 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Parallelization of Message Passing Neural Networks
May 15, 2025Machine learning potentials have achieved great success in accelerating atomistic simulations. Many of them rely on local descriptors that readily allow parallelization. More recent message passing neural network (MPNN) models have demonstrated their superior accuracy and become increasingly popular. However, parallelizing MPNN models for large-scale simulations across compute nodes remains a challenge, as the previously argued poor scalability with the number of MP layers and the necessity of data communication. Here, we propose an efficient parallel algorithm for MPNN models, in which additional data communication is minimized among local atoms only in each MP layer without redundant computation, thus scaling linearly with the layer number. Integrated with our recursively embedded atom neural network model, this algorithm demonstrates excellent strong scaling and weak scaling behaviors in several benchmark systems. This approach enables massive molecular dynamics simulations on MPNN models for hundreds of millions of atoms as fast as on strictly local models, vastly extending the applicability of the MPNN potential to an unprecedented scale. This general parallelization framework can empower various MPNN models to efficiently simulate very large and complex systems.
Spec2VolCAMU-Net: A Spectrogram-to-Volume Model for EEG-to-fMRI Reconstruction based on Multi-directional Time-Frequency Convolutional Attention Encoder and Vision-Mamba U-Net
May 14, 2025High-resolution functional magnetic resonance imaging (fMRI) is essential for mapping human brain activity; however, it remains costly and logistically challenging. If comparable volumes could be generated directly from widely available scalp electroencephalography (EEG), advanced neuroimaging would become significantly more accessible. Existing EEG-to-fMRI generators rely on plain CNNs that fail to capture cross-channel time-frequency cues or on heavy transformer/GAN decoders that strain memory and stability. We propose Spec2VolCAMU-Net, a lightweight spectrogram-to-volume generator that confronts these issues via a Multi-directional Time-Frequency Convolutional Attention Encoder, stacking temporal, spectral and joint convolutions with self-attention, and a Vision-Mamba U-Net decoder whose linear-time state-space blocks enable efficient long-range spatial modelling. Trained end-to-end with a hybrid SSI-MSE loss, Spec2VolCAMU-Net achieves state-of-the-art fidelity on three public benchmarks, recording SSIMs of 0.693 on NODDI, 0.725 on Oddball and 0.788 on CN-EPFL, representing improvements of 14.5%, 14.9%, and 16.9% respectively over previous best SSIM scores. Furthermore, it achieves competitive PSNR scores, particularly excelling on the CN-EPFL dataset with a 4.6% improvement over the previous best PSNR, thus striking a better balance in reconstruction quality. The proposed model is lightweight and efficient, making it suitable for real-time applications in clinical and research settings. The code is available at https://github.com/hdy6438/Spec2VolCAMU-Net.
Generative Modeling of Adversarial Lane-Change Scenario
Mar 15, 2025



Decision-making in long-tail scenarios is crucial to autonomous driving development, with realistic and challenging simulations playing a pivotal role in testing safety-critical situations. However, the current open-source datasets do not systematically include long-tail distributed scenario data, making acquiring such scenarios a formidable task. To address this problem, a data mining framework is proposed, which performs in-depth analysis on two widely-used datasets, NGSIM and INTERACTION, to pinpoint data with hazardous behavioral traits, aiming to bridge the gap in these overlooked scenarios. The approach utilizes Generative Adversarial Imitation Learning (GAIL) based on an enhanced Proximal Policy Optimization (PPO) model, integrated with the vehicle's environmental analysis, to iteratively refine and represent the newly generated vehicle trajectory. Innovatively, the solution optimizes the generation of adversarial scenario data from the perspectives of sensitivity and reasonable adversarial. It is demonstrated through experiments that, compared to the unfiltered data and baseline models, the approach exhibits more adversarial yet natural behavior regarding collision rate, acceleration, and lane changes, thereby validating its suitability for generating scenario data and providing constructive insights for the development of future scenarios and subsequent decision training.
