 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuQuant++: Fine-grained Rotation Enhances Microscaling FP4 Quantization
Apr 21, 2026The MXFP4 microscaling format, which partitions tensors into blocks of 32 elements sharing an E8M0 scaling factor, has emerged as a promising substrate for efficient LLM inference, backed by native hardware support on NVIDIA Blackwell Tensor Cores. However, activation outliers pose a unique challenge under this format: a single outlier inflates the shared block scale, compressing the effective dynamic range of the remaining elements and causing significant quantization error. Existing rotation-based remedies, including randomized Hadamard and learnable rotations, are data-agnostic and therefore unable to specifically target the channels where outliers concentrate. We propose DuQuant++, which adapts the outlier-aware fine-grained rotation of DuQuant to the MXFP4 format by aligning the rotation block size with the microscaling group size (B{=}32). Because each MXFP4 group possesses an independent scaling factor, the cross-block variance issue that necessitates dual rotations and a zigzag permutation in the original DuQuant becomes irrelevant, enabling DuQuant++ to replace the entire pipeline with a single outlier-aware rotation, which halves the online rotation cost while simultaneously smoothing the weight distribution. Extensive experiments on the LLaMA-3 family under MXFP4 W4A4 quantization show that DuQuant++ consistently achieves state-of-the-art performance. Our code is available at https://github.com/Hsu1023/DuQuant-v2.
Prune as You Generate: Online Rollout Pruning for Faster and Better RLVR
Mar 25, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has significantly advanced the reasoning capabilities of Large Language Models (LLMs). However, methods such as GRPO and DAPO suffer from substantial computational cost, since they rely on sampling many rollouts for each prompt. Moreover, in RLVR the relative advantage is often sparse: many samples become nearly all-correct or all-incorrect, yielding low within-group reward variance and thus weak learning signals. In this paper, we introduce arrol (Accelerating RLVR via online Rollout Pruning), an online rollout pruning method that prunes rollouts during generation while explicitly steering the surviving ones more correctness-balanced to enhance learning signals. Specifically, arrol trains a lightweight quality head on-the-fly to predict the success probability of partial rollouts and uses it to make early pruning decisions. The learned quality head can further weigh candidates to improve inference accuracy during test-time scaling. To improve efficiency, we present a system design that prunes rollouts inside the inference engine and re-batches the remaining ones for log-probability computation and policy updates. Across GRPO and DAPO on Qwen-3 and LLaMA-3.2 models (1B-8B), arrol improves average accuracy by +2.30 to +2.99 while achieving up to 1.7x training speedup, and yielding up to +8.33 additional gains in average accuracy in test-time scaling. The code is available at https://github.com/Hsu1023/ARRoL.
RoboChemist: Long-Horizon and Safety-Compliant Robotic Chemical Experimentation
Sep 10, 2025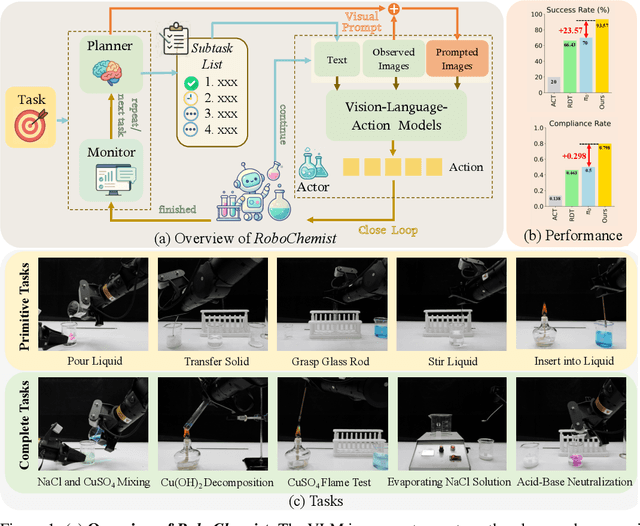



Robotic chemists promise to both liberate human experts from repetitive tasks and accelerate scientific discovery, yet remain in their infancy. Chemical experiments involve long-horizon procedures over hazardous and deformable substances, where success requires not only task completion but also strict compliance with experimental norms. To address these challenges, we propose \textit{RoboChemist}, a dual-loop framework that integrates Vision-Language Models (VLMs) with Vision-Language-Action (VLA) models. Unlike prior VLM-based systems (e.g., VoxPoser, ReKep) that rely on depth perception and struggle with transparent labware, and existing VLA systems (e.g., RDT, pi0) that lack semantic-level feedback for complex tasks, our method leverages a VLM to serve as (1) a planner to decompose tasks into primitive actions, (2) a visual prompt generator to guide VLA models, and (3) a monitor to assess task success and regulatory compliance. Notably, we introduce a VLA interface that accepts image-based visual targets from the VLM, enabling precise, goal-conditioned control. Our system successfully executes both primitive actions and complete multi-step chemistry protocols. Results show 23.57% higher average success rate and a 0.298 average increase in compliance rate over state-of-the-art VLA baselines, while also demonstrating strong generalization to objects and tasks.
