 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeETP-R1: Evolving Topological Planning with Reinforcement Fine-tuning for Vision-Language Navigation in Continuous Environments
Dec 24, 2025Vision-Language Navigation in Continuous Environments (VLN-CE) requires an embodied agent to navigate towards target in continuous environments, following natural language instructions. While current graph-based methods offer an efficient, structured approach by abstracting the environment into a topological map and simplifying the action space to waypoint selection, they lag behind methods based on Large Vision-Language Models (LVLMs) in leveraging large-scale data and advanced training paradigms. In this paper, we try to bridge this gap by introducing ETP-R1, a framework that applies the paradigm of scaling up data and Reinforcement Fine-Tuning (RFT) to a graph-based VLN-CE model. To build a strong foundation, we first construct a high-quality, large-scale pretraining dataset using the Gemini API. This dataset consists of diverse, low-hallucination instructions for topological trajectories, providing rich supervision for our graph-based policy to map language to topological paths. This foundation is further strengthened by unifying data from both R2R and RxR tasks for joint pretraining. Building on this, we introduce a three-stage training paradigm, which culminates in the first application of closed-loop, online RFT to a graph-based VLN-CE model, powered by the Group Relative Policy Optimization (GRPO) algorithm. Extensive experiments demonstrate that our approach is highly effective, establishing new state-of-the-art performance across all major metrics on both the R2R-CE and RxR-CE benchmarks. Our code is available at https://github.com/Cepillar/ETP-R1.
Discrete Diffusion VLA: Bringing Discrete Diffusion to Action Decoding in Vision-Language-Action Policies
Aug 27, 2025Vision-Language-Action (VLA) models adapt large vision-language backbones to map images and instructions to robot actions. However, prevailing VLA decoders either generate actions autoregressively in a fixed left-to-right order or attach continuous diffusion or flow matching heads outside the backbone, demanding specialized training and iterative sampling that hinder a unified, scalable architecture. We present Discrete Diffusion VLA, a single-transformer policy that models discretized action chunks with discrete diffusion and is trained with the same cross-entropy objective as the VLM backbone. The design retains diffusion's progressive refinement paradigm while remaining natively compatible with the discrete token interface of VLMs. Our method achieves an adaptive decoding order that resolves easy action elements before harder ones and uses secondary remasking to revisit uncertain predictions across refinement rounds, which improves consistency and enables robust error correction. This unified decoder preserves pretrained vision language priors, supports parallel decoding, breaks the autoregressive bottleneck, and reduces the number of function evaluations. Discrete Diffusion VLA achieves 96.3% avg. SR on LIBERO, 71.2% visual matching on SimplerEnv Fractal and 49.3% overall on SimplerEnv Bridge, improving over both autoregressive and continuous diffusion baselines. These findings indicate that discrete-diffusion action decoder supports precise action modeling and consistent training, laying groundwork for scaling VLA to larger models and datasets.
Dynamic Mixture of Progressive Parameter-Efficient Expert Library for Lifelong Robot Learning
Jun 06, 2025A generalist agent must continuously learn and adapt throughout its lifetime, achieving efficient forward transfer while minimizing catastrophic forgetting. Previous work within the dominant pretrain-then-finetune paradigm has explored parameter-efficient fine-tuning for single-task adaptation, effectively steering a frozen pretrained model with a small number of parameters. However, in the context of lifelong learning, these methods rely on the impractical assumption of a test-time task identifier and restrict knowledge sharing among isolated adapters. To address these limitations, we propose Dynamic Mixture of Progressive Parameter-Efficient Expert Library (DMPEL) for lifelong robot learning. DMPEL progressively learn a low-rank expert library and employs a lightweight router to dynamically combine experts into an end-to-end policy, facilitating flexible behavior during lifelong adaptation. Moreover, by leveraging the modular structure of the fine-tuned parameters, we introduce coefficient replay to guide the router in accurately retrieving frozen experts for previously encountered tasks, thereby mitigating catastrophic forgetting. This method is significantly more storage- and computationally-efficient than applying demonstration replay to the entire policy. Extensive experiments on the lifelong manipulation benchmark LIBERO demonstrate that our framework outperforms state-of-the-art lifelong learning methods in success rates across continual adaptation, while utilizing minimal trainable parameters and storage.
