 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrefix Grouper: Efficient GRPO Training through Shared-Prefix Forward
Jun 05, 2025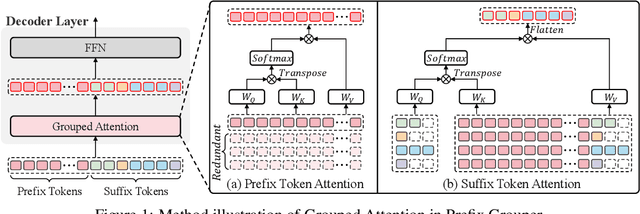
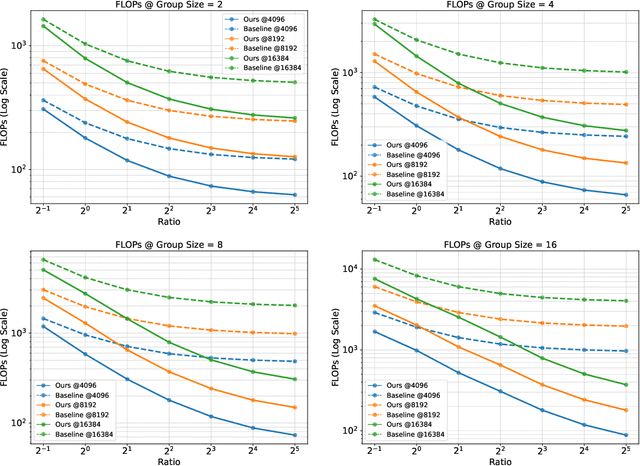
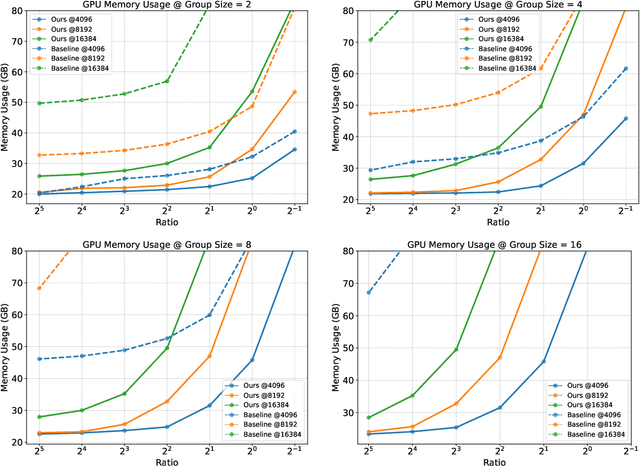
Group Relative Policy Optimization (GRPO) enhances policy learning by computing gradients from relative comparisons among candidate outputs that share a common input prefix. Despite its effectiveness, GRPO introduces substantial computational overhead when processing long shared prefixes, which must be redundantly encoded for each group member. This inefficiency becomes a major scalability bottleneck in long-context learning scenarios. We propose Prefix Grouper, an efficient GRPO training algorithm that eliminates redundant prefix computation via a Shared-Prefix Forward strategy. In particular, by restructuring self-attention into two parts, our method enables the shared prefix to be encoded only once, while preserving full differentiability and compatibility with end-to-end training. We provide both theoretical and empirical evidence that Prefix Grouper is training-equivalent to standard GRPO: it yields identical forward outputs and backward gradients, ensuring that the optimization dynamics and final policy performance remain unchanged. Empirically, our experiments confirm that Prefix Grouper achieves consistent results while significantly reducing the computational cost of training, particularly in long-prefix scenarios. The proposed method is fully plug-and-play: it is compatible with existing GRPO-based architectures and can be seamlessly integrated into current training pipelines as a drop-in replacement, requiring no structural modifications and only minimal changes to input construction and attention computation. Prefix Grouper enables the use of larger group sizes under the same computational budget, thereby improving the scalability of GRPO to more complex tasks and larger models. Code is now available at https://github.com/johncaged/PrefixGrouper
ScEdit: Script-based Assessment of Knowledge Editing
May 29, 2025Knowledge Editing (KE) has gained increasing attention, yet current KE tasks remain relatively simple. Under current evaluation frameworks, many editing methods achieve exceptionally high scores, sometimes nearing perfection. However, few studies integrate KE into real-world application scenarios (e.g., recent interest in LLM-as-agent). To support our analysis, we introduce a novel script-based benchmark -- ScEdit (Script-based Knowledge Editing Benchmark) -- which encompasses both counterfactual and temporal edits. We integrate token-level and text-level evaluation methods, comprehensively analyzing existing KE techniques. The benchmark extends traditional fact-based ("What"-type question) evaluation to action-based ("How"-type question) evaluation. We observe that all KE methods exhibit a drop in performance on established metrics and face challenges on text-level metrics, indicating a challenging task. Our benchmark is available at https://github.com/asdfo123/ScEdit.
LFTF: Locating First and Then Fine-Tuning for Mitigating Gender Bias in Large Language Models
May 21, 2025Nowadays, Large Language Models (LLMs) have attracted widespread attention due to their powerful performance. However, due to the unavoidable exposure to socially biased data during training, LLMs tend to exhibit social biases, particularly gender bias. To better explore and quantifying the degree of gender bias in LLMs, we propose a pair of datasets named GenBiasEval and GenHintEval, respectively. The GenBiasEval is responsible for evaluating the degree of gender bias in LLMs, accompanied by an evaluation metric named AFGB-Score (Absolutely Fair Gender Bias Score). Meanwhile, the GenHintEval is used to assess whether LLMs can provide responses consistent with prompts that contain gender hints, along with the accompanying evaluation metric UB-Score (UnBias Score). Besides, in order to mitigate gender bias in LLMs more effectively, we present the LFTF (Locating First and Then Fine-Tuning) algorithm.The algorithm first ranks specific LLM blocks by their relevance to gender bias in descending order using a metric called BMI (Block Mitigating Importance Score). Based on this ranking, the block most strongly associated with gender bias is then fine-tuned using a carefully designed loss function. Numerous experiments have shown that our proposed LFTF algorithm can significantly mitigate gender bias in LLMs while maintaining their general capabilities.
TRACE: Temporal Grounding Video LLM via Causal Event Modeling
Oct 08, 2024



