 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Rule-based Differentiable Representation Learning
Mar 16, 2025Representation learning has emerged as a crucial focus in machine and deep learning, involving the extraction of meaningful and useful features and patterns from the input data, thereby enhancing the performance of various downstream tasks such as classification, clustering, and prediction. Current mainstream representation learning methods primarily rely on non-linear data mining techniques such as kernel methods and deep neural networks to extract abstract knowledge from complex datasets. However, most of these methods are black-box, lacking transparency and interpretability in the learning process, which constrains their practical utility. To this end, this paper introduces a novel representation learning method grounded in an interpretable fuzzy rule-based model. Specifically, it is built upon the Takagi-Sugeno-Kang fuzzy system (TSK-FS) to initially map input data to a high-dimensional fuzzy feature space through the antecedent part of the TSK-FS. Subsequently, a novel differentiable optimization method is proposed for the consequence part learning which can preserve the model's interpretability and transparency while further exploring the nonlinear relationships within the data. This optimization method retains the essence of traditional optimization, with certain parts of the process parameterized corresponding differentiable modules constructed, and a deep optimization process implemented. Consequently, this method not only enhances the model's performance but also ensures its interpretability. Moreover, a second-order geometry preservation method is introduced to further improve the robustness of the proposed method. Extensive experiments conducted on various benchmark datasets validate the superiority of the proposed method, highlighting its potential for advancing representation learning methodologies.
Multi-Label Takagi-Sugeno-Kang Fuzzy System
Sep 20, 2023
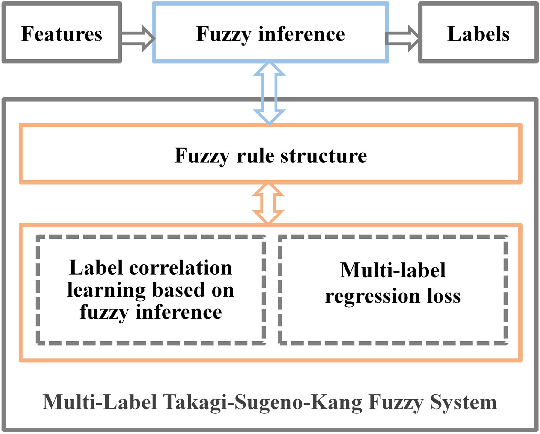
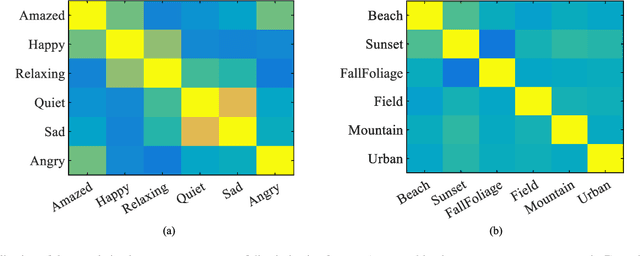
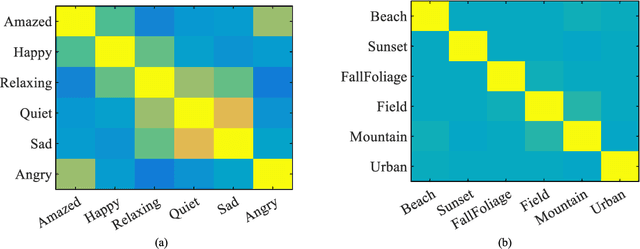
Multi-label classification can effectively identify the relevant labels of an instance from a given set of labels. However,the modeling of the relationship between the features and the labels is critical to the classification performance. To this end, we propose a new multi-label classification method, called Multi-Label Takagi-Sugeno-Kang Fuzzy System (ML-TSK FS), to improve the classification performance. The structure of ML-TSK FS is designed using fuzzy rules to model the relationship between features and labels. The fuzzy system is trained by integrating fuzzy inference based multi-label correlation learning with multi-label regression loss. The proposed ML-TSK FS is evaluated experimentally on 12 benchmark multi-label datasets. 1 The results show that the performance of ML-TSK FS is competitive with existing methods in terms of various evaluation metrics, indicating that it is able to model the feature-label relationship effectively using fuzzy inference rules and enhances the classification performance.