Scale Disparity of Instances in Interactive Point Cloud Segmentation
Jul 19, 2024Interactive point cloud segmentation has become a pivotal task for understanding 3D scenes, enabling users to guide segmentation models with simple interactions such as clicks, therefore significantly reducing the effort required to tailor models to diverse scenarios and new categories. However, in the realm of interactive segmentation, the meaning of instance diverges from that in instance segmentation, because users might desire to segment instances of both thing and stuff categories that vary greatly in scale. Existing methods have focused on thing categories, neglecting the segmentation of stuff categories and the difficulties arising from scale disparity. To bridge this gap, we propose ClickFormer, an innovative interactive point cloud segmentation model that accurately segments instances of both thing and stuff categories. We propose a query augmentation module to augment click queries by a global query sampling strategy, thus maintaining consistent performance across different instance scales. Additionally, we employ global attention in the query-voxel transformer to mitigate the risk of generating false positives, along with several other network structure improvements to further enhance the model's segmentation performance. Experiments demonstrate that ClickFormer outperforms existing interactive point cloud segmentation methods across both indoor and outdoor datasets, providing more accurate segmentation results with fewer user clicks in an open-world setting.
Let Occ Flow: Self-Supervised 3D Occupancy Flow Prediction
Jul 10, 2024



Accurate perception of the dynamic environment is a fundamental task for autonomous driving and robot systems. This paper introduces Let Occ Flow, the first self-supervised work for joint 3D occupancy and occupancy flow prediction using only camera inputs, eliminating the need for 3D annotations. Utilizing TPV for unified scene representation and deformable attention layers for feature aggregation, our approach incorporates a backward-forward temporal attention module to capture dynamic object dependencies, followed by a 3D refine module for fine-gained volumetric representation. Besides, our method extends differentiable rendering to 3D volumetric flow fields, leveraging zero-shot 2D segmentation and optical flow cues for dynamic decomposition and motion optimization. Extensive experiments on nuScenes and KITTI datasets demonstrate the competitive performance of our approach over prior state-of-the-art methods.
PanopticRecon: Leverage Open-vocabulary Instance Segmentation for Zero-shot Panoptic Reconstruction
Jul 01, 2024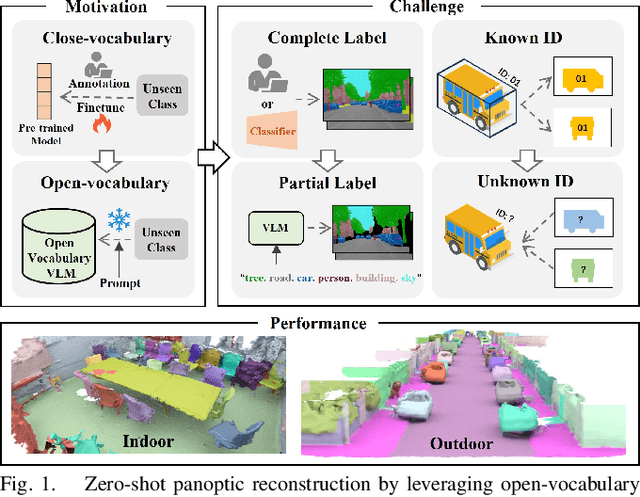
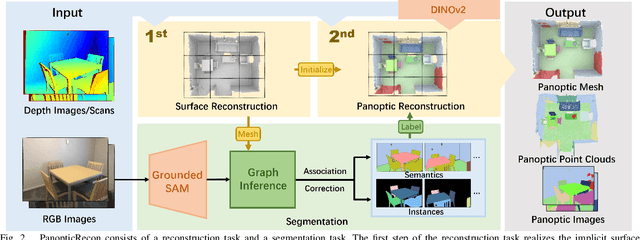
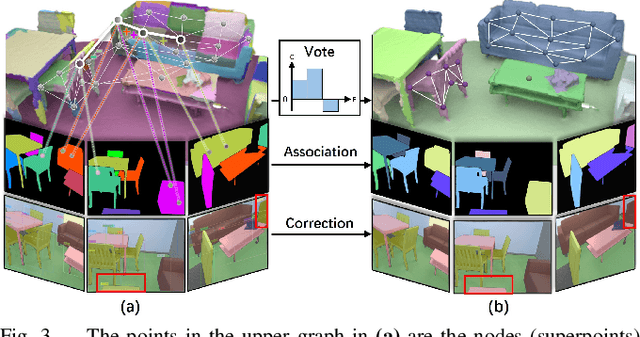
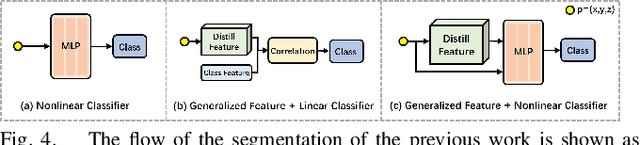
