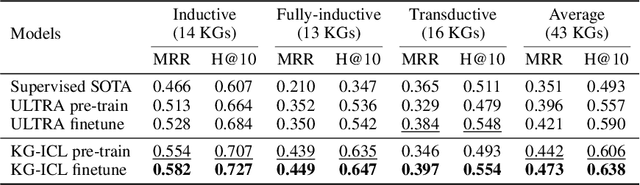
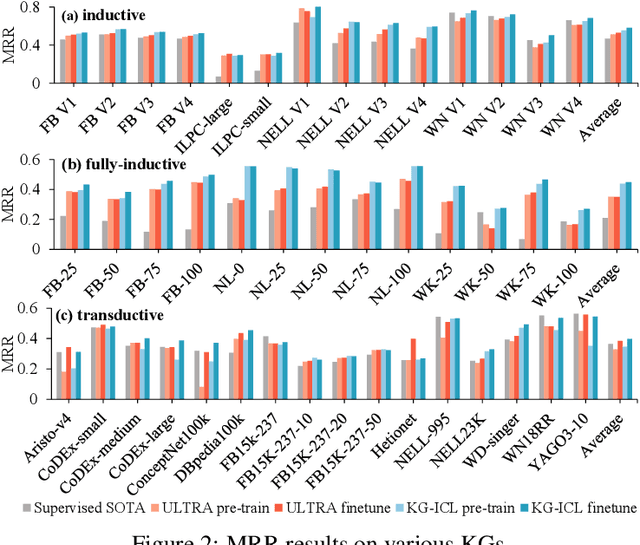
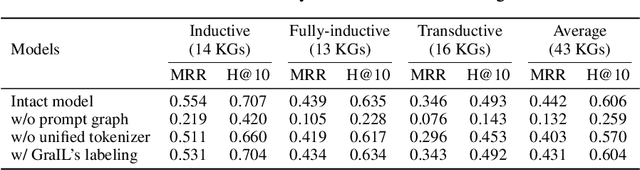
Extensive knowledge graphs (KGs) have been constructed to facilitate knowledge-driven tasks across various scenarios. However, existing work usually develops separate reasoning models for different KGs, lacking the ability to generalize and transfer knowledge across diverse KGs and reasoning settings. In this paper, we propose a prompt-based KG foundation model via in-context learning, namely KG-ICL, to achieve a universal reasoning ability. Specifically, we introduce a prompt graph centered with a query-related example fact as context to understand the query relation. To encode prompt graphs with the generalization ability to unseen entities and relations in queries, we first propose a unified tokenizer that maps entities and relations in prompt graphs to predefined tokens. Then, we propose two message passing neural networks to perform prompt encoding and KG reasoning, respectively. We conduct evaluation on 43 different KGs in both transductive and inductive settings. Results indicate that the proposed KG-ICL outperforms baselines on most datasets, showcasing its outstanding generalization and universal reasoning capabilities. The source code is accessible on GitHub: https://github.com/nju-websoft/KG-ICL.
Expanding the Scope: Inductive Knowledge Graph Reasoning with Multi-Starting Progressive Propagation
Jul 15, 2024Knowledge graphs (KGs) are widely acknowledged as incomplete, and new entities are constantly emerging in the real world. Inductive KG reasoning aims to predict missing facts for these new entities. Among existing models, graph neural networks (GNNs) based ones have shown promising performance for this task. However, they are still challenged by inefficient message propagation due to the distance and scalability issues. In this paper, we propose a new inductive KG reasoning model, MStar, by leveraging conditional message passing neural networks (C-MPNNs). Our key insight is to select multiple query-specific starting entities to expand the scope of progressive propagation. To propagate query-related messages to a farther area within limited steps, we subsequently design a highway layer to propagate information toward these selected starting entities. Moreover, we introduce a training strategy called LinkVerify to mitigate the impact of noisy training samples. Experimental results validate that MStar achieves superior performance compared with state-of-the-art models, especially for distant entities.
Improving Continual Relation Extraction by Distinguishing Analogous Semantics
May 11, 2023Continual relation extraction (RE) aims to learn constantly emerging relations while avoiding forgetting the learned relations. Existing works store a small number of typical samples to re-train the model for alleviating forgetting. However, repeatedly replaying these samples may cause the overfitting problem. We conduct an empirical study on existing works and observe that their performance is severely affected by analogous relations. To address this issue, we propose a novel continual extraction model for analogous relations. Specifically, we design memory-insensitive relation prototypes and memory augmentation to overcome the overfitting problem. We also introduce integrated training and focal knowledge distillation to enhance the performance on analogous relations. Experimental results show the superiority of our model and demonstrate its effectiveness in distinguishing analogous relations and overcoming overfitting.
Lifelong Embedding Learning and Transfer for Growing Knowledge Graphs
Nov 29, 2022



