 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Sensing-Constrained Diversity-Multiplexing Tradeoff in MIMO ISAC: A Geometric Approach
May 03, 2026Diversity and multiplexing are the two fundamental gains of multiple-input and multiple-output (MIMO) communications, enabling systems to simultaneously achieve increased reliability and higher data rates. The intricate interplay between these two metrics is captured by the celebrated diversity-multiplexing tradeoff (DMT). With the rapid evolution of wireless technologies, low-latency integrated sensing and communication (ISAC) has emerged as a key enabler for 6G applications, including extended reality (XR) and massive digital twins. Consequently, understanding the DMT within MIMO ISAC systems becomes critical. In this paper, we investigate the communication DMT in a mono-static MIMO ISAC system under Rayleigh fading, specifically when the transmitter is constrained to emit sensing-optimal waveforms. By unveiling the geometric properties of generalized Stiefel manifolds and employing large-deviation analysis, we characterize the asymptotic outage probability of this typical ISAC channel. This formulation yields an elegant converse bound on the sensing-constrained DMT. Ultimately, our work provides an answer to a pivotal unanswered question in ISAC system design: How much MIMO gain is fundamentally sacrificed in communication to integrate optimal sensing capabilities?
Denoising-Aware Contrastive Learning for Noisy Time Series
Jun 07, 2024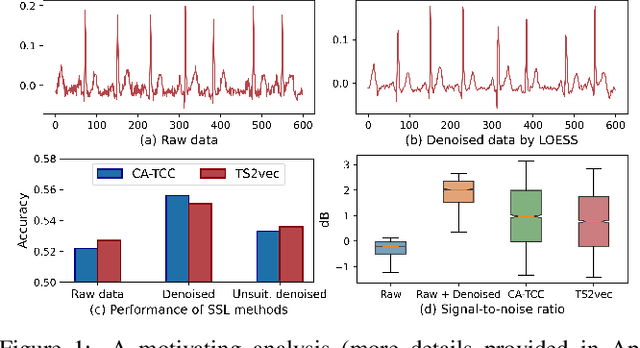



Time series self-supervised learning (SSL) aims to exploit unlabeled data for pre-training to mitigate the reliance on labels. Despite the great success in recent years, there is limited discussion on the potential noise in the time series, which can severely impair the performance of existing SSL methods. To mitigate the noise, the de facto strategy is to apply conventional denoising methods before model training. However, this pre-processing approach may not fully eliminate the effect of noise in SSL for two reasons: (i) the diverse types of noise in time series make it difficult to automatically determine suitable denoising methods; (ii) noise can be amplified after mapping raw data into latent space. In this paper, we propose denoising-aware contrastive learning (DECL), which uses contrastive learning objectives to mitigate the noise in the representation and automatically selects suitable denoising methods for every sample. Extensive experiments on various datasets verify the effectiveness of our method. The code is open-sourced.
The Integrated Sensing and Communication Revolution for 6G: Vision, Techniques, and Applications
May 03, 2024



Future wireless networks will integrate sensing, learning and communication to provide new services beyond communication and to become more resilient. Sensors at the network infrastructure, sensors on the user equipment, and the sensing capability of the communication signal itself provide a new source of data that connects the physical and radio frequency environments. A wireless network that harnesses all these sensing data can not only enable additional sensing services, but also become more resilient to channel-dependent effects like blockage and better support adaptation in dynamic environments as networks reconfigure. In this paper, we provide a vision for integrated sensing and communication (ISAC) networks and an overview of how signal processing, optimization and machine learning techniques can be leveraged to make them a reality in the context of 6G. We also include some examples of the performance of several of these strategies when evaluated using a simulation framework based on a combination of ray tracing measurements and mathematical models that mix the digital and physical worlds.