Panoptic reconstruction is a challenging task in 3D scene understanding. However, most existing methods heavily rely on pre-trained semantic segmentation models and known 3D object bounding boxes for 3D panoptic segmentation, which is not available for in-the-wild scenes. In this paper, we propose a novel zero-shot panoptic reconstruction method from RGB-D images of scenes. For zero-shot segmentation, we leverage open-vocabulary instance segmentation, but it has to face partial labeling and instance association challenges. We tackle both challenges by propagating partial labels with the aid of dense generalized features and building a 3D instance graph for associating 2D instance IDs. Specifically, we exploit partial labels to learn a classifier for generalized semantic features to provide complete labels for scenes with dense distilled features. Moreover, we formulate instance association as a 3D instance graph segmentation problem, allowing us to fully utilize the scene geometry prior and all 2D instance masks to infer global unique pseudo 3D instance ID. Our method outperforms state-of-the-art methods on the indoor dataset ScanNet V2 and the outdoor dataset KITTI-360, demonstrating the effectiveness of our graph segmentation method and reconstruction network.
SCALE: Self-Correcting Visual Navigation for Mobile Robots via Anti-Novelty Estimation
Apr 16, 2024Although visual navigation has been extensively studied using deep reinforcement learning, online learning for real-world robots remains a challenging task. Recent work directly learned from offline dataset to achieve broader generalization in the real-world tasks, which, however, faces the out-of-distribution (OOD) issue and potential robot localization failures in a given map for unseen observation. This significantly drops the success rates and even induces collision. In this paper, we present a self-correcting visual navigation method, SCALE, that can autonomously prevent the robot from the OOD situations without human intervention. Specifically, we develop an image-goal conditioned offline reinforcement learning method based on implicit Q-learning (IQL). When facing OOD observation, our novel localization recovery method generates the potential future trajectories by learning from the navigation affordance, and estimates the future novelty via random network distillation (RND). A tailored cost function searches for the candidates with the least novelty that can lead the robot to the familiar places. We collect offline data and conduct evaluation experiments in three real-world urban scenarios. Experiment results show that SCALE outperforms the previous state-of-the-art methods for open-world navigation with a unique capability of localization recovery, significantly reducing the need for human intervention. Code is available at https://github.com/KubeEdge4Robotics/ScaleNav.