Multi-view Fuzzy Representation Learning with Rules based Model
Sep 20, 2023Unsupervised multi-view representation learning has been extensively studied for mining multi-view data. However, some critical challenges remain. On the one hand, the existing methods cannot explore multi-view data comprehensively since they usually learn a common representation between views, given that multi-view data contains both the common information between views and the specific information within each view. On the other hand, to mine the nonlinear relationship between data, kernel or neural network methods are commonly used for multi-view representation learning. However, these methods are lacking in interpretability. To this end, this paper proposes a new multi-view fuzzy representation learning method based on the interpretable Takagi-Sugeno-Kang (TSK) fuzzy system (MVRL_FS). The method realizes multi-view representation learning from two aspects. First, multi-view data are transformed into a high-dimensional fuzzy feature space, while the common information between views and specific information of each view are explored simultaneously. Second, a new regularization method based on L_(2,1)-norm regression is proposed to mine the consistency information between views, while the geometric structure of the data is preserved through the Laplacian graph. Finally, extensive experiments on many benchmark multi-view datasets are conducted to validate the superiority of the proposed method.
Domain-adaptive Message Passing Graph Neural Network
Aug 31, 2023Cross-network node classification (CNNC), which aims to classify nodes in a label-deficient target network by transferring the knowledge from a source network with abundant labels, draws increasing attention recently. To address CNNC, we propose a domain-adaptive message passing graph neural network (DM-GNN), which integrates graph neural network (GNN) with conditional adversarial domain adaptation. DM-GNN is capable of learning informative representations for node classification that are also transferrable across networks. Firstly, a GNN encoder is constructed by dual feature extractors to separate ego-embedding learning from neighbor-embedding learning so as to jointly capture commonality and discrimination between connected nodes. Secondly, a label propagation node classifier is proposed to refine each node's label prediction by combining its own prediction and its neighbors' prediction. In addition, a label-aware propagation scheme is