 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Control as Optimization: Time Unconditional Flow Matching for Adaptive and Robust Robotic Control
Mar 18, 2026Diffusion models and flow matching have become a cornerstone of robotic imitation learning, yet they suffer from a structural inefficiency where inference is often bound to a fixed integration schedule that is agnostic to state complexity. This paradigm forces the policy to expend the same computational budget on trivial motions as it does on complex tasks. We introduce Generative Control as Optimization (GeCO), a time-unconditional framework that transforms action synthesis from trajectory integration into iterative optimization. GeCO learns a stationary velocity field in the action-sequence space where expert behaviors form stable attractors. Consequently, test-time inference becomes an adaptive process that allocates computation based on convergence--exiting early for simple states while refining longer for difficult ones. Furthermore, this stationary geometry yields an intrinsic, training-free safety signal, as the field norm at the optimized action serves as a robust out-of-distribution (OOD) detector, remaining low for in-distribution states while significantly increasing for anomalies. We validate GeCO on standard simulation benchmarks and demonstrate seamless scaling to pi0-series Vision-Language-Action (VLA) models. As a plug-and-play replacement for standard flow-matching heads, GeCO improves success rates and efficiency with an optimization-native mechanism for safe deployment. Video and code can be found at https://hrh6666.github.io/GeCO/
TTT-Parkour: Rapid Test-Time Training for Perceptive Robot Parkour
Feb 02, 2026Achieving highly dynamic humanoid parkour on unseen, complex terrains remains a challenge in robotics. Although general locomotion policies demonstrate capabilities across broad terrain distributions, they often struggle with arbitrary and highly challenging environments. To overcome this limitation, we propose a real-to-sim-to-real framework that leverages rapid test-time training (TTT) on novel terrains, significantly enhancing the robot's capability to traverse extremely difficult geometries. We adopt a two-stage end-to-end learning paradigm: a policy is first pre-trained on diverse procedurally generated terrains, followed by rapid fine-tuning on high-fidelity meshes reconstructed from real-world captures. Specifically, we develop a feed-forward, efficient, and high-fidelity geometry reconstruction pipeline using RGB-D inputs, ensuring both speed and quality during test-time training. We demonstrate that TTT-Parkour empowers humanoid robots to master complex obstacles, including wedges, stakes, boxes, trapezoids, and narrow beams. The whole pipeline of capturing, reconstructing, and test-time training requires less than 10 minutes on most tested terrains. Extensive experiments show that the policy after test-time training exhibits robust zero-shot sim-to-real transfer capability.
DIMO: Diverse 3D Motion Generation for Arbitrary Objects
Nov 10, 2025
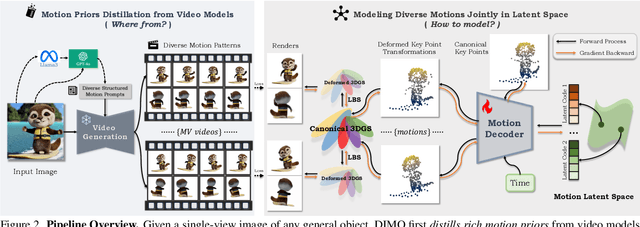
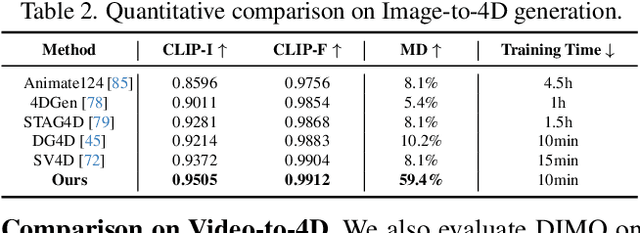

We present DIMO, a generative approach capable of generating diverse 3D motions for arbitrary objects from a single image. The core idea of our work is to leverage the rich priors in well-trained video models to extract the common motion patterns and then embed them into a shared low-dimensional latent space. Specifically, we first generate multiple videos of the same object with diverse motions. We then embed each motion into a latent vector and train a shared motion decoder to learn the distribution of motions represented by a structured and compact motion representation, i.e., neural key point trajectories. The canonical 3D Gaussians are then driven by these key points and fused to model the geometry and appearance. During inference time with learned latent space, we can instantly sample diverse 3D motions in a single-forward pass and support several interesting applications including 3D motion interpolation and language-guided motion generation. Our project page is available at https://linzhanm.github.io/dimo.
VR-Robo: A Real-to-Sim-to-Real Framework for Visual Robot Navigation and Locomotion
Feb 03, 2025


