 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-augmented Few-shot Visual Relation Detection
Mar 09, 2023



Visual Relation Detection (VRD) aims to detect relationships between objects for image understanding. Most existing VRD methods rely on thousands of training samples of each relationship to achieve satisfactory performance. Some recent papers tackle this problem by few-shot learning with elaborately designed pipelines and pre-trained word vectors. However, the performance of existing few-shot VRD models is severely hampered by the poor generalization capability, as they struggle to handle the vast semantic diversity of visual relationships. Nonetheless, humans have the ability to learn new relationships with just few examples based on their knowledge. Inspired by this, we devise a knowledge-augmented, few-shot VRD framework leveraging both textual knowledge and visual relation knowledge to improve the generalization ability of few-shot VRD. The textual knowledge and visual relation knowledge are acquired from a pre-trained language model and an automatically constructed visual relation knowledge graph, respectively. We extensively validate the effectiveness of our framework. Experiments conducted on three benchmarks from the commonly used Visual Genome dataset show that our performance surpasses existing state-of-the-art models with a large improvement.
Knowledge forest: a novel model to organize knowledge fragments
Dec 14, 2019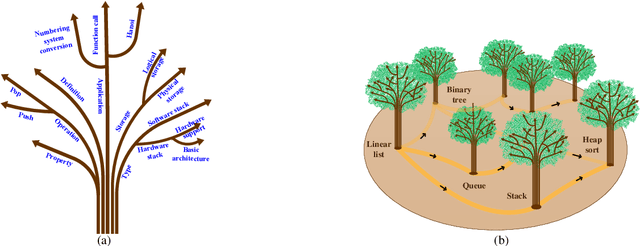
With the rapid growth of knowledge, it shows a steady trend of knowledge fragmentization. Knowledge fragmentization manifests as that the knowledge related to a specific topic in a course is scattered in isolated and autonomous knowledge sources. We term the knowledge of a facet in a specific topic as a knowledge fragment. The problem of knowledge fragmentization brings two challenges: First, knowledge is scattered in various knowledge sources, which exerts users' considerable efforts to search for the knowledge of their interested topics, thereby leading to information overload. Second, learning dependencies which refer to the precedence relationships between topics in the learning process are concealed by the isolation and autonomy of knowledge sources, thus causing learning disorientation. To solve the knowledge fragmentization problem, we propose a novel knowledge organization model, knowledge forest, which consists of facet trees and learning dependencies. Facet trees can organize knowledge fragments with facet hyponymy to alleviate information overload. Learning dependencies can organize disordered topics to cope with learning disorientation. We conduct extensive experiments on three manually constructed datasets from the Data Structure, Data Mining, and Computer Network courses, and the experimental results show that knowledge forest can effectively organize knowledge fragments, and alleviate information overload and learning disorientation.