Beautimeter: Harnessing GPT for Assessing Architectural and Urban Beauty based on the 15 Properties of Living Structure
Nov 28, 2024
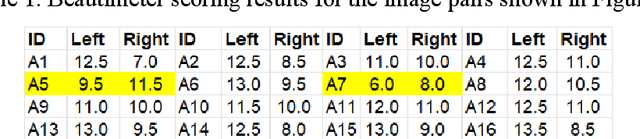


Beautimeter is a new tool powered by generative pre-trained transformer (GPT) technology, designed to evaluate architectural and urban beauty. Rooted in Christopher Alexander's theory of centers, this work builds on the idea that all environments possess, to varying degrees, an innate sense of life. Alexander identified 15 fundamental properties, such as levels of scale and thick boundaries, that characterize living structure, which Beautimeter uses as a basis for its analysis. By integrating GPT's advanced natural language processing capabilities, Beautimeter assesses the extent to which a structure embodies these 15 properties, enabling a nuanced evaluation of architectural and urban aesthetics. Using ChatGPT, the tool helps users generate insights into the perceived beauty and coherence of spaces. We conducted a series of case studies, evaluating images of architectural and urban environments, as well as carpets, paintings, and other artifacts. The results demonstrate Beautimeter's effectiveness in analyzing aesthetic qualities across diverse contexts. Our findings suggest that by leveraging GPT technology, Beautimeter offers architects, urban planners, and designers a powerful tool to create spaces that resonate deeply with people. This paper also explores the implications of such technology for architecture and urban design, highlighting its potential to enhance both the design process and the assessment of built environments. Keywords: Living structure, structural beauty, Christopher Alexander, AI in Design, human centered design
Enhancing Long Video Understanding via Hierarchical Event-Based Memory
Sep 10, 2024
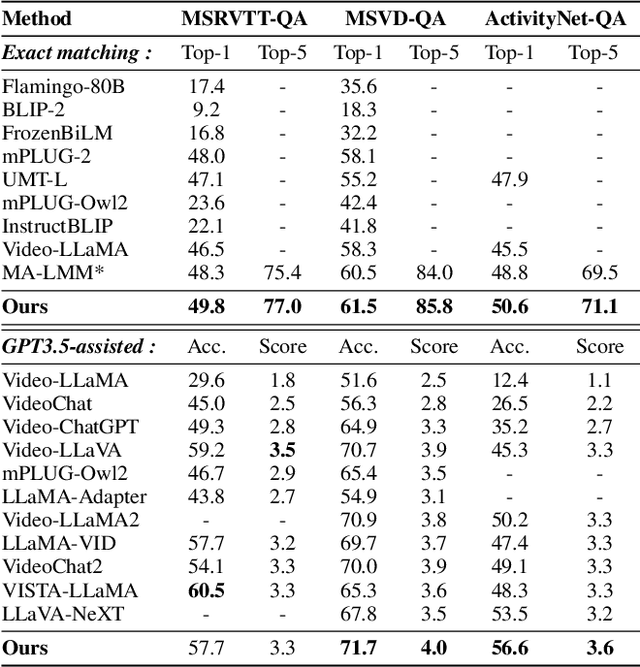
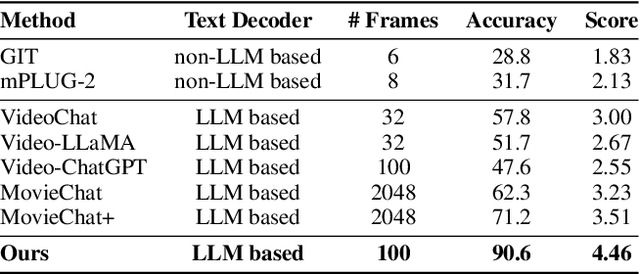

Recently, integrating visual foundation models into large language models (LLMs) to form video understanding systems has attracted widespread attention. Most of the existing models compress diverse semantic information within the whole video and feed it into LLMs for content comprehension. While this method excels in short video understanding, it may result in a blend of multiple event information in long videos due to coarse compression, which causes information redundancy. Consequently, the semantics of key events might be obscured within the vast information that hinders the model's understanding capabilities. To address this issue, we propose a Hierarchical Event-based Memory-enhanced LLM (HEM-LLM) for better understanding of long videos. Firstly, we design a novel adaptive sequence segmentation scheme to divide multiple events within long videos. In this way, we can perform individual memory modeling for each event to establish intra-event contextual connections, thereby reducing information redundancy. Secondly, while modeling current event, we compress and inject the information of the previous event to enhance the long-term inter-event dependencies in videos. Finally, we perform extensive experiments on various video understanding tasks and the results show that our model achieves state-of-the-art performances.
