 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDVGT-2: Vision-Geometry-Action Model for Autonomous Driving at Scale
Apr 01, 2026End-to-end autonomous driving has evolved from the conventional paradigm based on sparse perception into vision-language-action (VLA) models, which focus on learning language descriptions as an auxiliary task to facilitate planning. In this paper, we propose an alternative Vision-Geometry-Action (VGA) paradigm that advocates dense 3D geometry as the critical cue for autonomous driving. As vehicles operate in a 3D world, we think dense 3D geometry provides the most comprehensive information for decision-making. However, most existing geometry reconstruction methods (e.g., DVGT) rely on computationally expensive batch processing of multi-frame inputs and cannot be applied to online planning. To address this, we introduce a streaming Driving Visual Geometry Transformer (DVGT-2), which processes inputs in an online manner and jointly outputs dense geometry and trajectory planning for the current frame. We employ temporal causal attention and cache historical features to support on-the-fly inference. To further enhance efficiency, we propose a sliding-window streaming strategy and use historical caches within a certain interval to avoid repetitive computations. Despite the faster speed, DVGT-2 achieves superior geometry reconstruction performance on various datasets. The same trained DVGT-2 can be directly applied to planning across diverse camera configurations without fine-tuning, including closed-loop NAVSIM and open-loop nuScenes benchmarks.
NS-VLA: Towards Neuro-Symbolic Vision-Language-Action Models
Mar 10, 2026Vision-Language-Action (VLA) models are formulated to ground instructions in visual context and generate action sequences for robotic manipulation. Despite recent progress, VLA models still face challenges in learning related and reusable primitives, reducing reliance on large-scale data and complex architectures, and enabling exploration beyond demonstrations. To address these challenges, we propose a novel Neuro-Symbolic Vision-Language-Action (NS-VLA) framework via online reinforcement learning (RL). It introduces a symbolic encoder to embedding vision and language features and extract structured primitives, utilizes a symbolic solver for data-efficient action sequencing, and leverages online RL to optimize generation via expansive exploration. Experiments on robotic manipulation benchmarks demonstrate that NS-VLA outperforms previous methods in both one-shot training and data-perturbed settings, while simultaneously exhibiting superior zero-shot generalizability, high data efficiency and expanded exploration space. Our code is available.
LaST-VLA: Thinking in Latent Spatio-Temporal Space for Vision-Language-Action in Autonomous Driving
Mar 02, 2026While Vision-Language-Action (VLA) models have revolutionized autonomous driving by unifying perception and planning, their reliance on explicit textual Chain-of-Thought (CoT) leads to semantic-perceptual decoupling and perceptual-symbolic conflicts. Recent shifts toward latent reasoning attempt to bypass these bottlenecks by thinking in continuous hidden space. However, without explicit intermediate constraints, standard latent CoT often operates as a physics-agnostic representation. To address this, we propose the Latent Spatio-Temporal VLA (LaST-VLA), a framework shifting the reasoning paradigm from discrete symbolic processing into a physically grounded Latent Spatio-Temporal CoT. By implementing a dual-feature alignment mechanism, we distill geometric constraints from 3D foundation models and dynamic foresight from world models directly into the latent space. Coupled with a progressive SFT training strategy that transitions from feature alignment to trajectory generation, and refined via Reinforcement Learning with Group Relative Policy Optimization (GRPO) to ensure safety and rule compliance. \method~setting a new record on NAVSIM v1 (91.3 PDMS) and NAVSIM v2 (87.1 EPDMS), while excelling in spatial-temporal reasoning on SURDS and NuDynamics benchmarks.