devised for the labeled source network to promote intra-class propagation while avoiding inter-class propagation, thus yielding label-discriminative source embeddings. Thirdly, conditional adversarial domain adaptation is performed to take the neighborhood-refined class-label information into account during adversarial domain adaptation, so that the class-conditional distributions across networks can be better matched. Comparisons with eleven state-of-the-art methods demonstrate the effectiveness of the proposed DM-GNN.
A Robust Multilabel Method Integrating Rule-based Transparent Model, Soft Label Correlation Learning and Label Noise Resistance
Jan 09, 2023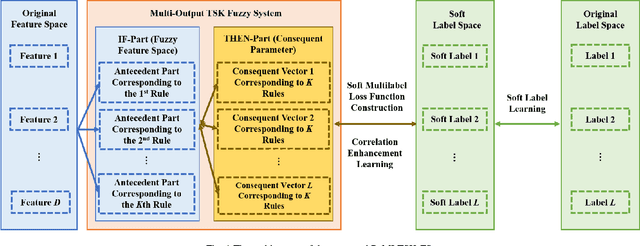
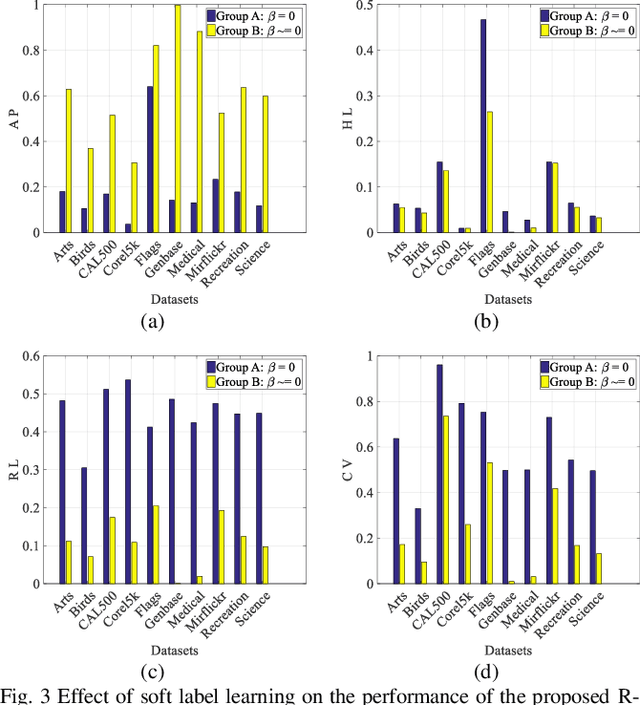
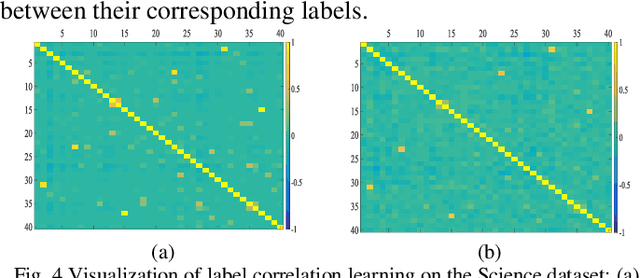
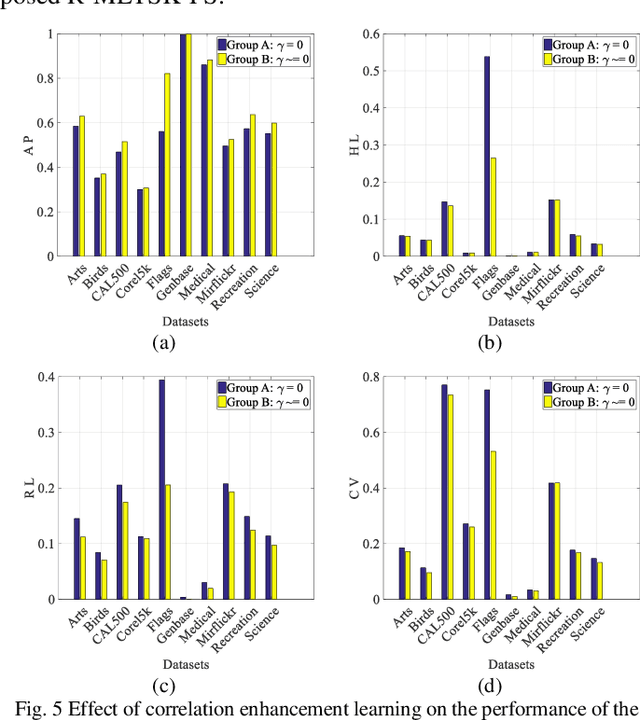
Model transparency, label correlation learning and the robust-ness to label noise are crucial for multilabel learning. However, few existing methods study these three characteristics simultaneously. To address this challenge, we propose the robust multilabel Takagi-Sugeno-Kang fuzzy system (R-MLTSK-FS) with three mechanisms. First, we design a soft label learning mechanism to reduce the effect of label noise by explicitly measuring the interactions between labels, which is also the basis of the other two mechanisms. Second, the rule-based TSK FS is used as the base model to efficiently model the inference relationship be-tween features and soft labels in a more transparent way than many existing multilabel models. Third, to further improve the performance of multilabel learning, we build a correlation enhancement learning mechanism based on the soft label space and the fuzzy feature space. Extensive experiments are conducted to demonstrate the superiority of the proposed method.
Graph Fuzzy System: Concepts, Models and Algorithms
Oct 30, 2022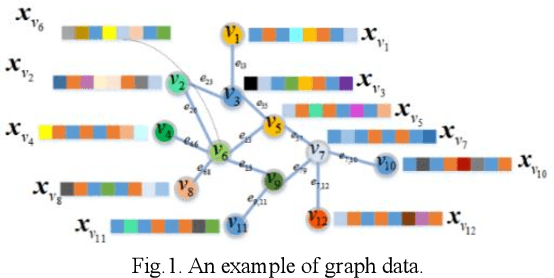
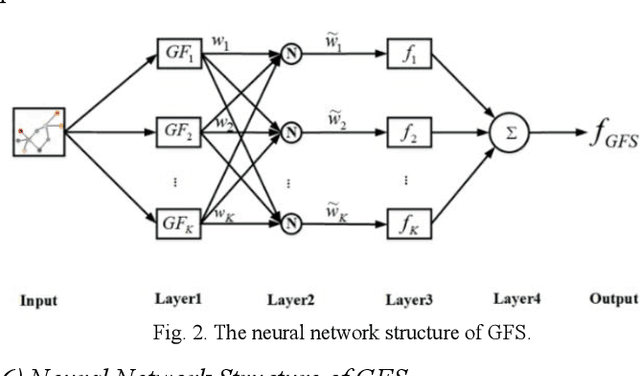

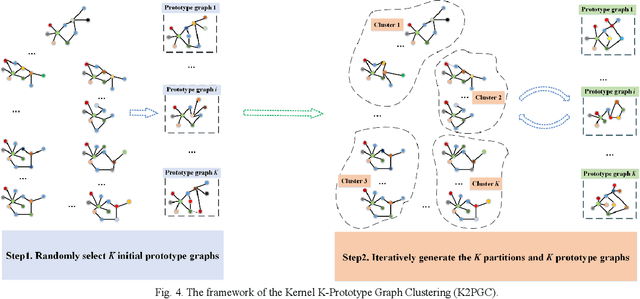
Fuzzy systems (FSs) have enjoyed wide applications in various fields, including pattern recognition, intelligent control, data mining and bioinformatics, which is attributed to the strong interpretation and learning ability. In traditional application scenarios, FSs are mainly applied to model Euclidean space data and cannot be used to handle graph data of non-Euclidean structure in nature, such as social networks and traffic route maps. Therefore, development of FS modeling method that is suitable