 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-scale Semantic Correlation Mining for Visible-Infrared Person Re-Identification
Nov 24, 2023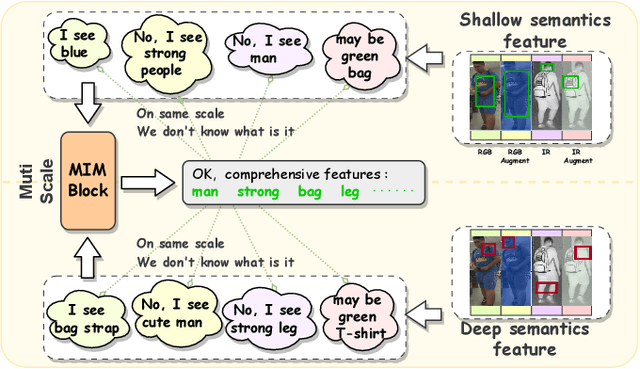
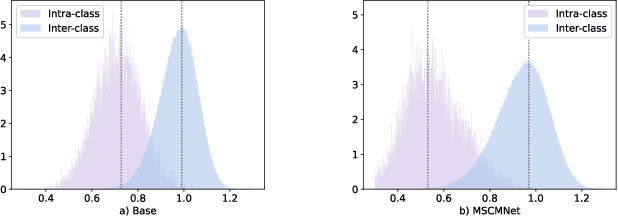
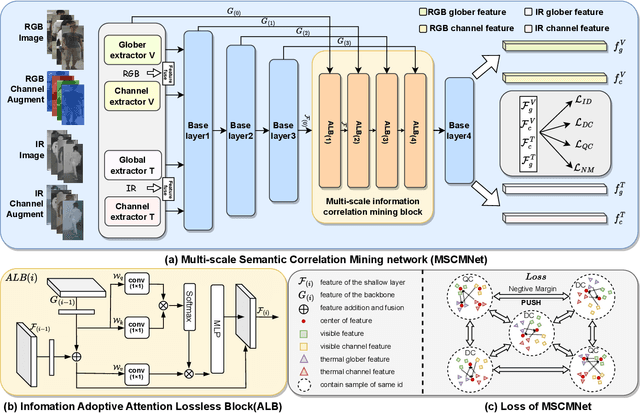
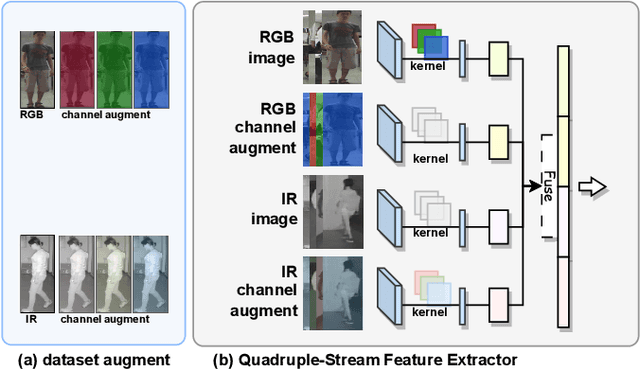
The main challenge in the Visible-Infrared Person Re-Identification (VI-ReID) task lies in how to extract discriminative features from different modalities for matching purposes. While the existing well works primarily focus on minimizing the modal discrepancies, the modality information can not thoroughly be leveraged. To solve this problem, a Multi-scale Semantic Correlation Mining network (MSCMNet) is proposed to comprehensively exploit semantic features at multiple scales and simultaneously reduce modality information loss as small as possible in feature extraction. The proposed network contains three novel components. Firstly, after taking into account the effective utilization of modality information, the Multi-scale Information Correlation Mining Block (MIMB) is designed to explore semantic correlations across multiple scales. Secondly, in order to enrich the semantic information that MIMB can utilize, a quadruple-stream feature extractor (QFE) with non-shared parameters is specifically designed to extract information from different dimensions of the dataset. Finally, the Quadruple Center Triplet Loss (QCT) is further proposed to address the information discrepancy in the comprehensive features. Extensive experiments on the SYSU-MM01, RegDB, and LLCM datasets demonstrate that the proposed MSCMNet achieves the greatest accuracy.