NF-Atlas: Multi-Volume Neural Feature Fields for Large Scale LiDAR Mapping
Apr 10, 2023LiDAR Mapping has been a long-standing problem in robotics. Recent progress in neural implicit representation has brought new opportunities to robotic mapping. In this paper, we propose the multi-volume neural feature fields, called NF-Atlas, which bridge the neural feature volumes with pose graph optimization. By regarding the neural feature volume as pose graph nodes and the relative pose between volumes as pose graph edges, the entire neural feature field becomes both locally rigid and globally elastic. Locally, the neural feature volume employs a sparse feature Octree and a small MLP to encode the submap SDF with an option of semantics. Learning the map using this structure allows for end-to-end solving of maximum a posteriori (MAP) based probabilistic mapping. Globally, the map is built volume by volume independently, avoiding catastrophic forgetting when mapping incrementally. Furthermore, when a loop closure occurs, with the elastic pose graph based representation, only updating the origin of neural volumes is required without remapping. Finally, these functionalities of NF-Atlas are validated. Thanks to the sparsity and the optimization based formulation, NF-Atlas shows competitive performance in terms of accuracy, efficiency and memory usage on both simulation and real-world datasets.
Against Adversarial Learning: Naturally Distinguish Known and Unknown in Open Set Domain Adaptation
Nov 04, 2020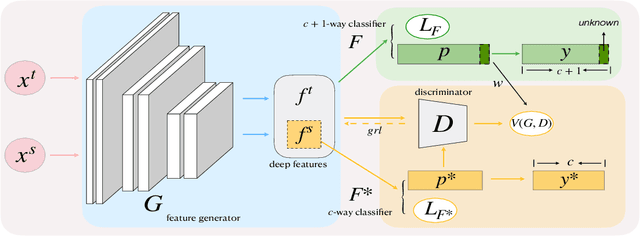
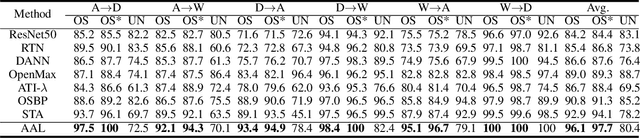
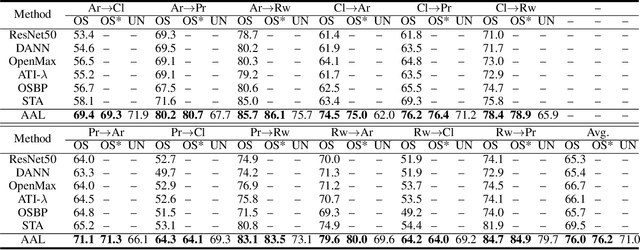
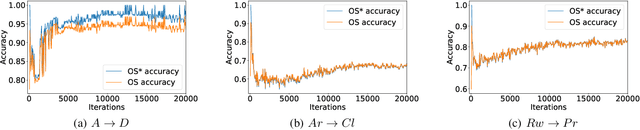
Open set domain adaptation refers to the scenario that the target domain contains categories that do not exist in the source domain. It is a more common situation in the reality compared with the typical closed set domain adaptation where the source domain and the target domain contain the same categories. The main difficulty of open set domain adaptation is that we need to distinguish which target data belongs to the unknown classes when machine learning models only have concepts about what they know. In this paper, we propose an "against adversarial learning" method that can distinguish unknown target data and known data naturally without setting any additional hyper parameters and the target data predicted to the known classes can be classified at the same time. Experimental results show that the proposed method can make significant improvement in performance compared with several state-of-the-art methods.
Mixed Set Domain Adaptation
Nov 04, 2020



In the settings of conventional domain adaptation, categories of the source dataset are from the same domain (or domains for multi-source domain adaptation), which is not always true in reality. In this paper, we propose \textbf{\textit{Mixed Set Domain Adaptation} (MSDA)}. Under the settings of MSDA, different categories of the source dataset are not all collected from the same domain(s). For instance, category $1\sim k$ are collected from domain $\alpha$ while category $k+1\sim c$ are collected from domain $\beta$. Under such situation, domain adaptation performance will be further influenced because of the distribution discrepancy inside the source data. A feature element-wise weighting (FEW) method that can reduce distribution discrepancy between different categories is also proposed for MSDA. Experimental results and quality analysis show the significance of solving MSDA problem and the effectiveness of the proposed method.