Existing knowledge graph (KG) embedding models have primarily focused on static KGs. However, real-world KGs do not remain static, but rather evolve and grow in tandem with the development of KG applications. Consequently, new facts and previously unseen entities and relations continually emerge, necessitating an embedding model that can quickly learn and transfer new knowledge through growth. Motivated by this, we delve into an expanding field of KG embedding in this paper, i.e., lifelong KG embedding. We consider knowledge transfer and retention of the learning on growing snapshots of a KG without having to learn embeddings from scratch. The proposed model includes a masked KG autoencoder for embedding learning and update, with an embedding transfer strategy to inject the learned knowledge into the new entity and relation embeddings, and an embedding regularization method to avoid catastrophic forgetting. To investigate the impacts of different aspects of KG growth, we construct four datasets to evaluate the performance of lifelong KG embedding. Experimental results show that the proposed model outperforms the state-of-the-art inductive and lifelong embedding baselines.
Inductive Knowledge Graph Reasoning for Multi-batch Emerging Entities
Aug 22, 2022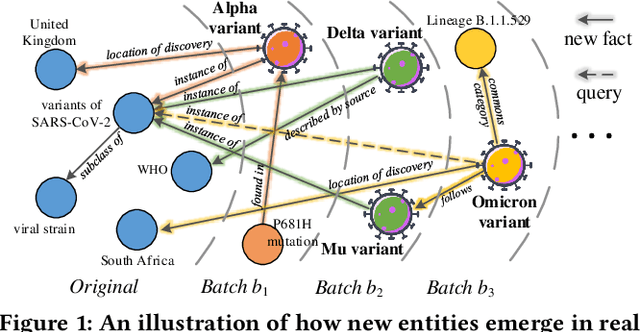
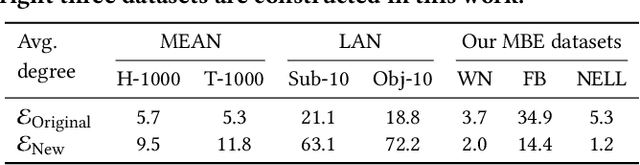
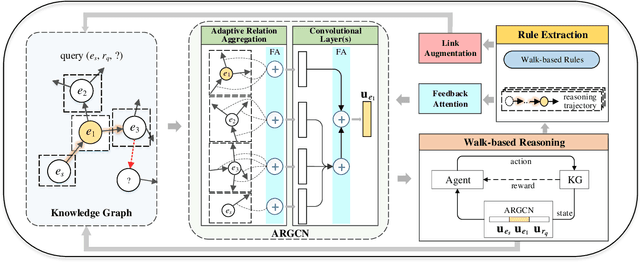

Over the years, reasoning over knowledge graphs (KGs), which aims to infer new conclusions from known facts, has mostly focused on static KGs. The unceasing growth of knowledge in real life raises the necessity to enable the inductive reasoning ability on expanding KGs. Existing inductive work assumes that new entities all emerge once in a batch, which oversimplifies the real scenario that new entities continually appear. This study dives into a more realistic and challenging setting where new entities emerge in multiple batches. We propose a walk-based inductive reasoning model to tackle the new setting. Specifically, a graph convolutional network with adaptive relation aggregation is designed to encode and update entities using their neighboring relations. To capture the varying neighbor importance, we employ a query-aware feedback attention mechanism during the aggregation. Furthermore, to alleviate the sparse link problem of new entities, we propose a link augmentation strategy to add trustworthy facts into KGs. We construct three new datasets for simulating this multi-batch emergence scenario. The experimental results show that our proposed model outperforms state-of-the-art embedding-based, walk-based and rule-based models on inductive KG reasoning.
Facing Changes: Continual Entity Alignment for Growing Knowledge Graphs
Jul 23, 2022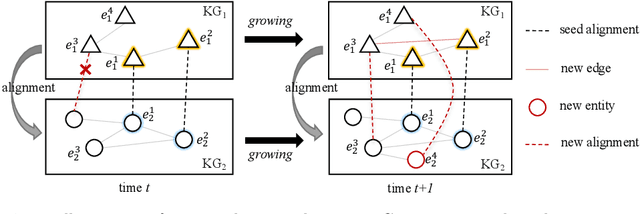
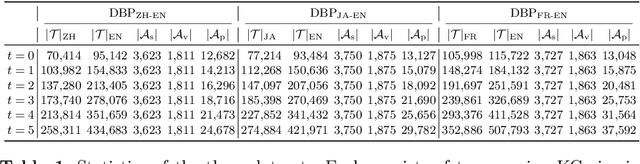


Entity alignment is a basic and vital technique in knowledge graph (KG) integration. Over the years, research on entity alignment has resided on the assumption that KGs are static, which neglects the nature of growth of real-world KGs. As KGs grow, previous alignment results face the need to be revisited while new entity alignment waits to be discovered. In this paper, we propose and dive into a realistic yet unexplored setting, referred to as continual entity alignment. To avoid retraining an entire model on the whole KGs whenever new entities and triples come, we present a continual alignment method for this task. It reconstructs an entity's representation based on entity adjacency, enabling it to generate embeddings for new entities quickly and inductively using their existing neighbors. It selects and replays partial pre-aligned entity pairs to train only parts of KGs while extracting trustworthy alignment for knowledge augmentation. As growing KGs inevitably contain non-matchable entities, different from previous works, the proposed method employs bidirectional nearest neighbor matching to find new entity alignment and update old alignment. Furthermore, we also construct new datasets by simulating the growth of multilingual DBpedia. Extensive experiments demonstrate that our continual alignment method is more effective than baselines based on retraining or inductive learning.