 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Recommendation Fairness via Graph Structure and Representation Augmentation
Aug 27, 2025Graph Convolutional Networks (GCNs) have become increasingly popular in recommendation systems. However, recent studies have shown that GCN-based models will cause sensitive information to disseminate widely in the graph structure, amplifying data bias and raising fairness concerns. While various fairness methods have been proposed, most of them neglect the impact of biased data on representation learning, which results in limited fairness improvement. Moreover, some studies have focused on constructing fair and balanced data distributions through data augmentation, but these methods significantly reduce utility due to disruption of user preferences. In this paper, we aim to design a fair recommendation method from the perspective of data augmentation to improve fairness while preserving recommendation utility. To achieve fairness-aware data augmentation with minimal disruption to user preferences, we propose two prior hypotheses. The first hypothesis identifies sensitive interactions by comparing outcomes of performance-oriented and fairness-aware recommendations, while the second one focuses on detecting sensitive features by analyzing feature similarities between biased and debiased representations. Then, we propose a dual data augmentation framework for fair recommendation, which includes two data augmentation strategies to generate fair augmented graphs and feature representations. Furthermore, we introduce a debiasing learning method that minimizes the dependence between the learned representations and sensitive information to eliminate bias. Extensive experiments on two real-world datasets demonstrate the superiority of our proposed framework.
DAMS:Dual-Branch Adaptive Multiscale Spatiotemporal Framework for Video Anomaly Detection
Jul 28, 2025



The goal of video anomaly detection is tantamount to performing spatio-temporal localization of abnormal events in the video. The multiscale temporal dependencies, visual-semantic heterogeneity, and the scarcity of labeled data exhibited by video anomalies collectively present a challenging research problem in computer vision. This study offers a dual-path architecture called the Dual-Branch Adaptive Multiscale Spatiotemporal Framework (DAMS), which is based on multilevel feature decoupling and fusion, enabling efficient anomaly detection modeling by integrating hierarchical feature learning and complementary information. The main processing path of this framework integrates the Adaptive Multiscale Time Pyramid Network (AMTPN) with the Convolutional Block Attention Mechanism (CBAM). AMTPN enables multigrained representation and dynamically weighted reconstruction of temporal features through a three-level cascade structure (time pyramid pooling, adaptive feature fusion, and temporal context enhancement). CBAM maximizes the entropy distribution of feature channels and spatial dimensions through dual attention mapping. Simultaneously, the parallel path driven by CLIP introduces a contrastive language-visual pre-training paradigm. Cross-modal semantic alignment and a multiscale instance selection mechanism provide high-order semantic guidance for spatio-temporal features. This creates a complete inference chain from the underlying spatio-temporal features to high-level semantic concepts. The orthogonal complementarity of the two paths and the information fusion mechanism jointly construct a comprehensive representation and identification capability for anomalous events. Extensive experimental results on the UCF-Crime and XD-Violence benchmarks establish the effectiveness of the DAMS framework.
ZeroSep: Separate Anything in Audio with Zero Training
May 29, 2025Audio source separation is fundamental for machines to understand complex acoustic environments and underpins numerous audio applications. Current supervised deep learning approaches, while powerful, are limited by the need for extensive, task-specific labeled data and struggle to generalize to the immense variability and open-set nature of real-world acoustic scenes. Inspired by the success of generative foundation models, we investigate whether pre-trained text-guided audio diffusion models can overcome these limitations. We make a surprising discovery: zero-shot source separation can be achieved purely through a pre-trained text-guided audio diffusion model under the right configuration. Our method, named ZeroSep, works by inverting the mixed audio into the diffusion model's latent space and then using text conditioning to guide the denoising process to recover individual sources. Without any task-specific training or fine-tuning, ZeroSep repurposes the generative diffusion model for a discriminative separation task and inherently supports open-set scenarios through its rich textual priors. ZeroSep is compatible with a variety of pre-trained text-guided audio diffusion backbones and delivers strong separation performance on multiple separation benchmarks, surpassing even supervised methods.
Test-Time Code-Switching for Cross-lingual Aspect Sentiment Triplet Extraction
Jan 24, 2025Aspect Sentiment Triplet Extraction (ASTE) is a thriving research area with impressive outcomes being achieved on high-resource languages. However, the application of cross-lingual transfer to the ASTE task has been relatively unexplored, and current code-switching methods still suffer from term boundary detection issues and out-of-dictionary problems. In this study, we introduce a novel Test-Time Code-SWitching (TT-CSW) framework, which bridges the gap between the bilingual training phase and the monolingual test-time prediction. During training, a generative model is developed based on bilingual code-switched training data and can produce bilingual ASTE triplets for bilingual inputs. In the testing stage, we employ an alignment-based code-switching technique for test-time augmentation. Extensive experiments on cross-lingual ASTE datasets validate the effectiveness of our proposed method. We achieve an average improvement of 3.7% in terms of weighted-averaged F1 in four datasets with different languages. Additionally, we set a benchmark using ChatGPT and GPT-4, and demonstrate that even smaller generative models fine-tuned with our proposed TT-CSW framework surpass ChatGPT and GPT-4 by 14.2% and 5.0% respectively.
Distributed Multi-Objective Dynamic Offloading Scheduling for Air-Ground Cooperative MEC
Mar 16, 2024