Multi-Label Takagi-Sugeno-Kang Fuzzy System
Sep 20, 2023
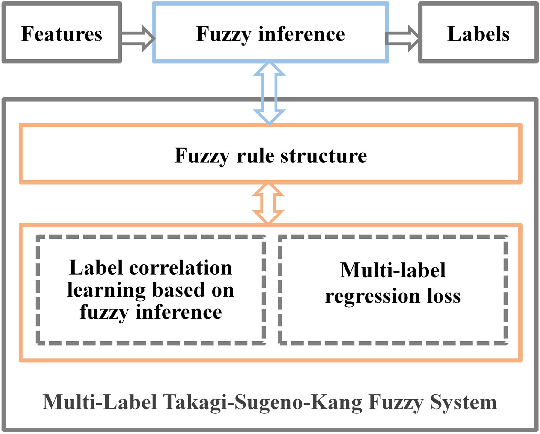
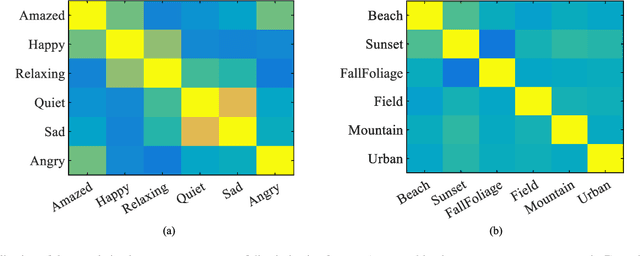
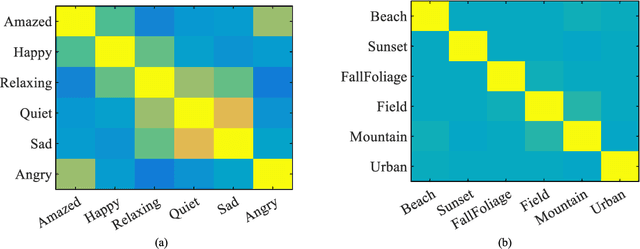
Multi-label classification can effectively identify the relevant labels of an instance from a given set of labels. However,the modeling of the relationship between the features and the labels is critical to the classification performance. To this end, we propose a new multi-label classification method, called Multi-Label Takagi-Sugeno-Kang Fuzzy System (ML-TSK FS), to improve the classification performance. The structure of ML-TSK FS is designed using fuzzy rules to model the relationship between features and labels. The fuzzy system is trained by integrating fuzzy inference based multi-label correlation learning with multi-label regression loss. The proposed ML-TSK FS is evaluated experimentally on 12 benchmark multi-label datasets. 1 The results show that the performance of ML-TSK FS is competitive with existing methods in terms of various evaluation metrics, indicating that it is able to model the feature-label relationship effectively using fuzzy inference rules and enhances the classification performance.
Multi-view Fuzzy Representation Learning with Rules based Model
Sep 20, 2023Unsupervised multi-view representation learning has been extensively studied for mining multi-view data. However, some critical challenges remain. On the one hand, the existing methods cannot explore multi-view data comprehensively since they usually learn a common representation between views, given that multi-view data contains both the common information between views and the specific information within each view. On the other hand, to mine the nonlinear relationship between data, kernel or neural network methods are commonly used for multi-view representation learning. However, these methods are lacking in interpretability. To this end, this paper proposes a new multi-view fuzzy representation learning method based on the interpretable Takagi-Sugeno-Kang (TSK) fuzzy system (MVRL_FS). The method realizes multi-view representation learning from two aspects. First, multi-view data are transformed into a high-dimensional fuzzy feature space, while the common information between views and specific information of each view are explored simultaneously. Second, a new regularization method based on L_(2,1)-norm regression is proposed to mine the consistency information between views, while the geometric structure of the data is preserved through the Laplacian graph. Finally, extensive experiments on many benchmark multi-view datasets are conducted to validate the superiority of the proposed method.
