 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Multimodal Models with Adaptive Sparsity and KV Cache Compression
Jul 28, 2025Large multimodal models (LMMs) have advanced significantly by integrating visual encoders with extensive language models, enabling robust reasoning capabilities. However, compressing LMMs for deployment on edge devices remains a critical challenge. In this work, we propose an adaptive search algorithm that optimizes sparsity and KV cache compression to enhance LMM efficiency. Utilizing the Tree-structured Parzen Estimator, our method dynamically adjusts pruning ratios and KV cache quantization bandwidth across different LMM layers, using model performance as the optimization objective. This approach uniquely combines pruning with key-value cache quantization and incorporates a fast pruning technique that eliminates the need for additional fine-tuning or weight adjustments, achieving efficient compression without compromising accuracy. Comprehensive evaluations on benchmark datasets, including LLaVA-1.5 7B and 13B, demonstrate our method superiority over state-of-the-art techniques such as SparseGPT and Wanda across various compression levels. Notably, our framework automatic allocation of KV cache compression resources sets a new standard in LMM optimization, delivering memory efficiency without sacrificing much performance.
Multi-view Fuzzy Representation Learning with Rules based Model
Sep 20, 2023Unsupervised multi-view representation learning has been extensively studied for mining multi-view data. However, some critical challenges remain. On the one hand, the existing methods cannot explore multi-view data comprehensively since they usually learn a common representation between views, given that multi-view data contains both the common information between views and the specific information within each view. On the other hand, to mine the nonlinear relationship between data, kernel or neural network methods are commonly used for multi-view representation learning. However, these methods are lacking in interpretability. To this end, this paper proposes a new multi-view fuzzy representation learning method based on the interpretable Takagi-Sugeno-Kang (TSK) fuzzy system (MVRL_FS). The method realizes multi-view representation learning from two aspects. First, multi-view data are transformed into a high-dimensional fuzzy feature space, while the common information between views and specific information of each view are explored simultaneously. Second, a new regularization method based on L_(2,1)-norm regression is proposed to mine the consistency information between views, while the geometric structure of the data is preserved through the Laplacian graph. Finally, extensive experiments on many benchmark multi-view datasets are conducted to validate the superiority of the proposed method.
TSK Fuzzy System Towards Few Labeled Incomplete Multi-View Data Classification
Oct 08, 2021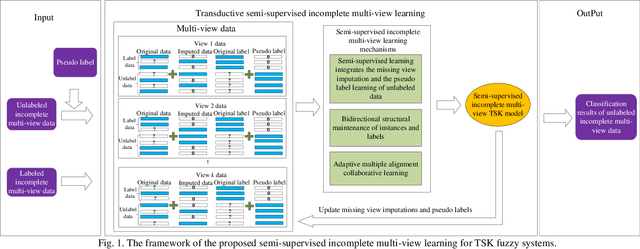
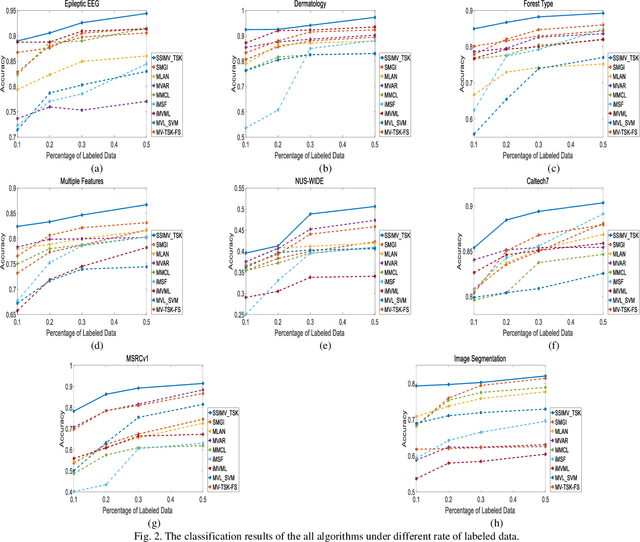
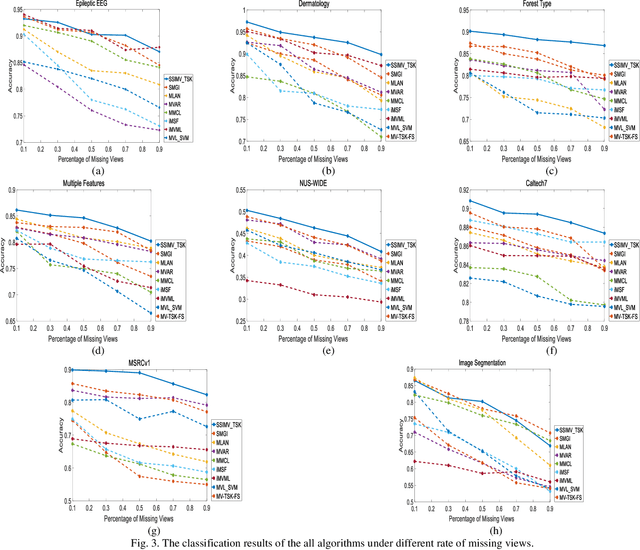
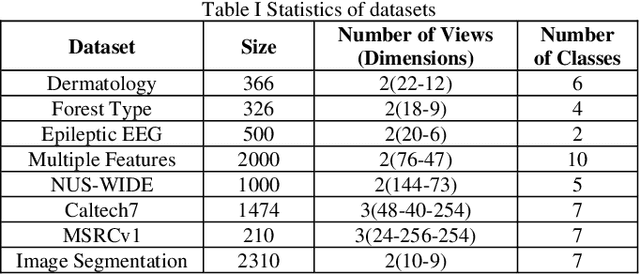