Video Temporal Grounding (VTG) is a crucial capability for video understanding models and plays a vital role in downstream tasks such as video browsing and editing. To effectively handle various tasks simultaneously and enable zero-shot prediction, there is a growing trend in employing video LLMs for VTG tasks. However, current video LLM-based methods rely exclusively on natural language generation, lacking the ability to model the clear structure inherent in videos, which restricts their effectiveness in tackling VTG tasks. To address this issue, this paper first formally introduces causal event modeling framework, which represents videos as sequences of events, and predict the current event using previous events, video inputs, and textural instructions. Each event consists of three components: timestamps, salient scores, and textual captions. We then propose a novel task-interleaved video LLM called TRACE to effectively implement the causal event modeling framework in practice. The TRACE processes visual frames, timestamps, salient scores, and text as distinct tasks, employing various encoders and decoding heads for each. Task tokens are arranged in an interleaved sequence according to the causal event modeling framework's formulation. Extensive experiments on various VTG tasks and datasets demonstrate the superior performance of TRACE compared to state-of-the-art video LLMs. Our model and code are available at \url{https://github.com/gyxxyg/TRACE}.
Enhancing Long Video Understanding via Hierarchical Event-Based Memory
Sep 10, 2024
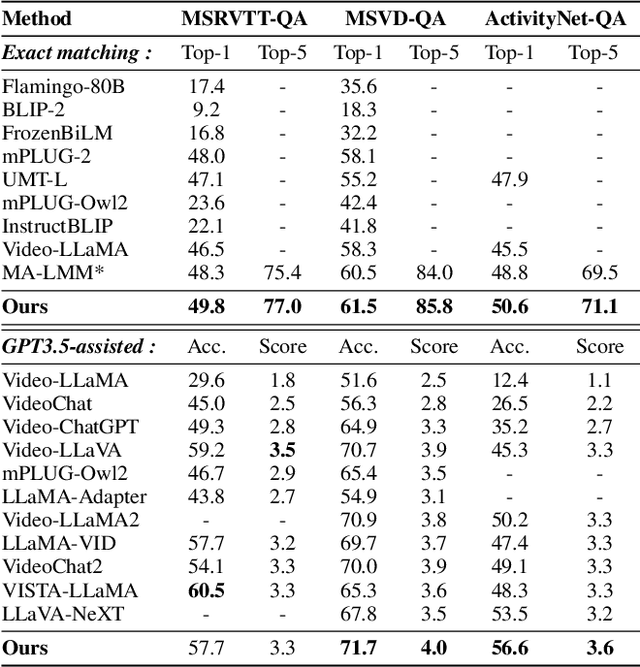
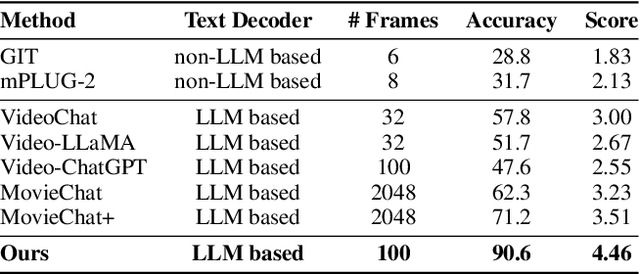