Cooperation Learning Enhanced Colonic Polyp Segmentation Based on Transformer-CNN Fusion
Jan 17, 2023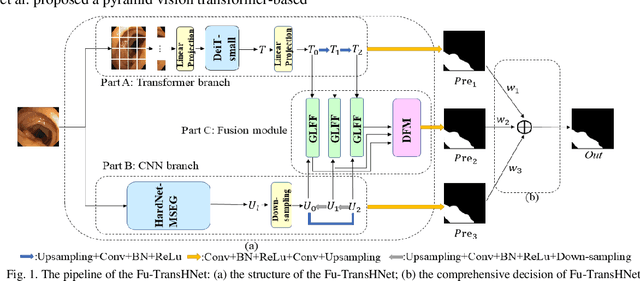
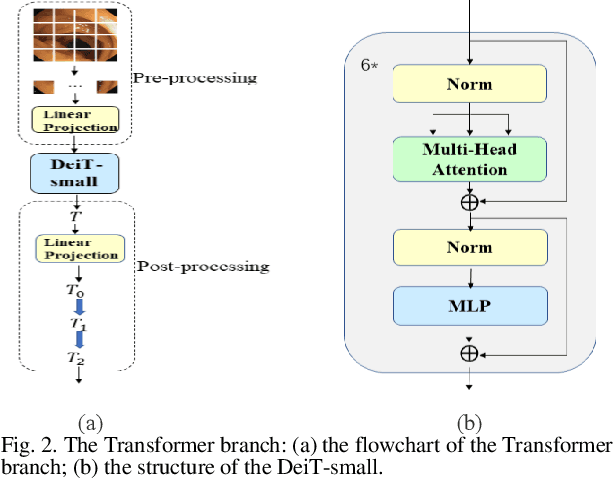
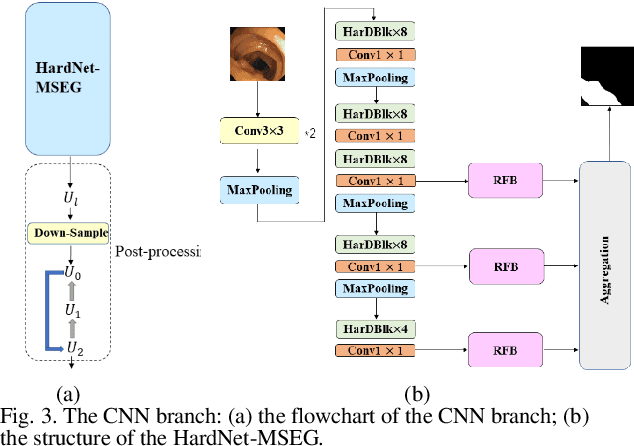
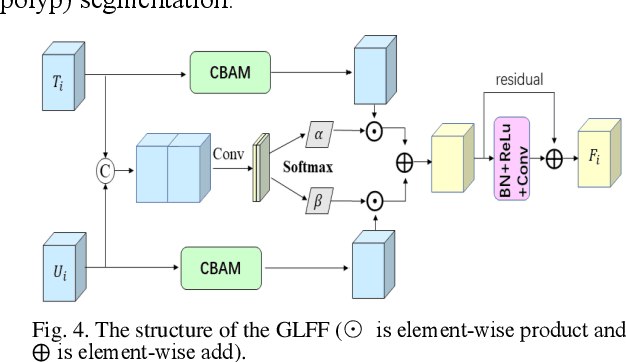
Traditional segmentation methods for colonic polyps are mainly designed based on low-level features. They could not accurately extract the location of small colonic polyps. Although the existing deep learning methods can improve the segmentation accuracy, their effects are still unsatisfied. To meet the above challenges, we propose a hybrid network called Fusion-Transformer-HardNetMSEG (i.e., Fu-TransHNet) in this study. Fu-TransHNet uses deep learning of different mechanisms to fuse each other and is enhanced with multi-view collaborative learning techniques. Firstly, the Fu-TransHNet utilizes the Transformer branch and the CNN branch to realize the global feature learning and local feature learning, respectively. Secondly, a fusion module is designed to integrate the features from two branches. The fusion module consists of two parts: 1) the Global-Local Feature Fusion (GLFF) part and 2) the Dense Fusion of Multi-scale features (DFM) part. The former is built to compensate the feature information mission from two branches at the same scale; the latter is constructed to enhance the feature representation. Thirdly, the above two branches and fusion modules utilize multi-view cooperative learning techniques to obtain their respective weights that denote their importance and then make a final decision comprehensively. Experimental results showed that the Fu-TransHNet network was superior to the existing methods on five widely used benchmark datasets. In particular, on the ETIS-LaribPolypDB dataset containing many small-target colonic polyps, the mDice obtained by Fu-TransHNet were 12.4% and 6.2% higher than the state-of-the-art methods HardNet-MSEG and TransFuse-s, respectively.