Graph Learning under Distribution Shifts: A Comprehensive Survey on Domain Adaptation, Out-of-distribution, and Continual Learning
Mar 07, 2024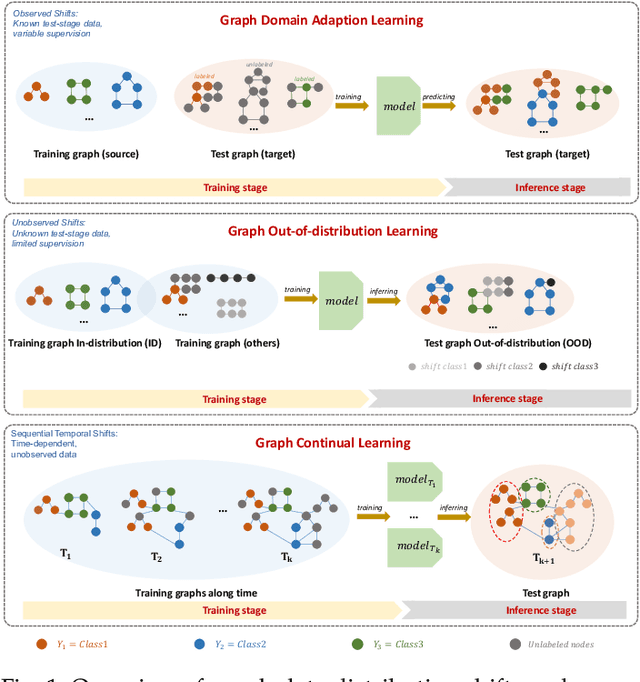

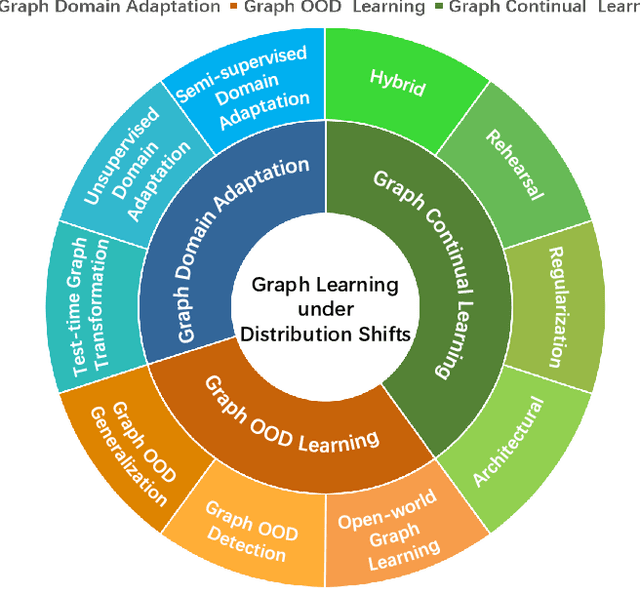
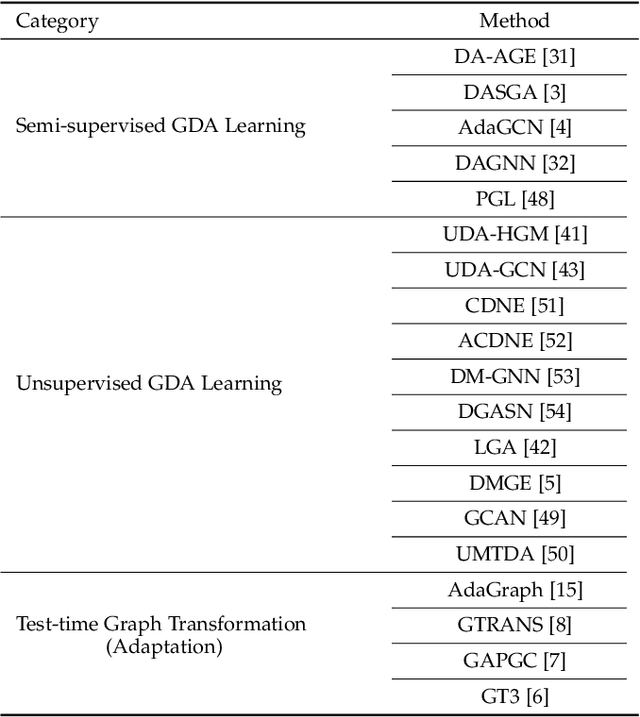
Graph learning plays a pivotal role and has gained significant attention in various application scenarios, from social network analysis to recommendation systems, for its effectiveness in modeling complex data relations represented by graph structural data. In reality, the real-world graph data typically show dynamics over time, with changing node attributes and edge structure, leading to the severe graph data distribution shift issue. This issue is compounded by the diverse and complex nature of distribution shifts, which can significantly impact the performance of graph learning methods in degraded generalization and adaptation capabilities, posing a substantial challenge to their effectiveness. In this survey, we provide a comprehensive review and summary of the latest approaches, strategies, and insights that address distribution shifts within the context of graph learning. Concretely, according to the observability of distributions in the inference stage and the availability of sufficient supervision information in the training stage, we categorize existing graph learning methods into several essential scenarios, including graph domain adaptation learning, graph out-of-distribution learning, and graph continual learning. For each scenario, a detailed taxonomy is proposed, with specific descriptions and discussions of existing progress made in distribution-shifted graph learning. Additionally, we discuss the potential applications and future directions for graph learning under distribution shifts with a systematic analysis of the current state in this field. The survey is positioned to provide general guidance for the development of effective graph learning algorithms in handling graph distribution shifts, and to stimulate future research and advancements in this area.