TA-VLA: Elucidating the Design Space of Torque-aware Vision-Language-Action Models
Sep 09, 2025Many robotic manipulation tasks require sensing and responding to force signals such as torque to assess whether the task has been successfully completed and to enable closed-loop control. However, current Vision-Language-Action (VLA) models lack the ability to integrate such subtle physical feedback. In this work, we explore Torque-aware VLA models, aiming to bridge this gap by systematically studying the design space for incorporating torque signals into existing VLA architectures. We identify and evaluate several strategies, leading to three key findings. First, introducing torque adapters into the decoder consistently outperforms inserting them into the encoder.Third, inspired by joint prediction and planning paradigms in autonomous driving, we propose predicting torque as an auxiliary output, which further improves performance. This strategy encourages the model to build a physically grounded internal representation of interaction dynamics. Extensive quantitative and qualitative experiments across contact-rich manipulation benchmarks validate our findings.
ANNIE: Be Careful of Your Robots
Sep 03, 2025



The integration of vision-language-action (VLA) models into embodied AI (EAI) robots is rapidly advancing their ability to perform complex, long-horizon tasks in humancentric environments. However, EAI systems introduce critical security risks: a compromised VLA model can directly translate adversarial perturbations on sensory input into unsafe physical actions. Traditional safety definitions and methodologies from the machine learning community are no longer sufficient. EAI systems raise new questions, such as what constitutes safety, how to measure it, and how to design effective attack and defense mechanisms in physically grounded, interactive settings. In this work, we present the first systematic study of adversarial safety attacks on embodied AI systems, grounded in ISO standards for human-robot interactions. We (1) formalize a principled taxonomy of safety violations (critical, dangerous, risky) based on physical constraints such as separation distance, velocity, and collision boundaries; (2) introduce ANNIEBench, a benchmark of nine safety-critical scenarios with 2,400 video-action sequences for evaluating embodied safety; and (3) ANNIE-Attack, a task-aware adversarial framework with an attack leader model that decomposes long-horizon goals into frame-level perturbations. Our evaluation across representative EAI models shows attack success rates exceeding 50% across all safety categories. We further demonstrate sparse and adaptive attack strategies and validate the real-world impact through physical robot experiments. These results expose a previously underexplored but highly consequential attack surface in embodied AI systems, highlighting the urgent need for security-driven defenses in the physical AI era. Code is available at https://github.com/RLCLab/Annie.