Utilizing unmanned aerial vehicles (UAVs) with edge server to assist terrestrial mobile edge computing (MEC) has attracted tremendous attention. Nevertheless, state-of-the-art schemes based on deterministic optimizations or single-objective reinforcement learning (RL) cannot reduce the backlog of task bits and simultaneously improve energy efficiency in highly dynamic network environments, where the design problem amounts to a sequential decision-making problem. In order to address the aforementioned problems, as well as the curses of dimensionality introduced by the growing number of terrestrial terrestrial users, this paper proposes a distributed multi-objective (MO) dynamic trajectory planning and offloading scheduling scheme, integrated with MORL and the kernel method. The design of n-step return is also applied to average fluctuations in the backlog. Numerical results reveal that the n-step return can benefit the proposed kernel-based approach, achieving significant improvement in the long-term average backlog performance, compared to the conventional 1-step return design. Due to such design and the kernel-based neural network, to which decision-making features can be continuously added, the kernel-based approach can outperform the approach based on fully-connected deep neural network, yielding improvement in energy consumption and the backlog performance, as well as a significant reduction in decision-making and online learning time.
Improving LLM-based Machine Translation with Systematic Self-Correction
Mar 04, 2024Large Language Models (LLMs) have achieved impressive results in Machine Translation (MT). However, careful evaluations by human reveal that the translations produced by LLMs still contain multiple errors. Importantly, feeding back such error information into the LLMs can lead to self-correction and result in improved translation performance. Motivated by these insights, we introduce a systematic LLM-based self-correcting translation framework, named TER, which stands for Translate, Estimate, and Refine, marking a significant step forward in this direction. Our findings demonstrate that 1) our self-correction framework successfully assists LLMs in improving their translation quality across a wide range of languages, whether it's from high-resource languages to low-resource ones or whether it's English-centric or centered around other languages; 2) TER exhibits superior systematicity and interpretability compared to previous methods; 3) different estimation strategies yield varied impacts on AI feedback, directly affecting the effectiveness of the final corrections. We further compare different LLMs and conduct various experiments involving self-correction and cross-model correction to investigate the potential relationship between the translation and evaluation capabilities of LLMs. Our code and data are available at https://github.com/fzp0424/self_correct_mt
Knowledge-augmented Few-shot Visual Relation Detection
Mar 09, 2023



Visual Relation Detection (VRD) aims to detect relationships between objects for image understanding. Most existing VRD methods rely on thousands of training samples of each relationship to achieve satisfactory performance. Some recent papers tackle this problem by few-shot learning with elaborately designed pipelines and pre-trained word vectors. However, the performance of existing few-shot VRD models is severely hampered by the poor generalization capability, as they struggle to handle the vast semantic diversity of visual relationships. Nonetheless, humans have the ability to learn new relationships with just few examples based on their knowledge. Inspired by this, we devise a knowledge-augmented, few-shot VRD framework leveraging both textual knowledge and visual relation knowledge to improve the generalization ability of few-shot VRD. The textual knowledge and visual relation knowledge are acquired from a pre-trained language model and an automatically constructed visual relation knowledge graph, respectively. We extensively validate the effectiveness of our framework. Experiments conducted on three benchmarks from the commonly used Visual Genome dataset show that our performance surpasses existing state-of-the-art models with a large improvement.
Lifelong Embedding Learning and Transfer for Growing Knowledge Graphs
Nov 29, 2022