Recently, integrating visual foundation models into large language models (LLMs) to form video understanding systems has attracted widespread attention. Most of the existing models compress diverse semantic information within the whole video and feed it into LLMs for content comprehension. While this method excels in short video understanding, it may result in a blend of multiple event information in long videos due to coarse compression, which causes information redundancy. Consequently, the semantics of key events might be obscured within the vast information that hinders the model's understanding capabilities. To address this issue, we propose a Hierarchical Event-based Memory-enhanced LLM (HEM-LLM) for better understanding of long videos. Firstly, we design a novel adaptive sequence segmentation scheme to divide multiple events within long videos. In this way, we can perform individual memory modeling for each event to establish intra-event contextual connections, thereby reducing information redundancy. Secondly, while modeling current event, we compress and inject the information of the previous event to enhance the long-term inter-event dependencies in videos. Finally, we perform extensive experiments on various video understanding tasks and the results show that our model achieves state-of-the-art performances.
TC-LLaVA: Rethinking the Transfer from Image to Video Understanding with Temporal Considerations
Sep 05, 2024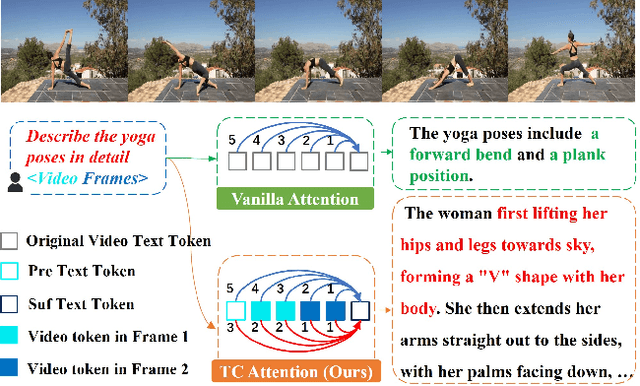

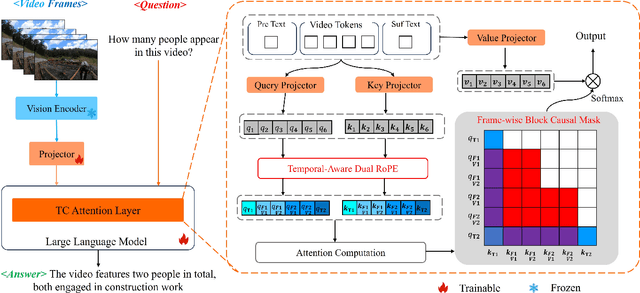

Multimodal Large Language Models (MLLMs) have significantly improved performance across various image-language applications. Recently, there has been a growing interest in adapting image pre-trained MLLMs for video-related tasks. However, most efforts concentrate on enhancing the vision encoder and projector components, while the core part, Large Language Models (LLMs), remains comparatively under-explored. In this paper, we propose two strategies to enhance the model's capability in video understanding tasks by improving inter-layer attention computation in LLMs. Specifically, the first approach focuses on the enhancement of Rotary Position Embedding (RoPE) with Temporal-Aware Dual RoPE, which introduces temporal position information to strengthen the MLLM's temporal modeling capabilities while preserving the relative position relationships of both visual and text tokens. The second approach involves enhancing the Attention Mask with the Frame-wise Block Causal Attention Mask, a simple yet effective method that broadens visual token interactions within and across video frames while maintaining the causal inference mechanism. Based on these proposed methods, we adapt LLaVA for video understanding tasks, naming it Temporal-Considered LLaVA (TC-LLaVA). Our TC-LLaVA achieves new state-of-the-art performance across various video understanding benchmarks with only supervised fine-tuning (SFT) on video-related datasets.
To Forget or Not? Towards Practical Knowledge Unlearning for Large Language Models
Jul 02, 2024