Recent success in legged robot locomotion is attributed to the integration of reinforcement learning and physical simulators. However, these policies often encounter challenges when deployed in real-world environments due to sim-to-real gaps, as simulators typically fail to replicate visual realism and complex real-world geometry. Moreover, the lack of realistic visual rendering limits the ability of these policies to support high-level tasks requiring RGB-based perception like ego-centric navigation. This paper presents a Real-to-Sim-to-Real framework that generates photorealistic and physically interactive "digital twin" simulation environments for visual navigation and locomotion learning. Our approach leverages 3D Gaussian Splatting (3DGS) based scene reconstruction from multi-view images and integrates these environments into simulations that support ego-centric visual perception and mesh-based physical interactions. To demonstrate its effectiveness, we train a reinforcement learning policy within the simulator to perform a visual goal-tracking task. Extensive experiments show that our framework achieves RGB-only sim-to-real policy transfer. Additionally, our framework facilitates the rapid adaptation of robot policies with effective exploration capability in complex new environments, highlighting its potential for applications in households and factories.
Robust Robot Walker: Learning Agile Locomotion over Tiny Traps
Sep 12, 2024
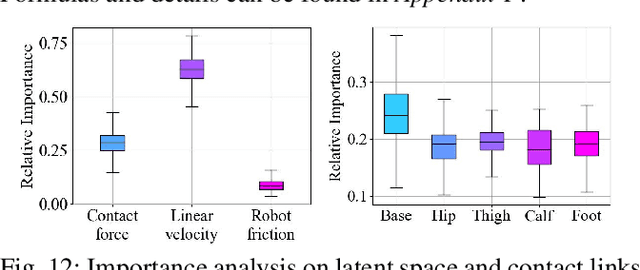


Quadruped robots must exhibit robust walking capabilities in practical applications. In this work, we propose a novel approach that enables quadruped robots to pass various small obstacles, or "tiny traps". Existing methods often rely on exteroceptive sensors, which can be unreliable for detecting such tiny traps. To overcome this limitation, our approach focuses solely on proprioceptive inputs. We introduce a two-stage training framework incorporating a contact encoder and a classification head to learn implicit representations of different traps. Additionally, we design a set of tailored reward functions to improve both the stability of training and the ease of deployment for goal-tracking tasks. To benefit further research, we design a new benchmark for tiny trap task. Extensive experiments in both simulation and real-world settings demonstrate the effectiveness and robustness of our method. Project Page: https://robust-robot-walker.github.io/
Let Occ Flow: Self-Supervised 3D Occupancy Flow Prediction
Jul 10, 2024



Accurate perception of the dynamic environment is a fundamental task for autonomous driving and robot systems. This paper introduces Let Occ Flow, the first self-supervised work for joint 3D occupancy and occupancy flow prediction using only camera inputs, eliminating the need for 3D annotations. Utilizing TPV for unified scene representation and deformable attention layers for feature aggregation, our approach incorporates a backward-forward temporal attention module to capture dynamic object dependencies, followed by a 3D refine module for fine-gained volumetric representation. Besides, our method extends differentiable rendering to 3D volumetric flow fields, leveraging zero-shot 2D segmentation and optical flow cues for dynamic decomposition and motion optimization. Extensive experiments on nuScenes and KITTI datasets demonstrate the competitive performance of our approach over prior state-of-the-art methods.
Instruct 4D-to-4D: Editing 4D Scenes as Pseudo-3D Scenes Using 2D Diffusion
Jun 13, 2024This paper proposes Instruct 4D-to-4D that achieves 4D awareness and spatial-temporal consistency for 2D diffusion models to generate high-quality instruction-guided dynamic scene editing results. Traditional applications of 2D diffusion models in dynamic scene editing often result in inconsistency, primarily due to their inherent frame-by-frame editing methodology. Addressing the complexities of extending instruction-guided editing to 4D, our key insight is to treat a 4D scene as a pseudo-3D scene, decoupled into two sub-problems: achieving temporal consistency in video editing and applying these edits to the pseudo-3D scene. Following this, we first enhance the Instruct-Pix2Pix (IP2P) model with an anchor-aware attention module for batch processing and consistent editing. Additionally, we integrate optical flow-guided appearance propagation in a sliding window fashion for more precise frame-to-frame editing and incorporate depth-based projection to manage the extensive data of pseudo-3D scenes, followed by iterative editing to achieve convergence. We extensively evaluate our approach in various scenes and editing instructions, and demonstrate that it achieves spatially and temporally consistent editing results, with significantly enhanced detail and sharpness over the prior art. Notably, Instruct 4D-to-4D is general and applicable to both monocular and challenging multi-camera scenes. Code and more results are available at immortalco.github.io/Instruct-4D-to-4D.
Rotation and Permutation for Advanced Outlier Management and Efficient Quantization of LLMs
Jun 03, 2024