Existing knowledge graph (KG) embedding models have primarily focused on static KGs. However, real-world KGs do not remain static, but rather evolve and grow in tandem with the development of KG applications. Consequently, new facts and previously unseen entities and relations continually emerge, necessitating an embedding model that can quickly learn and transfer new knowledge through growth. Motivated by this, we delve into an expanding field of KG embedding in this paper, i.e., lifelong KG embedding. We consider knowledge transfer and retention of the learning on growing snapshots of a KG without having to learn embeddings from scratch. The proposed model includes a masked KG autoencoder for embedding learning and update, with an embedding transfer strategy to inject the learned knowledge into the new entity and relation embeddings, and an embedding regularization method to avoid catastrophic forgetting. To investigate the impacts of different aspects of KG growth, we construct four datasets to evaluate the performance of lifelong KG embedding. Experimental results show that the proposed model outperforms the state-of-the-art inductive and lifelong embedding baselines.
Inductive Knowledge Graph Reasoning for Multi-batch Emerging Entities
Aug 22, 2022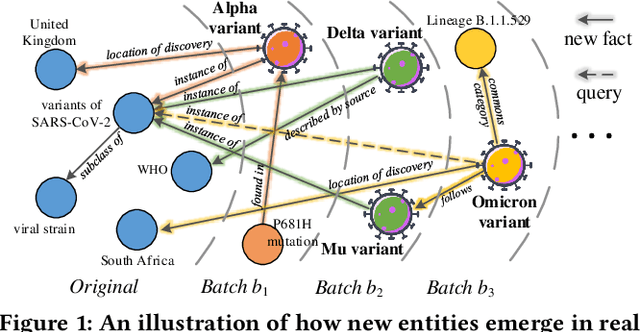
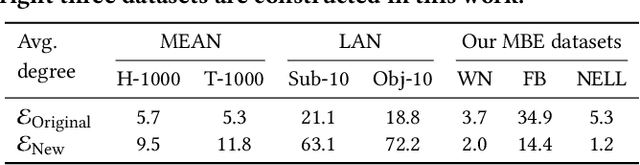
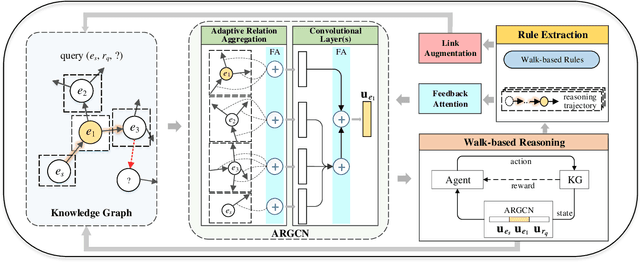

Over the years, reasoning over knowledge graphs (KGs), which aims to infer new conclusions from known facts, has mostly focused on static KGs. The unceasing growth of knowledge in real life raises the necessity to enable the inductive reasoning ability on expanding KGs. Existing inductive work assumes that new entities all emerge once in a batch, which oversimplifies the real scenario that new entities continually appear. This study dives into a more realistic and challenging setting where new entities emerge in multiple batches. We propose a walk-based inductive reasoning model to tackle the new setting. Specifically, a graph convolutional network with adaptive relation aggregation is designed to encode and update entities using their neighboring relations. To capture the varying neighbor importance, we employ a query-aware feedback attention mechanism during the aggregation. Furthermore, to alleviate the sparse link problem of new entities, we propose a link augmentation strategy to add trustworthy facts into KGs. We construct three new datasets for simulating this multi-batch emergence scenario. The experimental results show that our proposed model outperforms state-of-the-art embedding-based, walk-based and rule-based models on inductive KG reasoning.
Facing Changes: Continual Entity Alignment for Growing Knowledge Graphs
Jul 23, 2022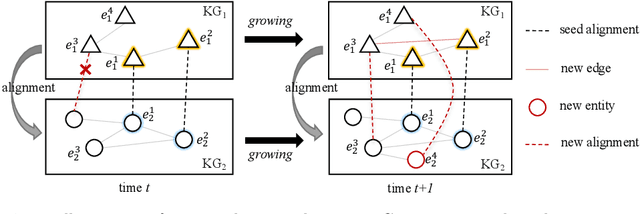
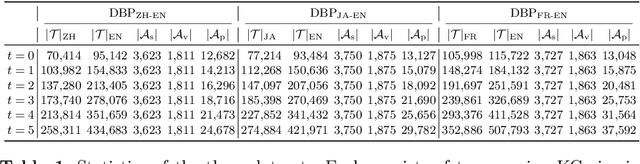


Entity alignment is a basic and vital technique in knowledge graph (KG) integration. Over the years, research on entity alignment has resided on the assumption that KGs are static, which neglects the nature of growth of real-world KGs. As KGs grow, previous alignment results face the need to be revisited while new entity alignment waits to be discovered. In this paper, we propose and dive into a realistic yet unexplored setting, referred to as continual entity alignment. To avoid retraining an entire model on the whole KGs whenever new entities and triples come, we present a continual alignment method for this task. It reconstructs an entity's representation based on entity adjacency, enabling it to generate embeddings for new entities quickly and inductively using their existing neighbors. It selects and replays partial pre-aligned entity pairs to train only parts of KGs while extracting trustworthy alignment for knowledge augmentation. As growing KGs inevitably contain non-matchable entities, different from previous works, the proposed method employs bidirectional nearest neighbor matching to find new entity alignment and update old alignment. Furthermore, we also construct new datasets by simulating the growth of multilingual DBpedia. Extensive experiments demonstrate that our continual alignment method is more effective than baselines based on retraining or inductive learning.