for graph data and can retain the advantages of traditional FSs is an important research. To meet this challenge, a new type of FS for graph data modeling called Graph Fuzzy System (GFS) is proposed in this paper, where the concepts, modeling framework and construction algorithms are systematically developed. First, GFS related concepts, including graph fuzzy rule base, graph fuzzy sets and graph consequent processing unit (GCPU), are defined. A GFS modeling framework is then constructed and the antecedents and consequents of the GFS are presented and analyzed. Finally, a learning framework of GFS is proposed, in which a kernel K-prototype graph clustering (K2PGC) is proposed to develop the construction algorithm for the GFS antecedent generation, and then based on graph neural network (GNNs), consequent parameters learning algorithm is proposed for GFS. Specifically, three different versions of the GFS implementation algorithm are developed for comprehensive evaluations with experiments on various benchmark graph classification datasets. The results demonstrate that the proposed GFS inherits the advantages of both existing mainstream GNNs methods and conventional FSs methods while achieving better performance than the counterparts.
Dual Representation Learning for One-Step Clustering of Multi-View Data
Aug 30, 2022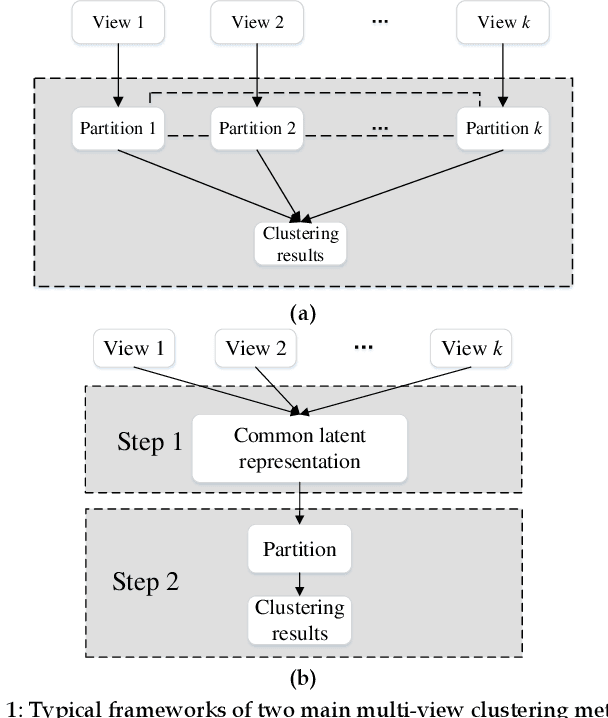

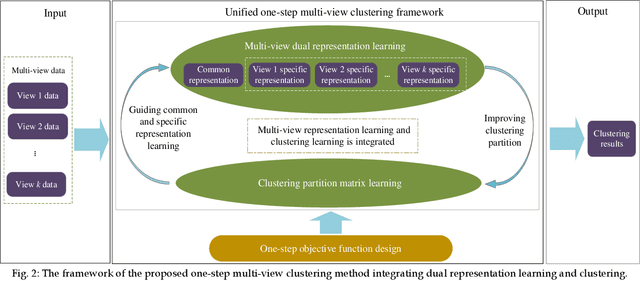

Multi-view data are commonly encountered in data mining applications. Effective extraction of information from multi-view data requires specific design of clustering methods to cater for data with multiple views, which is non-trivial and challenging. In this paper, we propose a novel one-step multi-view clustering method by exploiting the dual representation of both the common and specific information of different views. The motivation originates from the rationale that multi-view data contain not only the consistent knowledge between views but also the unique knowledge of each view. Meanwhile, to make the representation learning more specific to the clustering task, a one-step learning framework is proposed to integrate representation learning and clustering partition as a whole. With this framework, the representation learning and clustering partition mutually benefit each other, which effectively improve the clustering performance. Results from extensive experiments conducted on benchmark multi-view datasets clearly demonstrate the superiority of the proposed method.