Quantization Meets dLLMs: A Systematic Study of Post-training Quantization for Diffusion LLMs
Aug 20, 2025Recent advances in diffusion large language models (dLLMs) have introduced a promising alternative to autoregressive (AR) LLMs for natural language generation tasks, leveraging full attention and denoising-based decoding strategies. However, the deployment of these models on edge devices remains challenging due to their massive parameter scale and high resource demands. While post-training quantization (PTQ) has emerged as a widely adopted technique for compressing AR LLMs, its applicability to dLLMs remains largely unexplored. In this work, we present the first systematic study on quantizing diffusion-based language models. We begin by identifying the presence of activation outliers, characterized by abnormally large activation values that dominate the dynamic range. These outliers pose a key challenge to low-bit quantization, as they make it difficult to preserve precision for the majority of values. More importantly, we implement state-of-the-art PTQ methods and conduct a comprehensive evaluation across multiple task types and model variants. Our analysis is structured along four key dimensions: bit-width, quantization method, task category, and model type. Through this multi-perspective evaluation, we offer practical insights into the quantization behavior of dLLMs under different configurations. We hope our findings provide a foundation for future research in efficient dLLM deployment. All codes and experimental setups will be released to support the community.
Learning Cocoercive Conservative Denoisers via Helmholtz Decomposition for Poisson Inverse Problems
May 13, 2025Plug-and-play (PnP) methods with deep denoisers have shown impressive results in imaging problems. They typically require strong convexity or smoothness of the fidelity term and a (residual) non-expansive denoiser for convergence. These assumptions, however, are violated in Poisson inverse problems, and non-expansiveness can hinder denoising performance. To address these challenges, we propose a cocoercive conservative (CoCo) denoiser, which may be (residual) expansive, leading to improved denoising. By leveraging the generalized Helmholtz decomposition, we introduce a novel training strategy that combines Hamiltonian regularization to promote conservativeness and spectral regularization to ensure cocoerciveness. We prove that CoCo denoiser is a proximal operator of a weakly convex function, enabling a restoration model with an implicit weakly convex prior. The global convergence of PnP methods to a stationary point of this restoration model is established. Extensive experimental results demonstrate that our approach outperforms closely related methods in both visual quality and quantitative metrics.
RTLMarker: Protecting LLM-Generated RTL Copyright via a Hardware Watermarking Framework
Jan 05, 2025



Recent advances of large language models in the field of Verilog generation have raised several ethical and security concerns, such as code copyright protection and dissemination of malicious code. Researchers have employed watermarking techniques to identify codes generated by large language models. However, the existing watermarking works fail to protect RTL code copyright due to the significant syntactic and semantic differences between RTL code and software code in languages such as Python. This paper proposes a hardware watermarking framework RTLMarker that embeds watermarks into RTL code and deeper into the synthesized netlist. We propose a set of rule-based Verilog code transformations , ensuring the watermarked RTL code's syntactic and semantic correctness. In addition, we consider an inherent tradeoff between watermark transparency and watermark effectiveness and jointly optimize them. The results demonstrate RTLMarker's superiority over the baseline in RTL code watermarking.