Data collected by multiple methods or from multiple sources is called multi-view data. To make full use of the multi-view data, multi-view learning plays an increasingly important role. Traditional multi-view learning methods rely on a large number of labeled and completed multi-view data. However, it is expensive and time-consuming to obtain a large number of labeled multi-view data in real-world applications. Moreover, multi-view data is often incomplete because of data collection failures, self-deficiency, or other reasons. Therefore, we may have to face the problem of fewer labeled and incomplete multi-view data in real application scenarios. In this paper, a transductive semi-supervised incomplete multi-view TSK fuzzy system modeling method (SSIMV_TSK) is proposed to address these challenges. First, in order to alleviate the dependency on labeled data and keep the model interpretable, the proposed method integrates missing view imputation, pseudo label learning of unlabeled data, and fuzzy system modeling into a single process to yield a model with interpretable fuzzy rules. Then, two new mechanisms, i.e. the bidirectional structural preservation of instance and label, as well as the adaptive multiple alignment collaborative learning, are proposed to improve the robustness of the model. The proposed method has the following distinctive characteristics: 1) it can deal with the incomplete and few labeled multi-view data simultaneously; 2) it integrates the missing view imputation and model learning as a single process, which is more efficient than the traditional two-step strategy; 3) attributed to the interpretable fuzzy inference rules, this method is more interpretable. Experimental results on real datasets show that the proposed method significantly outperforms the state-of-the-art methods.
Multi-view Clustering with the Cooperation of Visible and Hidden Views
Aug 12, 2019
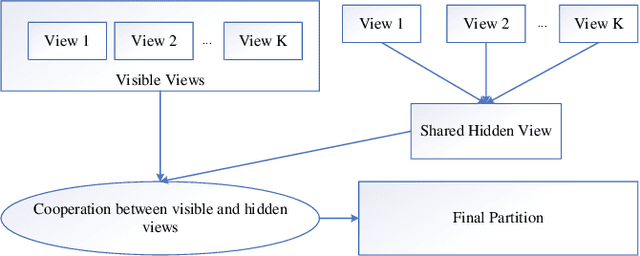
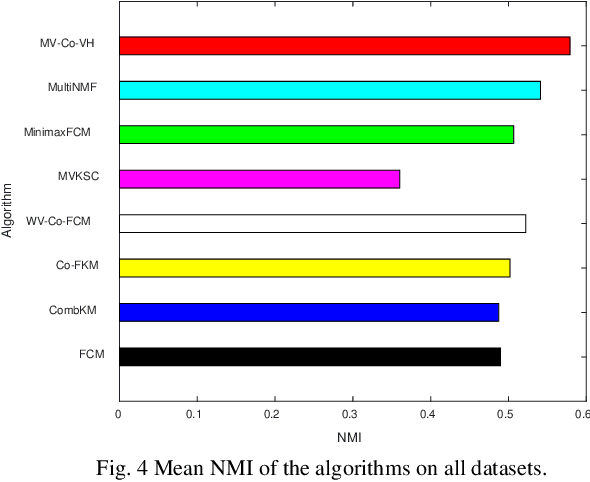
Multi-view data are becoming common in real-world modeling tasks and many multi-view data clustering algorithms have thus been proposed. The existing algorithms usually focus on the cooperation of different views in the original space but neglect the influence of the hidden information among these different visible views, or they only consider the hidden information between the views. The algorithms are therefore not efficient since the available information is not fully excavated, particularly the otherness information in different views and the consistency information between them. In practice, the otherness and consistency information in multi-view data are both very useful for effective clustering analyses. In this study, a Multi-View clustering algorithm developed with the Cooperation of Visible and Hidden views, i.e., MV-Co-VH, is proposed. The MV-Co-VH algorithm first projects the multiple views from different visible spaces to the common hidden space by using the non-negative matrix factorization (NMF) strategy to obtain the common hidden view data. Collaborative learning is then implemented in the clustering procedure based on the visible views and the shared hidden view. The results of extensive experiments on UCI multi-view datasets and real-world image multi-view datasets show that the clustering performance of the proposed algorithm is competitive with or even better than that of the existing algorithms.