Semi-supervised Domain Adaptation on Graphs with Contrastive Learning and Minimax Entropy
Sep 14, 2023



Label scarcity in a graph is frequently encountered in real-world applications due to the high cost of data labeling. To this end, semi-supervised domain adaptation (SSDA) on graphs aims to leverage the knowledge of a labeled source graph to aid in node classification on a target graph with limited labels. SSDA tasks need to overcome the domain gap between the source and target graphs. However, to date, this challenging research problem has yet to be formally considered by the existing approaches designed for cross-graph node classification. To tackle the SSDA problem on graphs, a novel method called SemiGCL is proposed, which benefits from graph contrastive learning and minimax entropy training. SemiGCL generates informative node representations by contrasting the representations learned from a graph's local and global views. Additionally, SemiGCL is adversarially optimized with the entropy loss of unlabeled target nodes to reduce domain divergence. Experimental results on benchmark datasets demonstrate that SemiGCL outperforms the state-of-the-art baselines on the SSDA tasks.
Domain-adaptive Message Passing Graph Neural Network
Aug 31, 2023Cross-network node classification (CNNC), which aims to classify nodes in a label-deficient target network by transferring the knowledge from a source network with abundant labels, draws increasing attention recently. To address CNNC, we propose a domain-adaptive message passing graph neural network (DM-GNN), which integrates graph neural network (GNN) with conditional adversarial domain adaptation. DM-GNN is capable of learning informative representations for node classification that are also transferrable across networks. Firstly, a GNN encoder is constructed by dual feature extractors to separate ego-embedding learning from neighbor-embedding learning so as to jointly capture commonality and discrimination between connected nodes. Secondly, a label propagation node classifier is proposed to refine each node's label prediction by combining its own prediction and its neighbors' prediction. In addition, a label-aware propagation scheme is devised for the labeled source network to promote intra-class propagation while avoiding inter-class propagation, thus yielding label-discriminative source embeddings. Thirdly, conditional adversarial domain adaptation is performed to take the neighborhood-refined class-label information into account during adversarial domain adaptation, so that the class-conditional distributions across networks can be better matched. Comparisons with eleven state-of-the-art methods demonstrate the effectiveness of the proposed DM-GNN.
On the Performance Tradeoff of an ISAC System with Finite Blocklength
Aug 01, 2023