A Robust Multilabel Method Integrating Rule-based Transparent Model, Soft Label Correlation Learning and Label Noise Resistance
Jan 09, 2023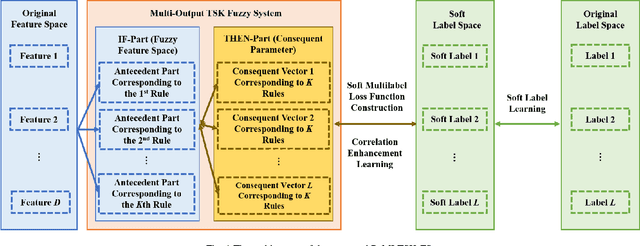
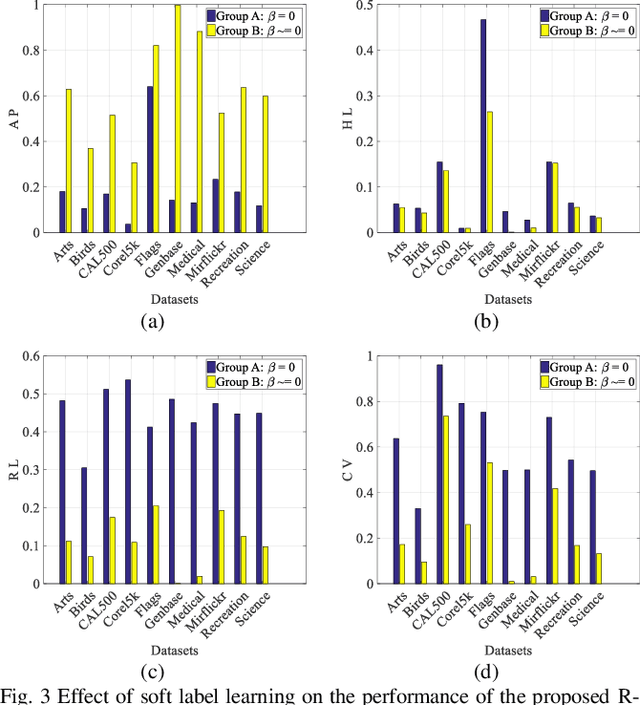
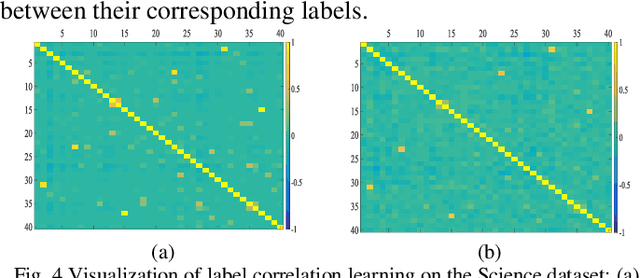
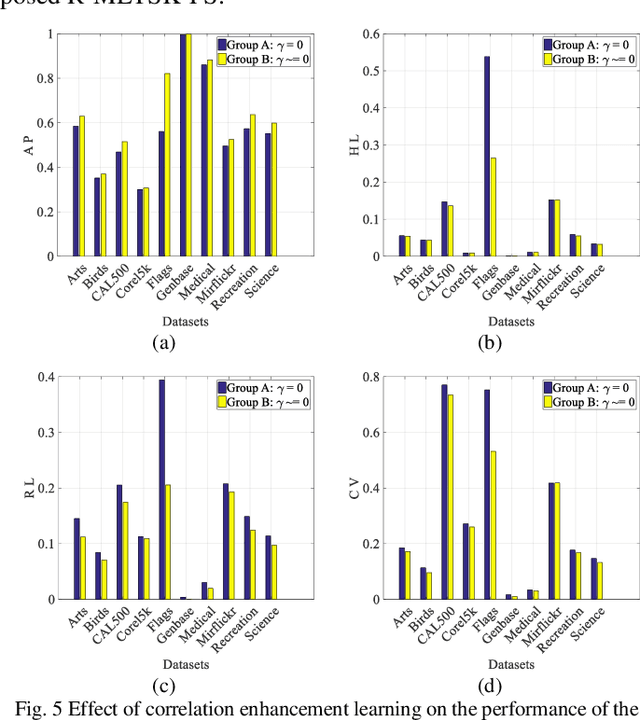
Model transparency, label correlation learning and the robust-ness to label noise are crucial for multilabel learning. However, few existing methods study these three characteristics simultaneously. To address this challenge, we propose the robust multilabel Takagi-Sugeno-Kang fuzzy system (R-MLTSK-FS) with three mechanisms. First, we design a soft label learning mechanism to reduce the effect of label noise by explicitly measuring the interactions between labels, which is also the basis of the other two mechanisms. Second, the rule-based TSK FS is used as the base model to efficiently model the inference relationship be-tween features and soft labels in a more transparent way than many existing multilabel models. Third, to further improve the performance of multilabel learning, we build a correlation enhancement learning mechanism based on the soft label space and the fuzzy feature space. Extensive experiments are conducted to demonstrate the superiority of the proposed method.