Multi-View Fuzzy Clustering with The Alternative Learning between Shared Hidden Space and Partition
Aug 12, 2019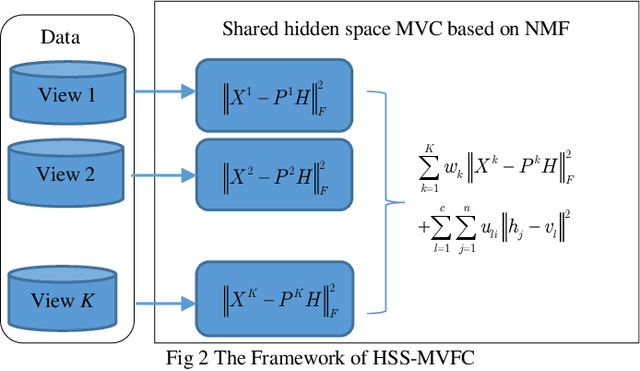
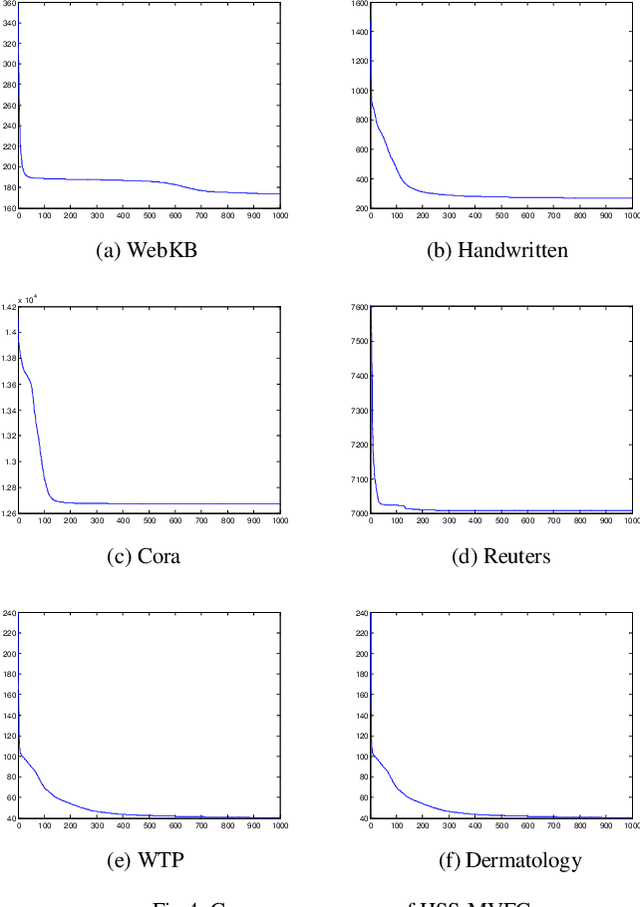

As the multi-view data grows in the real world, multi-view clus-tering has become a prominent technique in data mining, pattern recognition, and machine learning. How to exploit the relation-ship between different views effectively using the characteristic of multi-view data has become a crucial challenge. Aiming at this, a hidden space sharing multi-view fuzzy clustering (HSS-MVFC) method is proposed in the present study. This method is based on the classical fuzzy c-means clustering model, and obtains associ-ated information between different views by introducing shared hidden space. Especially, the shared hidden space and the fuzzy partition can be learned alternatively and contribute to each other. Meanwhile, the proposed method uses maximum entropy strategy to control the weights of different views while learning the shared hidden space. The experimental result shows that the proposed multi-view clustering method has better performance than many related clustering methods.