Medical Image Segmentation via Single-Source Domain Generalization with Random Amplitude Spectrum Synthesis
Sep 07, 2024



The field of medical image segmentation is challenged by domain generalization (DG) due to domain shifts in clinical datasets. The DG challenge is exacerbated by the scarcity of medical data and privacy concerns. Traditional single-source domain generalization (SSDG) methods primarily rely on stacking data augmentation techniques to minimize domain discrepancies. In this paper, we propose Random Amplitude Spectrum Synthesis (RASS) as a training augmentation for medical images. RASS enhances model generalization by simulating distribution changes from a frequency perspective. This strategy introduces variability by applying amplitude-dependent perturbations to ensure broad coverage of potential domain variations. Furthermore, we propose random mask shuffle and reconstruction components, which can enhance the ability of the backbone to process structural information and increase resilience intra- and cross-domain changes. The proposed Random Amplitude Spectrum Synthesis for Single-Source Domain Generalization (RAS^4DG) is validated on 3D fetal brain images and 2D fundus photography, and achieves an improved DG segmentation performance compared to other SSDG models.
IPED: An Implicit Perspective for Relational Triple Extraction based on Diffusion Model
Feb 24, 2024Relational triple extraction is a fundamental task in the field of information extraction, and a promising framework based on table filling has recently gained attention as a potential baseline for entity relation extraction. However, inherent shortcomings such as redundant information and incomplete triple recognition remain problematic. To address these challenges, we propose an Implicit Perspective for relational triple Extraction based on Diffusion model (IPED), an innovative approach for extracting relational triples. Our classifier-free solution adopts an implicit strategy using block coverage to complete the tables, avoiding the limitations of explicit tagging methods. Additionally, we introduce a generative model structure, the block-denoising diffusion model, to collaborate with our implicit perspective and effectively circumvent redundant information disruptions. Experimental results on two popular datasets demonstrate that IPED achieves state-of-the-art performance while gaining superior inference speed and low computational complexity. To support future research, we have made our source code publicly available online.
Recursive Segmentation Living Image: An eXplainable AI (XAI) Approach for Computing Structural Beauty of Images or the Livingness of Space
Oct 16, 2023This study introduces the concept of "structural beauty" as an objective computational approach for evaluating the aesthetic appeal of images. Through the utilization of the Segment anything model (SAM), we propose a method that leverages recursive segmentation to extract finer-grained substructures. Additionally, by reconstructing the hierarchical structure, we obtain a more accurate representation of substructure quantity and hierarchy. This approach reproduces and extends our previous research, allowing for the simultaneous assessment of Livingness in full-color images without the need for grayscale conversion or separate computations for foreground and background Livingness. Furthermore, the application of our method to the Scenic or Not dataset, a repository of subjective scenic ratings, demonstrates a high degree of consistency with subjective ratings in the 0-6 score range. This underscores that structural beauty is not solely a subjective perception, but a quantifiable attribute accessible through objective computation. Through our case studies, we have arrived at three significant conclusions. 1) our method demonstrates the capability to accurately segment meaningful objects, including trees, buildings, and windows, as well as abstract substructures within paintings. 2) we observed that the clarity of an image impacts our computational results; clearer images tend to yield higher Livingness scores. However, for equally blurry images, Livingness does not exhibit a significant reduction, aligning with human visual perception. 3) our approach fundamentally differs from methods employing Convolutional Neural Networks (CNNs) for predicting image scores. Our method not only provides computational results but also offers transparency and interpretability, positioning it as a novel avenue in the realm of Explainable AI (XAI).
Prompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023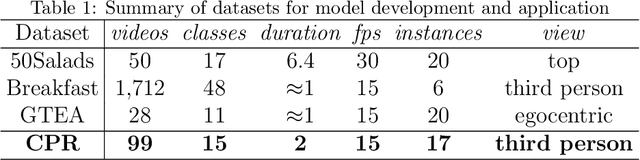
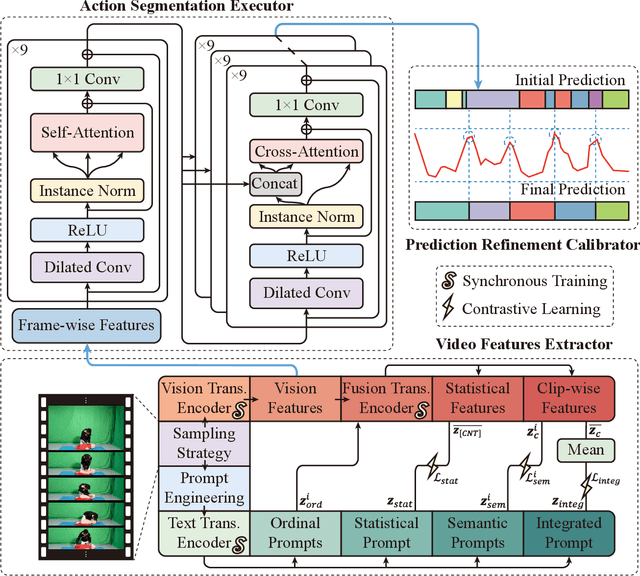
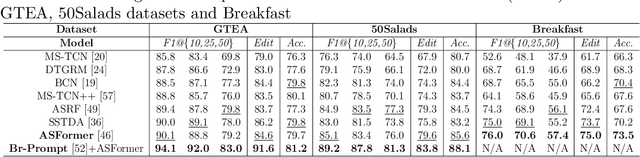

The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.
Living Images: A Recursive Approach to Computing the Structural Beauty of Images or the Livingness of Space
Jan 04, 2023Any image is perceived subconsciously as a coherent structure (or whole) with two contrast substructures: figure and ground. The figure consists of numerous auto-generated substructures with an inherent hierarchy of far more smalls than larges. Through these substructures, the structural beauty of an image (L) can be computed by the multiplication of the number of substructures (S) and their inherent hierarchy (H). This definition implies that the more substructures, the more living or more structurally beautiful, and the higher hierarchy of the substructures, the more living or more structurally beautiful. This is the non-recursive approach to the structural beauty of images or the livingness of space. In this paper we develop a recursive approach, which derives all substructures of an image (instead of its figure) and continues the deriving process for those decomposable substructures until none of them are decomposable. All of the substructures derived at different iterations (or recursive levels) together constitute a living structure; hence the notion of living images. We applied the recursive approach to a set of images and found that (1) the number of substructures of an image is far lower (3 percent on average) than the number of pixels and the centroids of the substructures can effectively capture the skeleton or saliency of the image; (2) all the images have the recursive levels more than three, indicating that they are indeed living images; (3) no more than 2 percent of the substructures are decomposable; (4) structural beauty can be measured by the recursively defined substructures, as well as their decomposable subsets. The recursive approach is proved to be more robust than the non-recursive approach. The recursive approach and the non-recursive approach both provide a powerful means to study the livingness or vitality of space in cities and communities.