Graph Fuzzy System: Concepts, Models and Algorithms
Oct 30, 2022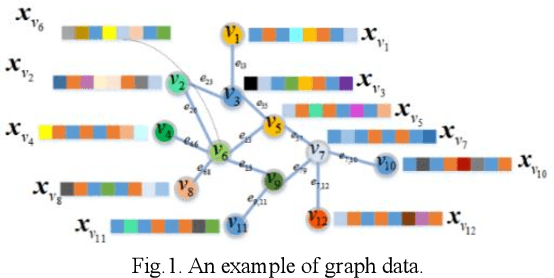
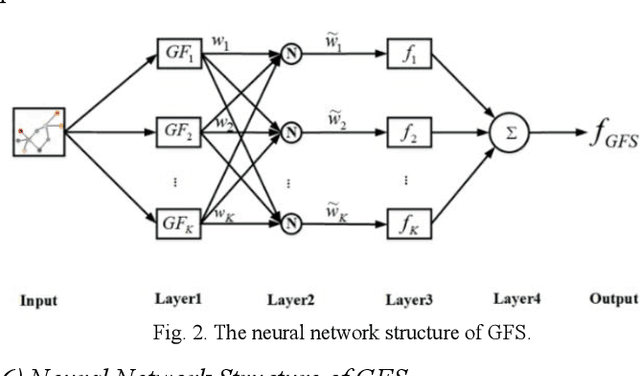

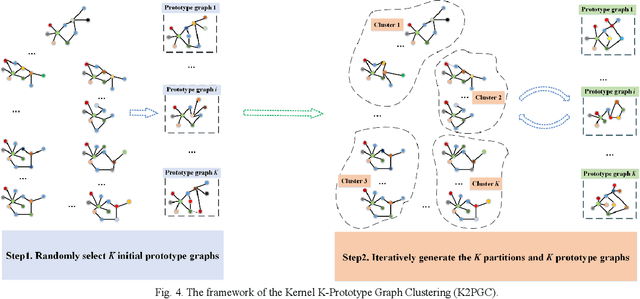
Fuzzy systems (FSs) have enjoyed wide applications in various fields, including pattern recognition, intelligent control, data mining and bioinformatics, which is attributed to the strong interpretation and learning ability. In traditional application scenarios, FSs are mainly applied to model Euclidean space data and cannot be used to handle graph data of non-Euclidean structure in nature, such as social networks and traffic route maps. Therefore, development of FS modeling method that is suitable for graph data and can retain the advantages of traditional FSs is an important research. To meet this challenge, a new type of FS for graph data modeling called Graph Fuzzy System (GFS) is proposed in this paper, where the concepts, modeling framework and construction algorithms are systematically developed. First, GFS related concepts, including graph fuzzy rule base, graph fuzzy sets and graph consequent processing unit (GCPU), are defined. A GFS modeling framework is then constructed and the antecedents and consequents of the GFS are presented and analyzed. Finally, a learning framework of GFS is proposed, in which a kernel K-prototype graph clustering (K2PGC) is proposed to develop the construction algorithm for the GFS antecedent generation, and then based on graph neural network (GNNs), consequent parameters learning algorithm is proposed for GFS. Specifically, three different versions of the GFS implementation algorithm are developed for comprehensive evaluations with experiments on various benchmark graph classification datasets. The results demonstrate that the proposed GFS inherits the advantages of both existing mainstream GNNs methods and conventional FSs methods while achieving better performance than the counterparts.