Natural language is not enough: Benchmarking multi-modal generative AI for Verilog generation
Jul 11, 2024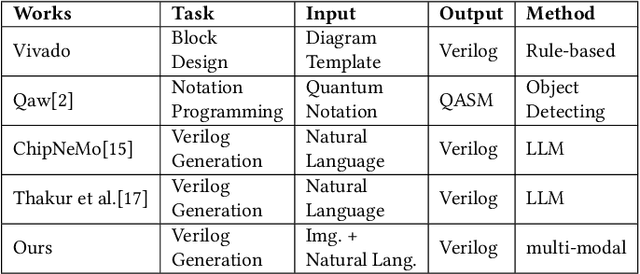
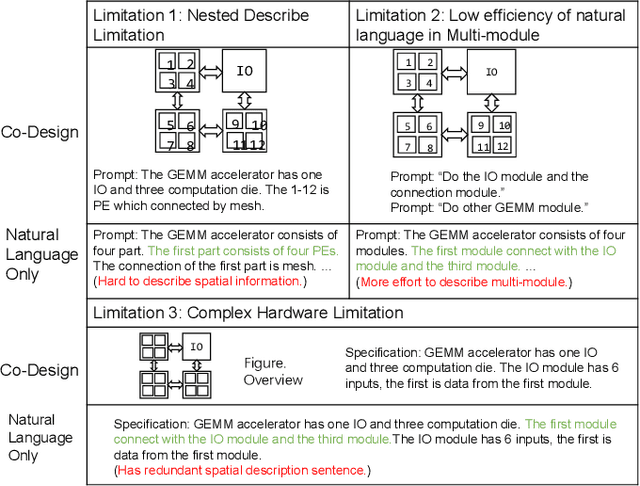
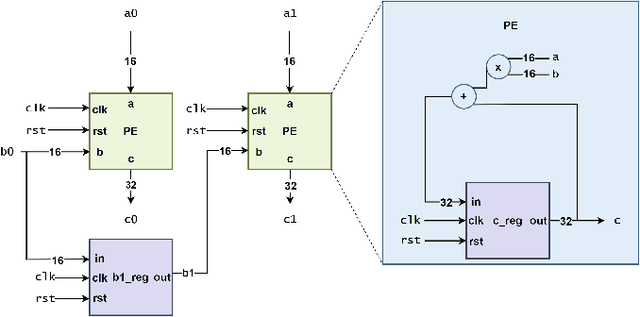
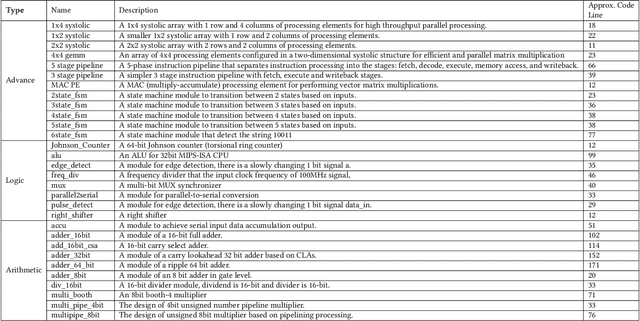
Natural language interfaces have exhibited considerable potential in the automation of Verilog generation derived from high-level specifications through the utilization of large language models, garnering significant attention. Nevertheless, this paper elucidates that visual representations contribute essential contextual information critical to design intent for hardware architectures possessing spatial complexity, potentially surpassing the efficacy of natural-language-only inputs. Expanding upon this premise, our paper introduces an open-source benchmark for multi-modal generative models tailored for Verilog synthesis from visual-linguistic inputs, addressing both singular and complex modules. Additionally, we introduce an open-source visual and natural language Verilog query language framework to facilitate efficient and user-friendly multi-modal queries. To evaluate the performance of the proposed multi-modal hardware generative AI in Verilog generation tasks, we compare it with a popular method that relies solely on natural language. Our results demonstrate a significant accuracy improvement in the multi-modal generated Verilog compared to queries based solely on natural language. We hope to reveal a new approach to hardware design in the large-hardware-design-model era, thereby fostering a more diversified and productive approach to hardware design.
Rotation and Permutation for Advanced Outlier Management and Efficient Quantization of LLMs
Jun 03, 2024



Quantizing large language models (LLMs) presents significant challenges, primarily due to outlier activations that compromise the efficiency of low-bit representation. Traditional approaches mainly focus on solving Normal Outliers-activations with consistently high magnitudes across all tokens. However, these techniques falter when dealing with Massive Outliers, which are significantly higher in value and often cause substantial performance losses during low-bit quantization. In this study, we propose DuQuant, an innovative quantization strategy employing rotation and permutation transformations to more effectively eliminate both types of outliers. Initially, DuQuant constructs rotation matrices informed by specific outlier dimensions, redistributing these outliers across adjacent channels within different rotation blocks. Subsequently, a zigzag permutation is applied to ensure a balanced distribution of outliers among blocks, minimizing block-wise variance. An additional rotation further enhances the smoothness of the activation landscape, thereby improving model performance. DuQuant streamlines the quantization process and demonstrates superior outlier management, achieving top-tier results in multiple tasks with various LLM architectures even under 4-bit weight-activation quantization. Our code is available at https://github.com/Hsu1023/DuQuant.