Integrated sensing and communication (ISAC) has been proposed as a promising paradigm in the future wireless networks, where the spectral and hardware resources are shared to provide a considerable performance gain. It is essential to understand how sensing and communication (S\&C) influences each other to guide the practical algorithm and system design in ISAC. In this paper, we investigate the performance tradeoff between S\&C in a single-input single-output (SISO) ISAC system with finite blocklength. In particular, we present the system model and the ISAC scheme, after which the rate-error tradeoff is introduced as the performance metric. Then we derive the achievability and converse bounds for the rate-error tradeoff, determining the boundary of the joint S\&C performance. Furthermore, we develop the asymptotic analysis at large blocklength regime, where the performance tradeoff between S\&C is proved to vanish as the blocklength tends to infinity. Finally, our theoretical analysis is consolidated by simulation results.
Comparison of Update and Genetic Training Algorithms in a Memristor Crossbar Perceptron
Dec 10, 2020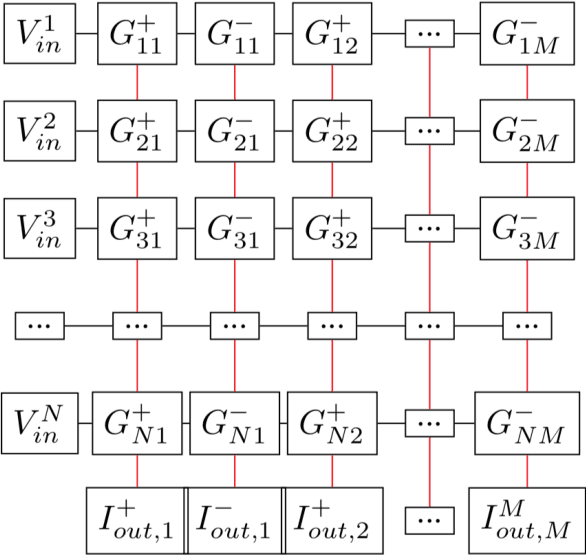
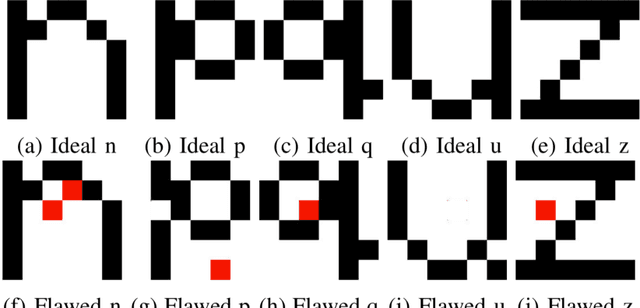
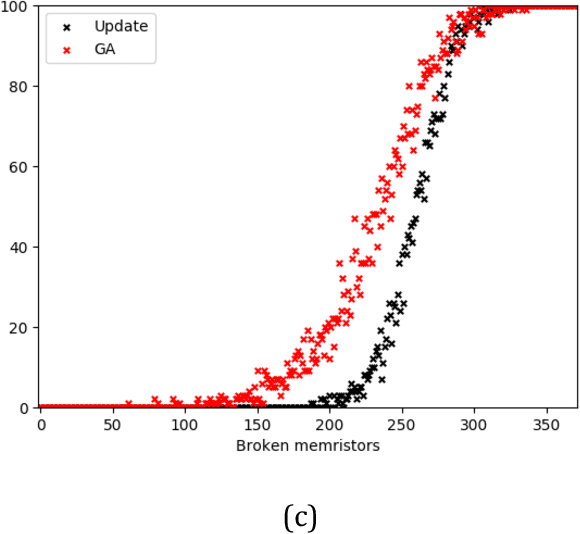
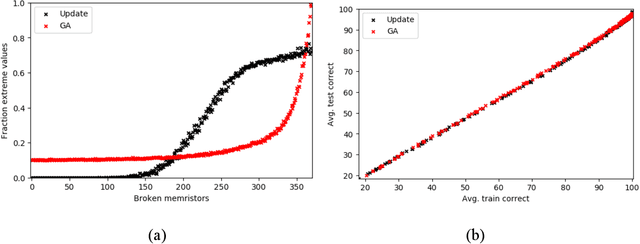
Memristor-based computer architectures are becoming more attractive as a possible choice of hardware for the implementation of neural networks. However, at present, memristor technologies are susceptible to a variety of failure modes, a serious concern in any application where regular access to the hardware may not be expected or even possible. In this study, we investigate whether certain training algorithms may be more resilient to particular hardware failure modes, and therefore more suitable for use in those applications. We implement two training algorithms -- a local update scheme and a genetic algorithm -- in a simulated memristor crossbar, and compare their ability to train for a simple image classification task as an increasing number of memristors fail to adjust their conductance. We demonstrate that there is a clear distinction between the two algorithms in several measures of the rate of failure to train.
Against Adversarial Learning: Naturally Distinguish Known and Unknown in Open Set Domain Adaptation
Nov 04, 2020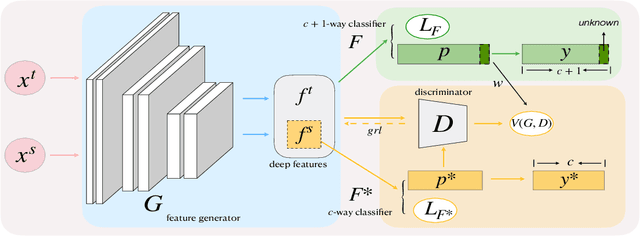
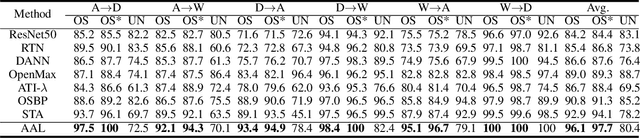
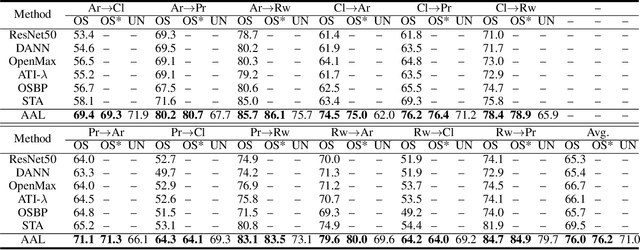
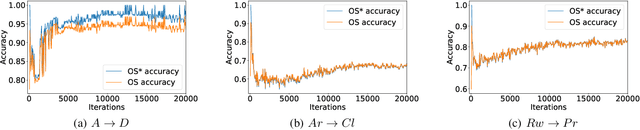
Open set domain adaptation refers to the scenario that the target domain contains categories that do not exist in the source domain. It is a more common situation in the reality compared with the typical closed set domain adaptation where the source domain and the target domain contain the same categories. The main difficulty of open set domain adaptation is that we need to distinguish which target data belongs to the unknown classes when machine learning models only have concepts about what they know. In this paper, we propose an "against adversarial learning" method that can distinguish unknown target data and known data naturally without setting any additional hyper parameters and the target data predicted to the known classes can be classified at the same time. Experimental results show that the proposed method can make significant improvement in performance compared with several state-of-the-art methods.