Dual Representation Learning for One-Step Clustering of Multi-View Data
Aug 30, 2022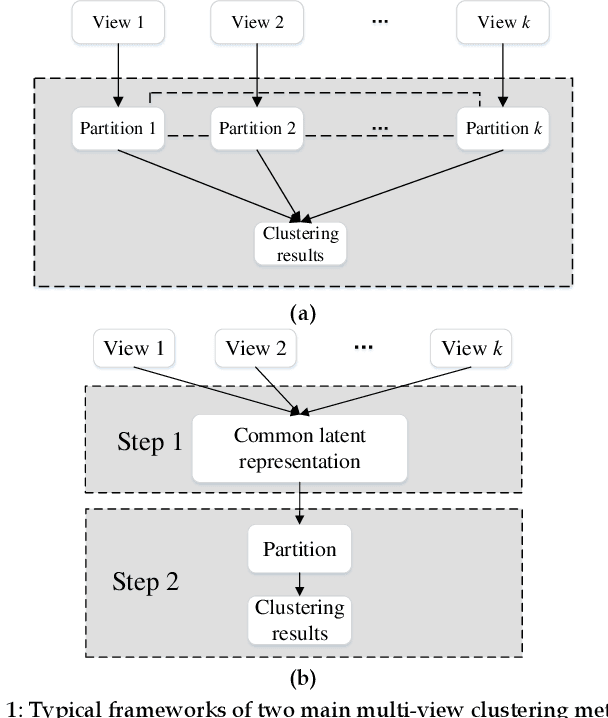

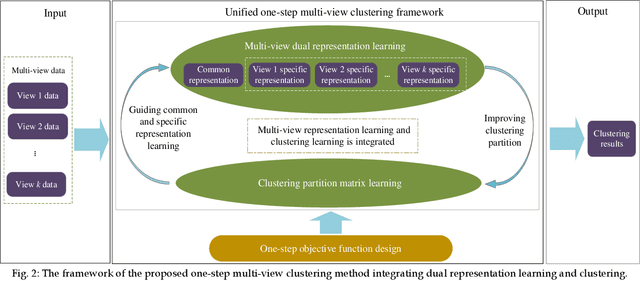

Multi-view data are commonly encountered in data mining applications. Effective extraction of information from multi-view data requires specific design of clustering methods to cater for data with multiple views, which is non-trivial and challenging. In this paper, we propose a novel one-step multi-view clustering method by exploiting the dual representation of both the common and specific information of different views. The motivation originates from the rationale that multi-view data contain not only the consistent knowledge between views but also the unique knowledge of each view. Meanwhile, to make the representation learning more specific to the clustering task, a one-step learning framework is proposed to integrate representation learning and clustering partition as a whole. With this framework, the representation learning and clustering partition mutually benefit each other, which effectively improve the clustering performance. Results from extensive experiments conducted on benchmark multi-view datasets clearly demonstrate the superiority of the proposed method.
A Novel TSK Fuzzy System Incorporating Multi-view Collaborative Transfer Learning for Personalized Epileptic EEG Detection
Nov 11, 2021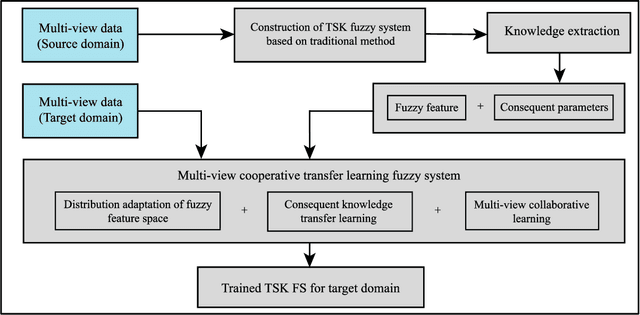
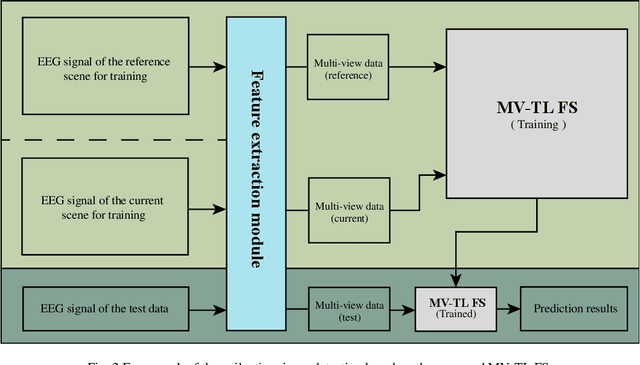
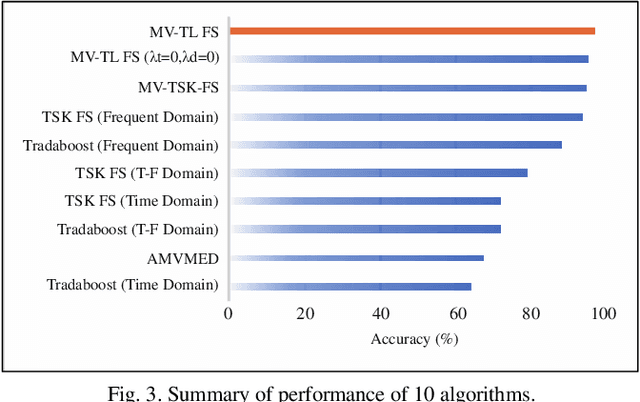
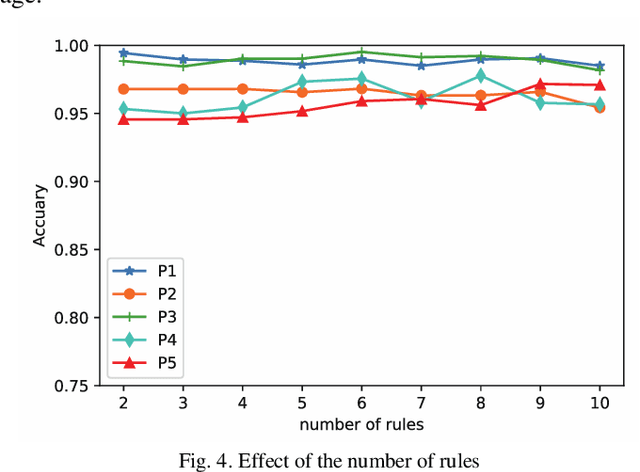
In clinical practice, electroencephalography (EEG) plays an important role in the diagnosis of epilepsy. EEG-based computer-aided diagnosis of epilepsy can greatly improve the ac-curacy of epilepsy detection while reducing the workload of physicians. However, there are many challenges in practical applications for personalized epileptic EEG detection (i.e., training of detection model for a specific person), including the difficulty in extracting effective features from one single view, the undesirable but common scenario of lacking sufficient training data in practice, and the no guarantee