A Novel TSK Fuzzy System Incorporating Multi-view Collaborative Transfer Learning for Personalized Epileptic EEG Detection
Nov 11, 2021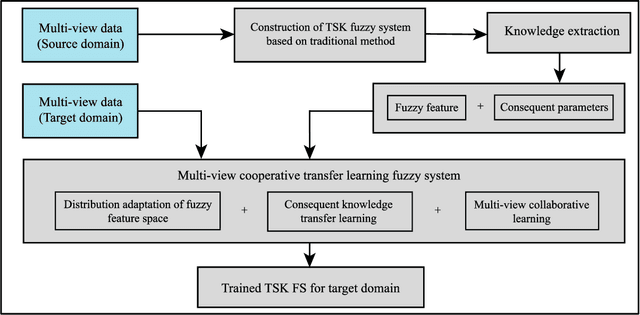
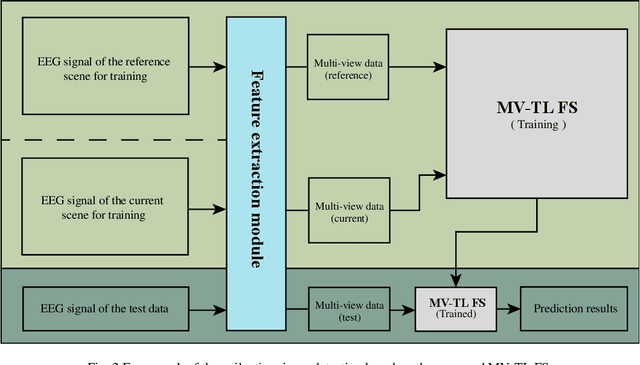
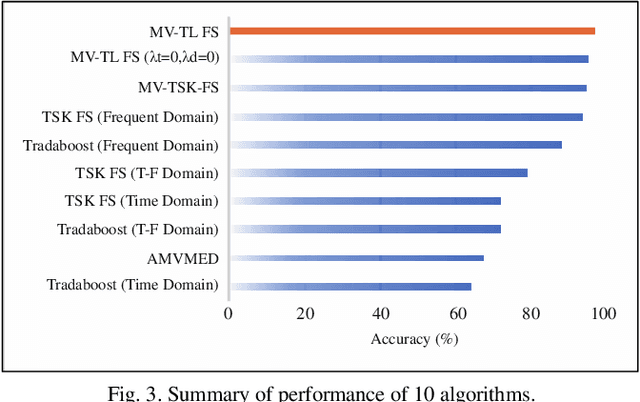
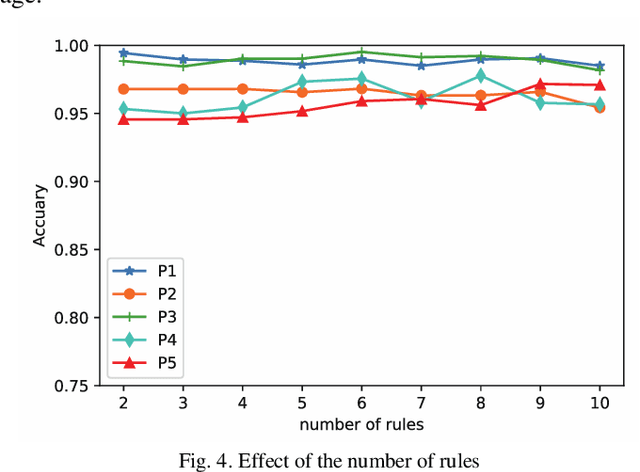
In clinical practice, electroencephalography (EEG) plays an important role in the diagnosis of epilepsy. EEG-based computer-aided diagnosis of epilepsy can greatly improve the ac-curacy of epilepsy detection while reducing the workload of physicians. However, there are many challenges in practical applications for personalized epileptic EEG detection (i.e., training of detection model for a specific person), including the difficulty in extracting effective features from one single view, the undesirable but common scenario of lacking sufficient training data in practice, and the no guarantee of identically distributed training and test data. To solve these problems, we propose a TSK fuzzy system-based epilepsy detection algorithm that integrates multi-view collaborative transfer learning. To address the challenge due to the limitation of single-view features, multi-view learning ensures the diversity of features by extracting them from different views. The lack of training data for building a personalized detection model is tackled by leveraging the knowledge from the source domain (reference scene) to enhance the performance of the target domain (current scene of interest), where mismatch of data distributions between the two domains is resolved with adaption technique based on maximum mean discrepancy. Notably, the transfer learning and multi-view feature extraction are performed at the same time. Furthermore, the fuzzy rules of the TSK fuzzy system equip the model with strong fuzzy logic inference capability. Hence, the proposed method has the potential to detect epileptic EEG signals effectively, which is demonstrated with the positive results from a large number of experiments on the CHB-MIT dataset.