Unleashing VLA Potentials in Autonomous Driving via Explicit Learning from Failures
Mar 01, 2026Vision-Language-Action (VLA) models for autonomous driving often hit a performance plateau during Reinforcement Learning (RL) optimization. This stagnation arises from exploration capabilities constrained by previous Supervised Fine-Tuning (SFT), leading to persistent failures in long-tail scenarios. In these critical situations, all explored actions yield a zero-value driving score. This information-sparse reward signals a failure, yet fails to identify its root cause -- whether it is due to incorrect planning, flawed reasoning, or poor trajectory execution. To address this limitation, we propose VLA with Explicit Learning from Failures (ELF-VLA), a framework that augments RL with structured diagnostic feedback. Instead of relying on a vague scalar reward, our method produces detailed, interpretable reports that identify the specific failure mode. The VLA policy then leverages this explicit feedback to generate a Feedback-Guided Refinement. By injecting these corrected, high-reward samples back into the RL training batch, our approach provides a targeted gradient, which enables the policy to solve critical scenarios that unguided exploration cannot. Extensive experiments demonstrate that our method unlocks the latent capabilities of VLA models, achieving state-of-the-art (SOTA) performance on the public NAVSIM benchmark for overall PDMS, EPDMS score and high-level planning accuracy.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Structural Compositional Function Networks: Interpretable Functional Compositions for Tabular Discovery
Jan 27, 2026Despite the ubiquity of tabular data in high-stakes domains, traditional deep learning architectures often struggle to match the performance of gradient-boosted decision trees while maintaining scientific interpretability. Standard neural networks typically treat features as independent entities, failing to exploit the inherent manifold structural dependencies that define tabular distributions. We propose Structural Compositional Function Networks (StructuralCFN), a novel architecture that imposes a Relation-Aware Inductive Bias via a differentiable structural prior. StructuralCFN explicitly models each feature as a mathematical composition of its counterparts through Differentiable Adaptive Gating, which automatically discovers the optimal activation physics (e.g., attention-style filtering vs. inhibitory polarity) for each relationship. Our framework enables Structured Knowledge Integration, allowing domain-specific relational priors to be injected directly into the architecture to guide discovery. We evaluate StructuralCFN across a rigorous 10-fold cross-validation suite on 18 benchmarks, demonstrating statistically significant improvements (p < 0.05) on scientific and clinical datasets (e.g., Blood Transfusion, Ozone, WDBC). Furthermore, StructuralCFN provides Intrinsic Symbolic Interpretability: it recovers the governing "laws" of the data manifold as human-readable mathematical expressions while maintaining a compact parameter footprint (300--2,500 parameters) that is over an order of magnitude (10x--20x) smaller than standard deep baselines.
VILTA: A VLM-in-the-Loop Adversary for Enhancing Driving Policy Robustness
Jan 19, 2026The safe deployment of autonomous driving (AD) systems is fundamentally hindered by the long-tail problem, where rare yet critical driving scenarios are severely underrepresented in real-world data. Existing solutions including safety-critical scenario generation and closed-loop learning often rely on rule-based heuristics, resampling methods and generative models learned from offline datasets, limiting their ability to produce diverse and novel challenges. While recent works leverage Vision Language Models (VLMs) to produce scene descriptions that guide a separate, downstream model in generating hazardous trajectories for agents, such two-stage framework constrains the generative potential of VLMs, as the diversity of the final trajectories is ultimately limited by the generalization ceiling of the downstream algorithm. To overcome these limitations, we introduce VILTA (VLM-In-the-Loop Trajectory Adversary), a novel framework that integrates a VLM into the closed-loop training of AD agents. Unlike prior works, VILTA actively participates in the training loop by comprehending the dynamic driving environment and strategically generating challenging scenarios through direct, fine-grained editing of surrounding agents' future trajectories. This direct-editing approach fully leverages the VLM's powerful generalization capabilities to create a diverse curriculum of plausible yet challenging scenarios that extend beyond the scope of traditional methods. We demonstrate that our approach substantially enhances the safety and robustness of the resulting AD policy, particularly in its ability to navigate critical long-tail events.