of identically distributed training and test data. To solve these problems, we propose a TSK fuzzy system-based epilepsy detection algorithm that integrates multi-view collaborative transfer learning. To address the challenge due to the limitation of single-view features, multi-view learning ensures the diversity of features by extracting them from different views. The lack of training data for building a personalized detection model is tackled by leveraging the knowledge from the source domain (reference scene) to enhance the performance of the target domain (current scene of interest), where mismatch of data distributions between the two domains is resolved with adaption technique based on maximum mean discrepancy. Notably, the transfer learning and multi-view feature extraction are performed at the same time. Furthermore, the fuzzy rules of the TSK fuzzy system equip the model with strong fuzzy logic inference capability. Hence, the proposed method has the potential to detect epileptic EEG signals effectively, which is demonstrated with the positive results from a large number of experiments on the CHB-MIT dataset.
TSK Fuzzy System Towards Few Labeled Incomplete Multi-View Data Classification
Oct 08, 2021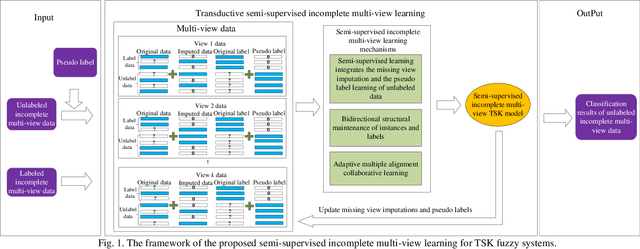
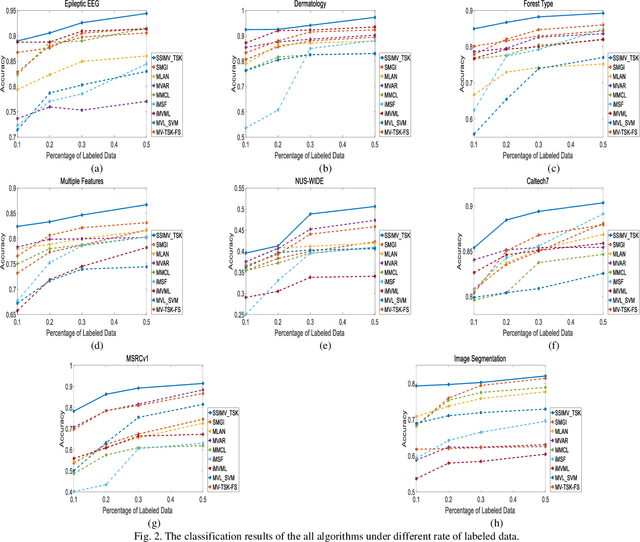
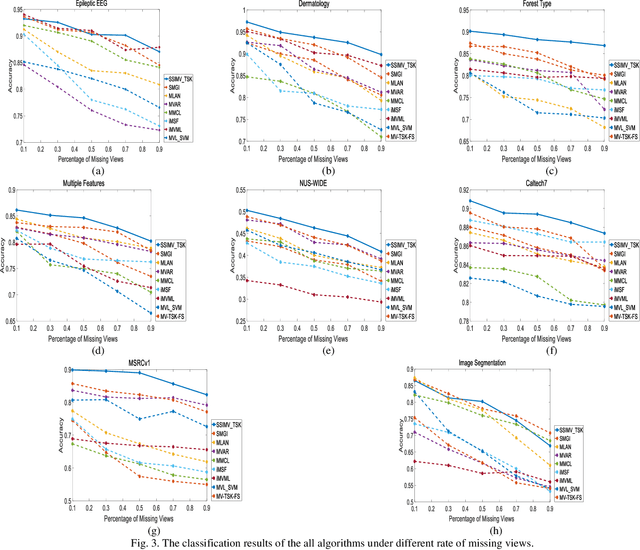
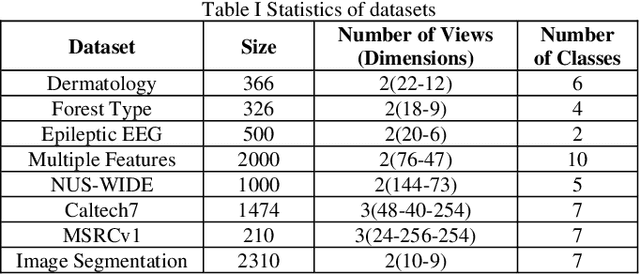
Data collected by multiple methods or from multiple sources is called multi-view data. To make full use of the multi-view data, multi-view learning plays an increasingly important role. Traditional multi-view learning methods rely on a large number of labeled and completed multi-view data. However, it is expensive and time-consuming to obtain a large number of labeled multi-view data in real-world applications. Moreover, multi-view data is often incomplete because of data collection failures, self-deficiency, or other reasons. Therefore, we may have to face the problem of fewer labeled and incomplete multi-view data in real application scenarios. In this paper, a transductive semi-supervised incomplete multi-view TSK fuzzy system modeling method (SSIMV_TSK) is proposed to address these challenges. First, in order to alleviate the dependency on labeled data and keep the model interpretable, the proposed method integrates missing view imputation, pseudo label learning of unlabeled data, and fuzzy system modeling into a single process to yield a model with interpretable fuzzy rules. Then, two new mechanisms, i.e. the bidirectional structural preservation of instance and label, as well as the adaptive multiple alignment collaborative learning, are proposed to improve the robustness of the model. The proposed method has the following distinctive characteristics: 1) it can deal with the incomplete and few labeled multi-view data simultaneously; 2) it integrates the missing view imputation and model learning as a single process, which is more efficient than the traditional two-step strategy; 3) attributed to the interpretable fuzzy inference rules, this method is more interpretable. Experimental results on real datasets show that the proposed method significantly outperforms the state-of-the-art methods.
Double-Coupling Learning for Multi-Task Data Stream Classification
Aug 15, 2019
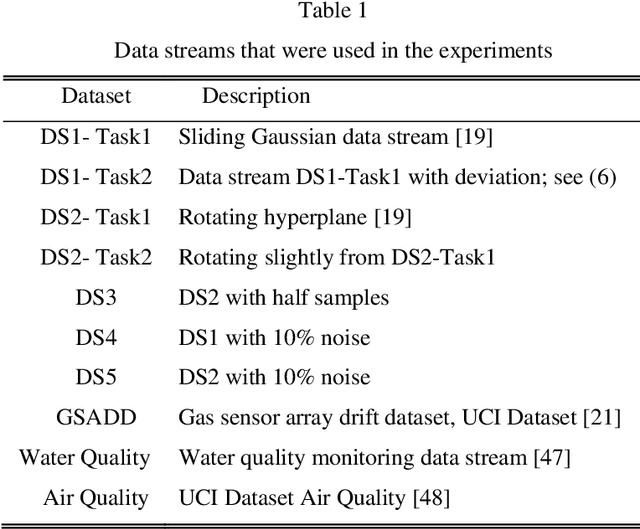
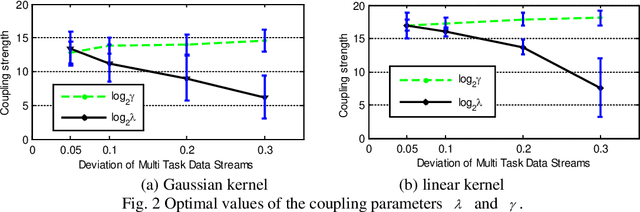

Data stream classification methods demonstrate promising performance on a single data stream by exploring the cohesion in the data stream. However, multiple data streams that involve several correlated data streams are common in many practical scenarios, which can be viewed as multi-task data streams. Instead of handling them separately, it is beneficial to consider the correlations among the multi-task data streams for data stream modeling tasks. In this regard, a novel classification method called double-coupling support vector machines (DC-SVM), is proposed for classifying them simultaneously. DC-SVM considers the external correlations between multiple data streams, while handling the internal relationship within the individual data stream. Experimental results on artificial and real-world multi-task data streams demonstrate that the proposed method outperforms traditional data stream classification methods.