Quantizing large language models (LLMs) presents significant challenges, primarily due to outlier activations that compromise the efficiency of low-bit representation. Traditional approaches mainly focus on solving Normal Outliers-activations with consistently high magnitudes across all tokens. However, these techniques falter when dealing with Massive Outliers, which are significantly higher in value and often cause substantial performance losses during low-bit quantization. In this study, we propose DuQuant, an innovative quantization strategy employing rotation and permutation transformations to more effectively eliminate both types of outliers. Initially, DuQuant constructs rotation matrices informed by specific outlier dimensions, redistributing these outliers across adjacent channels within different rotation blocks. Subsequently, a zigzag permutation is applied to ensure a balanced distribution of outliers among blocks, minimizing block-wise variance. An additional rotation further enhances the smoothness of the activation landscape, thereby improving model performance. DuQuant streamlines the quantization process and demonstrates superior outlier management, achieving top-tier results in multiple tasks with various LLM architectures even under 4-bit weight-activation quantization. Our code is available at https://github.com/Hsu1023/DuQuant.
Relightable and Animatable Neural Avatar from Sparse-View Video
Aug 17, 2023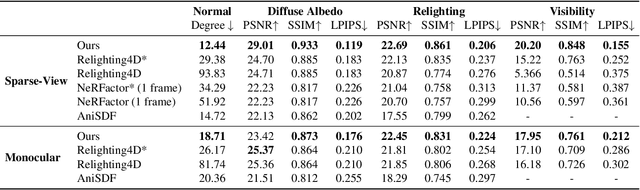
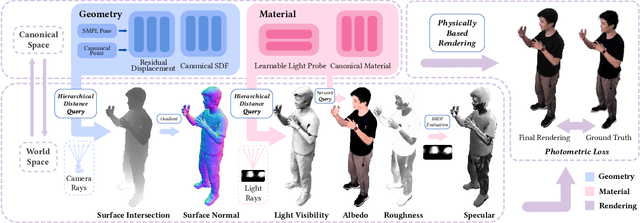
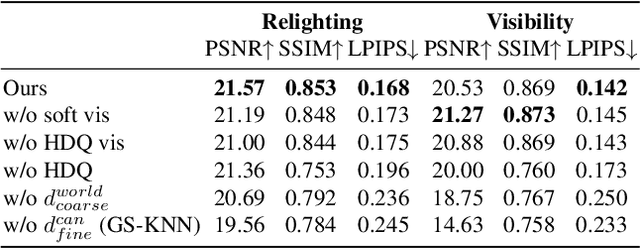
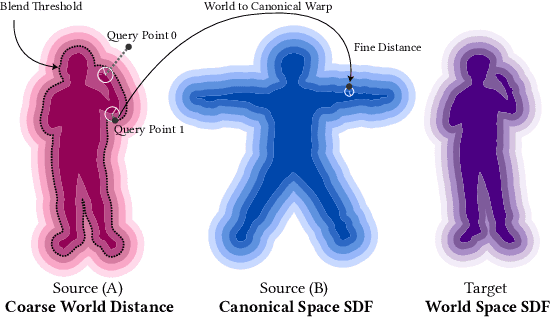
This paper tackles the challenge of creating relightable and animatable neural avatars from sparse-view (or even monocular) videos of dynamic humans under unknown illumination. Compared to studio environments, this setting is more practical and accessible but poses an extremely challenging ill-posed problem. Previous neural human reconstruction methods are able to reconstruct animatable avatars from sparse views using deformed Signed Distance Fields (SDF) but cannot recover material parameters for relighting. While differentiable inverse rendering-based methods have succeeded in material recovery of static objects, it is not straightforward to extend them to dynamic humans as it is computationally intensive to compute pixel-surface intersection and light visibility on deformed SDFs for inverse rendering. To solve this challenge, we propose a Hierarchical Distance Query (HDQ) algorithm to approximate the world space distances under arbitrary human poses. Specifically, we estimate coarse distances based on a parametric human model and compute fine distances by exploiting the local deformation invariance of SDF. Based on the HDQ algorithm, we leverage sphere tracing to efficiently estimate the surface intersection and light visibility. This allows us to develop the first system to recover animatable and relightable neural avatars from sparse view (or monocular) inputs. Experiments demonstrate that our approach is able to produce superior results compared to state-of-the-art methods. Our code will be released for reproducibility.
Painting 3D Nature in 2D: View Synthesis of Natural Scenes from a Single Semantic Mask
Feb 14, 2023We introduce a novel approach that takes a single semantic mask as input to synthesize multi-view consistent color images of natural scenes, trained with a collection of single images from the Internet. Prior works on 3D-aware image synthesis either require multi-view supervision or learning category-level prior for specific classes of objects, which can hardly work for natural scenes. Our key idea to solve this challenging problem is to use a semantic field as the intermediate representation, which is easier to reconstruct from an input semantic mask and then translate to a radiance field with the assistance of off-the-shelf semantic image synthesis models. Experiments show that our method outperforms baseline methods and produces photorealistic, multi-view consistent videos of a variety of natural scenes.