Motion Blur Robust Wheat Pest Damage Detection with Dynamic Fuzzy Feature Fusion
Jan 06, 2026Motion blur caused by camera shake produces ghosting artifacts that substantially degrade edge side object detection. Existing approaches either suppress blur as noise and lose discriminative structure, or apply full image restoration that increases latency and limits deployment on resource constrained devices. We propose DFRCP, a Dynamic Fuzzy Robust Convolutional Pyramid, as a plug in upgrade to YOLOv11 for blur robust detection. DFRCP enhances the YOLOv11 feature pyramid by combining large scale and medium scale features while preserving native representations, and by introducing Dynamic Robust Switch units that adaptively inject fuzzy features to strengthen global perception under jitter. Fuzzy features are synthesized by rotating and nonlinearly interpolating multiscale features, then merged through a transparency convolution that learns a content adaptive trade off between original and fuzzy cues. We further develop a CUDA parallel rotation and interpolation kernel that avoids boundary overflow and delivers more than 400 times speedup, making the design practical for edge deployment. We train with paired supervision on a private wheat pest damage dataset of about 3,500 images, augmented threefold using two blur regimes, uniform image wide motion blur and bounding box confined rotational blur. On blurred test sets, YOLOv11 with DFRCP achieves about 10.4 percent higher accuracy than the YOLOv11 baseline with only a modest training time overhead, reducing the need for manual filtering after data collection.
DVGT: Driving Visual Geometry Transformer
Dec 18, 2025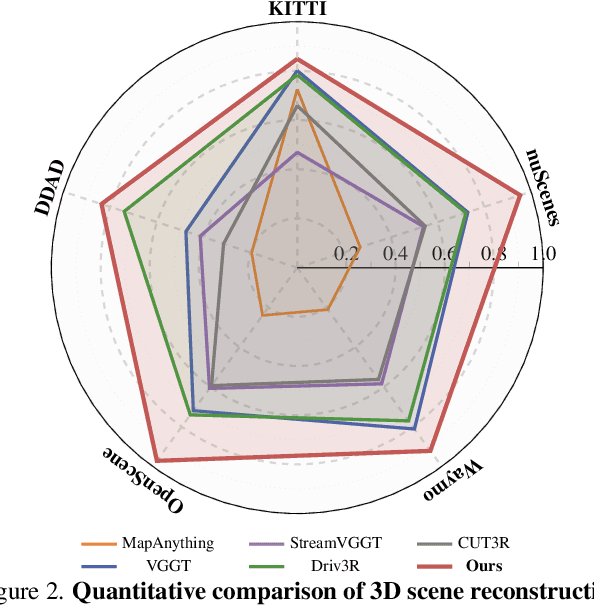
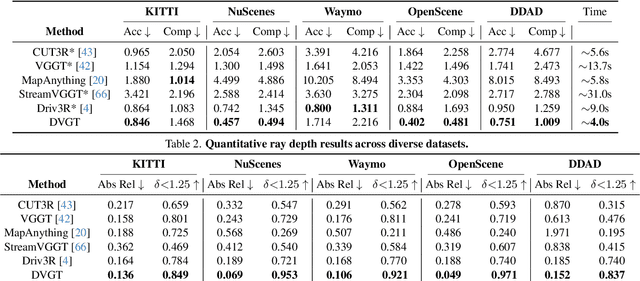
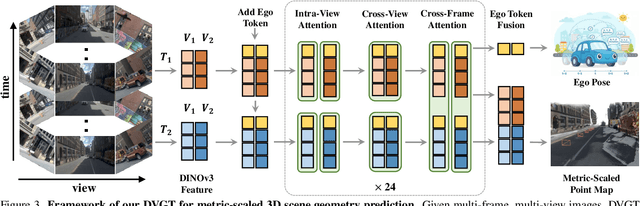
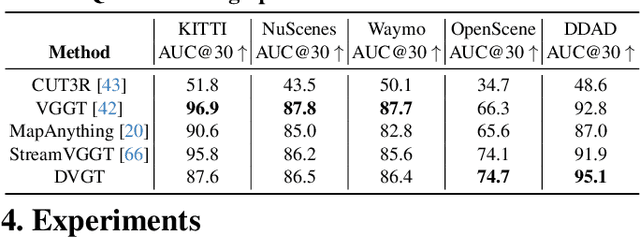
Perceiving and reconstructing 3D scene geometry from visual inputs is crucial for autonomous driving. However, there still lacks a driving-targeted dense geometry perception model that can adapt to different scenarios and camera configurations. To bridge this gap, we propose a Driving Visual Geometry Transformer (DVGT), which reconstructs a global dense 3D point map from a sequence of