 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt-enhanced Hierarchical Transformer Elevating Cardiopulmonary Resuscitation Instruction via Temporal Action Segmentation
Aug 31, 2023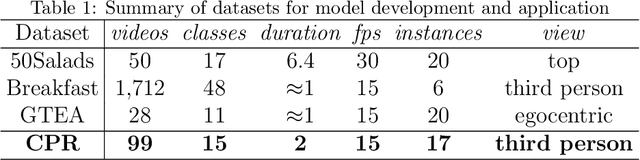
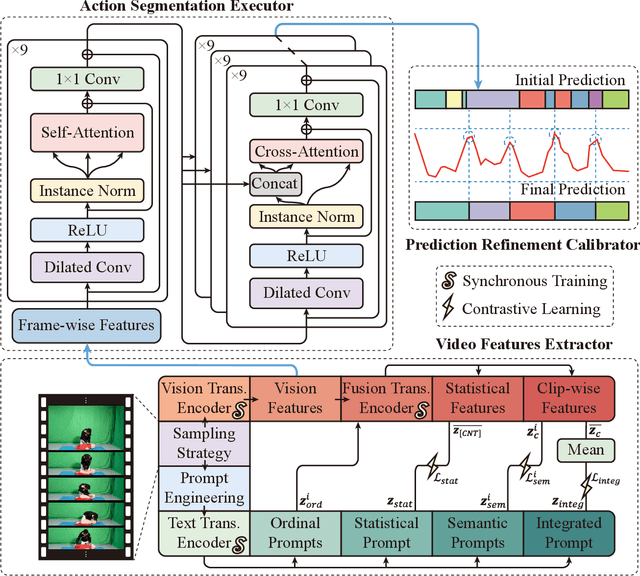
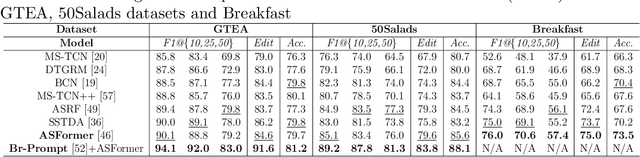

The vast majority of people who suffer unexpected cardiac arrest are performed cardiopulmonary resuscitation (CPR) by passersby in a desperate attempt to restore life, but endeavors turn out to be fruitless on account of disqualification. Fortunately, many pieces of research manifest that disciplined training will help to elevate the success rate of resuscitation, which constantly desires a seamless combination of novel techniques to yield further advancement. To this end, we collect a custom CPR video dataset in which trainees make efforts to behave resuscitation on mannequins independently in adherence to approved guidelines, thereby devising an auxiliary toolbox to assist supervision and rectification of intermediate potential issues via modern deep learning methodologies. Our research empirically views this problem as a temporal action segmentation (TAS) task in computer vision, which aims to segment an untrimmed video at a frame-wise level. Here, we propose a Prompt-enhanced hierarchical Transformer (PhiTrans) that integrates three indispensable modules, including a textual prompt-based Video Features Extractor (VFE), a transformer-based Action Segmentation Executor (ASE), and a regression-based Prediction Refinement Calibrator (PRC). The backbone of the model preferentially derives from applications in three approved public datasets (GTEA, 50Salads, and Breakfast) collected for TAS tasks, which accounts for the excavation of the segmentation pipeline on the CPR dataset. In general, we unprecedentedly probe into a feasible pipeline that genuinely elevates the CPR instruction qualification via action segmentation in conjunction with cutting-edge deep learning techniques. Associated experiments advocate our implementation with multiple metrics surpassing 91.0%.
Mixed-UNet: Refined Class Activation Mapping for Weakly-Supervised Semantic Segmentation with Multi-scale Inference
May 06, 2022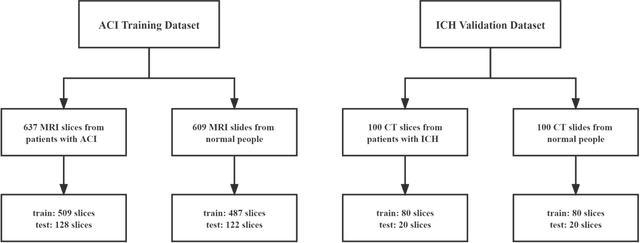
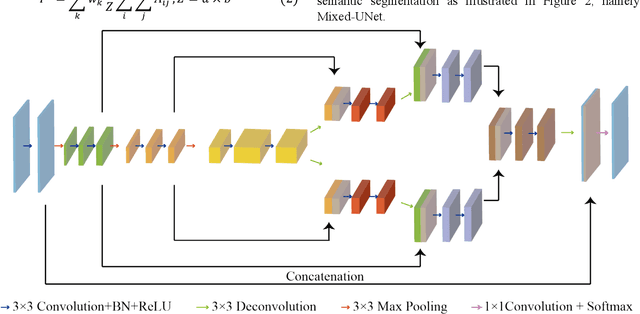
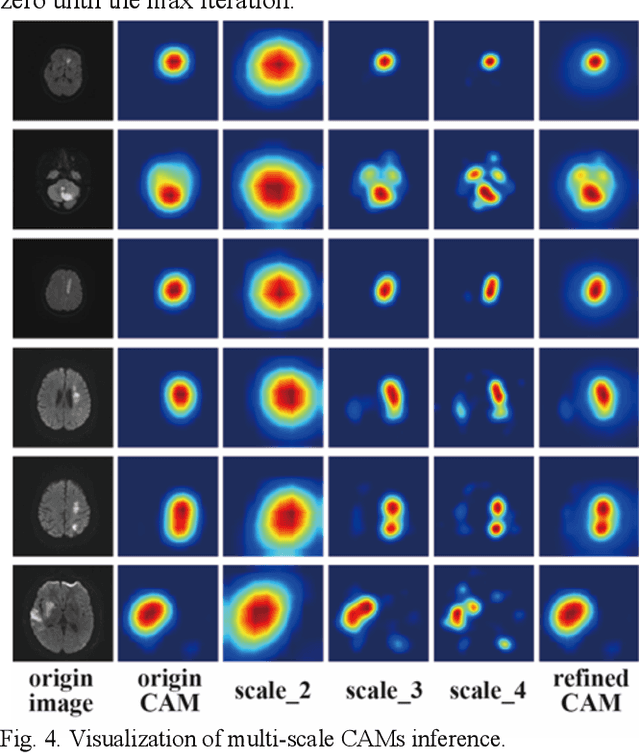
Deep learning techniques have shown great potential in medical image processing, particularly through accurate and reliable image segmentation on magnetic resonance imaging (MRI) scans or computed tomography (CT) scans, which allow the localization and diagnosis of lesions. However, training these segmentation models requires a large number of manually annotated pixel-level labels, which are time-consuming and labor-intensive, in contrast to image-level labels that are easier to obtain. It is imperative to resolve this problem through weakly-supervised semantic segmentation models using image-level labels as supervision since it can significantly reduce human annotation efforts. Most of the advanced solutions exploit class activation mapping (CAM). However, the original CAMs rarely capture the precise boundaries of lesions. In this study, we propose the strategy of multi-scale inference to refine CAMs by reducing the detail loss in single-scale reasoning. For segmentation, we develop a novel model named Mixed-UNet, which has two parallel branches in the decoding phase. The results can be obtained after fusing the extracted features from two branches. We evaluate the designed Mixed-UNet against several prevalent deep learning-based segmentation approaches on our dataset collected from the local hospital and public datasets. The validation results demonstrate that our model surpasses available methods under the same supervision level in the segmentation of various lesions from brain imaging.