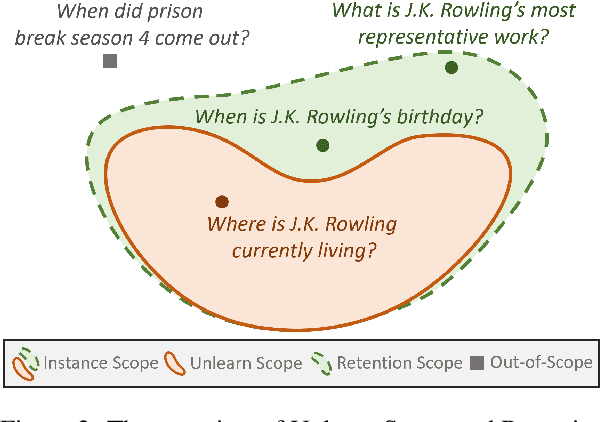

Large Language Models (LLMs) trained on extensive corpora inevitably retain sensitive data, such as personal privacy information and copyrighted material. Recent advancements in knowledge unlearning involve updating LLM parameters to erase specific knowledge. However, current unlearning paradigms are mired in vague forgetting boundaries, often erasing knowledge indiscriminately. In this work, we introduce KnowUnDo, a benchmark containing copyrighted content and user privacy domains to evaluate if the unlearning process inadvertently erases essential knowledge. Our findings indicate that existing unlearning methods often suffer from excessive unlearning. To address this, we propose a simple yet effective method, MemFlex, which utilizes gradient information to precisely target and unlearn sensitive parameters. Experimental results show that MemFlex is superior to existing methods in both precise knowledge unlearning and general knowledge retaining of LLMs. Code and dataset will be released at https://github.com/zjunlp/KnowUnDo.
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging
Jun 24, 2024While large language models (LLMs) excel in many domains, their complexity and scale challenge deployment in resource-limited environments. Current compression techniques, such as parameter pruning, often fail to effectively utilize the knowledge from pruned parameters. To address these challenges, we propose Manifold-Based Knowledge Alignment and Layer Merging Compression (MKA), a novel approach that uses manifold learning and the Normalized Pairwise Information Bottleneck (NPIB) measure to merge similar layers, reducing model size while preserving essential performance. We evaluate MKA on multiple benchmark datasets and various LLMs. Our findings show that MKA not only preserves model performance but also achieves substantial compression ratios, outperforming traditional pruning methods. Moreover, when coupled with quantization, MKA delivers even greater compression. Specifically, on the MMLU dataset using the Llama3-8B model, MKA achieves a compression ratio of 43.75% with a minimal performance decrease of only 2.82\%. The proposed MKA method offers a resource-efficient and performance-preserving model compression technique for LLMs.
Can We Edit Multimodal Large Language Models?
Oct 13, 2023



In this paper, we focus on editing Multimodal Large Language Models (MLLMs). Compared to editing single-modal LLMs, multimodal model editing is more challenging, which demands a higher level of scrutiny and careful consideration in the editing process. To facilitate research in this area, we construct a new benchmark, dubbed MMEdit, for editing multimodal LLMs and establishing a suite of innovative metrics for evaluation. We conduct comprehensive experiments involving various model editing baselines and analyze the impact of editing different components for multimodal LLMs. Empirically, we notice that previous baselines can implement editing multimodal LLMs to some extent, but the effect is still barely satisfactory, indicating the potential difficulty of this task. We hope that our work can provide the NLP community with insights. Code and dataset are available in https://github.com/zjunlp/EasyEdit.
Knowledge-augmented Few-shot Visual Relation Detection
Mar 09, 2023



Visual Relation Detection (VRD) aims to detect relationships between objects for image understanding. Most existing VRD methods rely on thousands of training samples of each relationship to achieve satisfactory performance. Some recent papers tackle this problem by few-shot learning with elaborately designed pipelines and pre-trained word vectors. However, the performance of existing few-shot VRD models is severely hampered by the poor generalization capability, as they struggle to handle the vast semantic diversity of visual relationships. Nonetheless, humans have the ability to learn new relationships with just few examples based on their knowledge. Inspired by this, we devise a knowledge-augmented, few-shot VRD framework leveraging both textual knowledge and visual relation knowledge to improve the generalization ability of few-shot VRD. The textual knowledge and visual relation knowledge are acquired from a pre-trained language model and an automatically constructed visual relation knowledge graph, respectively. We extensively validate the effectiveness of our framework. Experiments conducted on three benchmarks from the commonly used Visual Genome dataset show that our performance surpasses existing state-of-the-art models with a large improvement.