unposed multi-view visual inputs. We first extract visual features for each image using a DINO backbone, and employ alternating intra-view local attention, cross-view spatial attention, and cross-frame temporal attention to infer geometric relations across images. We then use multiple heads to decode a global point map in the ego coordinate of the first frame and the ego poses for each frame. Unlike conventional methods that rely on precise camera parameters, DVGT is free of explicit 3D geometric priors, enabling flexible processing of arbitrary camera configurations. DVGT directly predicts metric-scaled geometry from image sequences, eliminating the need for post-alignment with external sensors. Trained on a large mixture of driving datasets including nuScenes, OpenScene, Waymo, KITTI, and DDAD, DVGT significantly outperforms existing models on various scenarios. Code is available at https://github.com/wzzheng/DVGT.
Tensor Completion via Monotone Inclusion: Generalized Low-Rank Priors Meet Deep Denoisers
Oct 14, 2025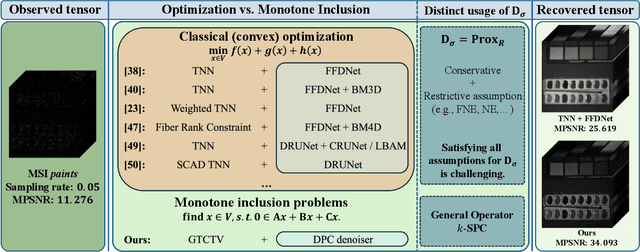
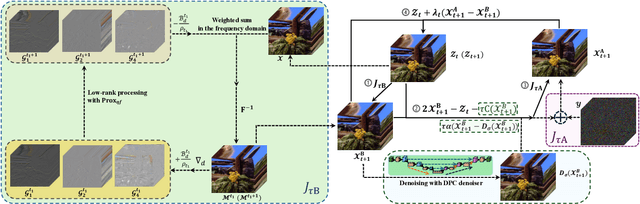

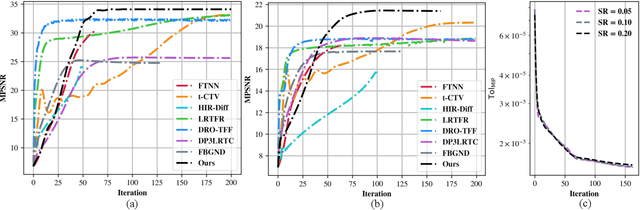
Missing entries in multi dimensional data pose significant challenges for downstream analysis across diverse real world applications. These data are naturally modeled as tensors, and recent completion methods integrating global low rank priors with plug and play denoisers have demonstrated strong empirical performance. However, these approaches often rely on empirical convergence alone or unrealistic assumptions, such as deep denoisers acting as proximal operators of implicit regularizers, which generally does not hold. To address these limitations, we propose a novel tensor completion framework grounded in the monotone inclusion paradigm, which unifies generalized low rank priors with deep pseudo contractive denoisers and extends beyond traditional convex optimization. Building on the Davis Yin splitting scheme, we develop the GTCTV DPC algorithm and rigorously establish its global convergence. Extensive experiments demonstrate that GTCTV DPC consistently outperforms existing methods in both quantitative metrics and visual quality, particularly at low sampling rates.