TSK Fuzzy System Towards Few Labeled Incomplete Multi-View Data Classification
Oct 08, 2021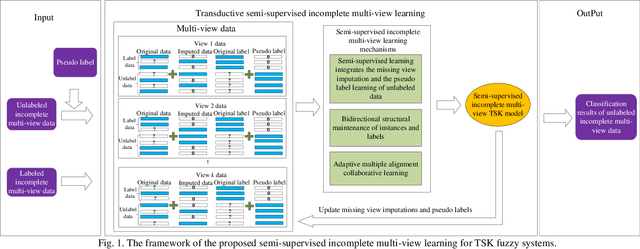
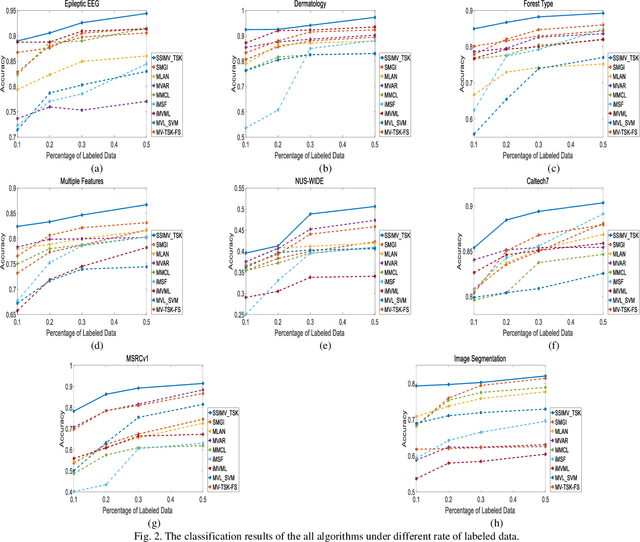
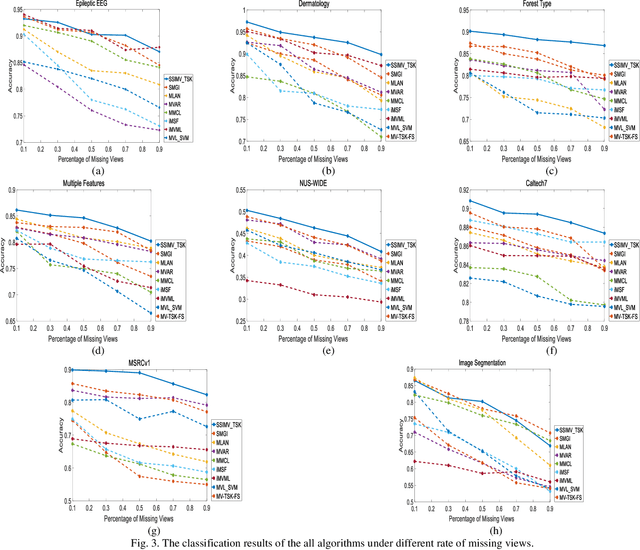
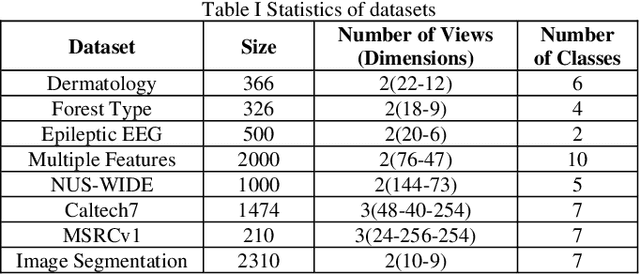
Data collected by multiple methods or from multiple sources is called multi-view data. To make full use of the multi-view data, multi-view learning plays an increasingly important role. Traditional multi-view learning methods rely on a large number of labeled and completed multi-view data. However, it is expensive and time-consuming to obtain a large number of labeled multi-view data in real-world applications. Moreover, multi-view data is often incomplete because of data collection failures, self-deficiency, or other reasons. Therefore, we may have to face the problem of fewer labeled and incomplete multi-view data in real application scenarios. In this paper, a transductive semi-supervised incomplete multi-view TSK fuzzy system modeling method (SSIMV_TSK) is proposed to address these challenges. First, in order to alleviate the dependency on labeled data and keep the model interpretable, the proposed method integrates missing view imputation, pseudo label learning of unlabeled data, and fuzzy system modeling into a single process to yield a model with interpretable fuzzy rules. Then, two new mechanisms, i.e. the bidirectional structural preservation of instance and label, as well as the adaptive multiple alignment collaborative learning, are proposed to improve the robustness of the model. The proposed method has the following distinctive characteristics: 1) it can deal with the incomplete and few labeled multi-view data simultaneously; 2) it integrates the missing view imputation and model learning as a single process, which is more efficient than the traditional two-step strategy; 3) attributed to the interpretable fuzzy inference rules, this method is more interpretable. Experimental results on real datasets show that the proposed method significantly outperforms the state-of-the-art methods.
Constrained Multi-shape Evolution for Overlapping Cytoplasm Segmentation
Apr 15, 2020


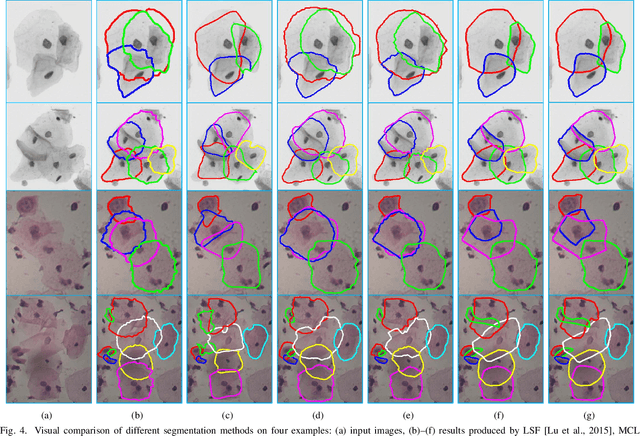
Segmenting overlapping cytoplasm of cells in cervical smear images is a clinically essential task, for quantitatively measuring cell-level features in order to diagnose cervical cancer. This task, however, remains rather challenging, mainly due to the deficiency of intensity (or color) information in the overlapping region. Although shape prior-based models that compensate intensity deficiency by introducing prior shape information (shape priors) about cytoplasm are firmly established, they often yield visually implausible results, mainly because they model shape priors only by limited shape hypotheses about cytoplasm, exploit cytoplasm-level shape priors alone, and impose no shape constraint on the resulting shape of the cytoplasm. In this paper, we present a novel and effective shape prior-based approach, called constrained multi-shape evolution, that segments all overlapping cytoplasms in the clump simultaneously by jointly evolving each cytoplasm's shape guided by the modeled shape priors. We model local shape priors (cytoplasm--level) by an infinitely large shape hypothesis set which contains all possible shapes of the cytoplasm. In the shape evolution, we compensate intensity deficiency for the segmentation by introducing not only the modeled local shape priors but also global shape priors (clump--level) modeled by considering mutual shape constraints of cytoplasms in the clump. We also constrain the resulting shape in each evolution to be in the built shape hypothesis set, for further reducing implausible segmentation results. We evaluated the proposed method in two typical cervical smear datasets, and the extensive experimental results show that the proposed method is effective to segment overlapping cytoplasm, consistently outperforming the state-of-the-art methods.