Concise Fuzzy System Modeling Integrating Soft Subspace Clustering and Sparse Learning
Apr 24, 2019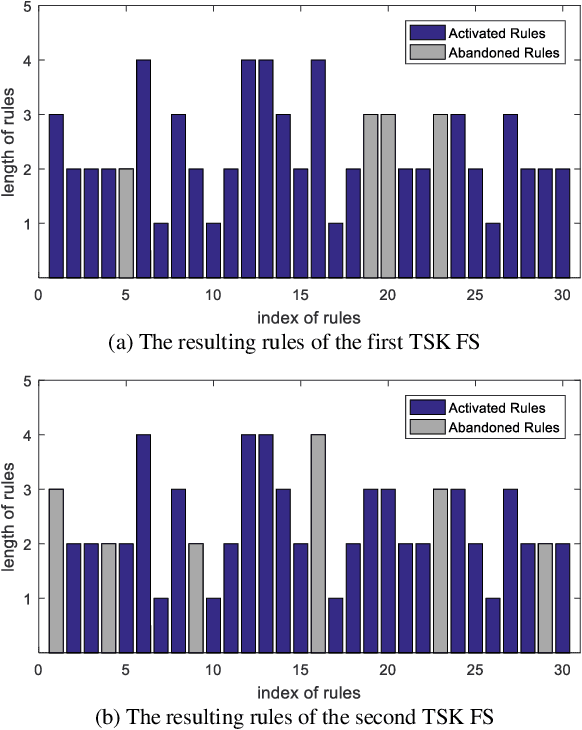
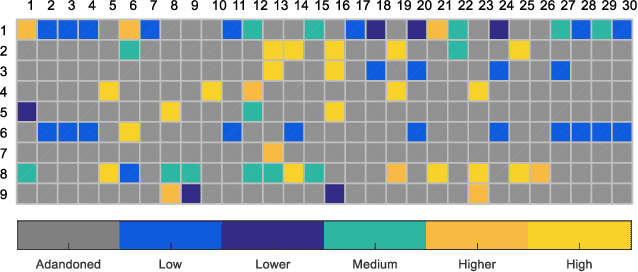
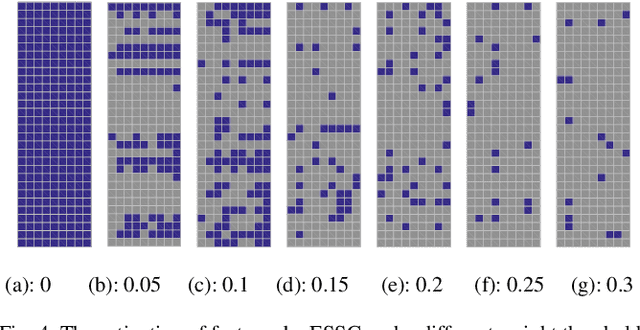
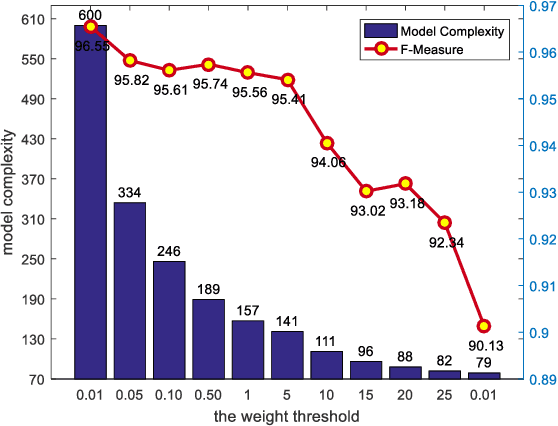
The superior interpretability and uncertainty modeling ability of Takagi-Sugeno-Kang fuzzy system (TSK FS) make it possible to describe complex nonlinear systems intuitively and efficiently. However, classical TSK FS usually adopts the whole feature space of the data for model construction, which can result in lengthy rules for high-dimensional data and lead to degeneration in interpretability. Furthermore, for highly nonlinear modeling task, it is usually necessary to use a large number of rules which further weakens the clarity and interpretability of TSK FS. To address these issues, a concise zero-order TSK FS construction method, called ESSC-SL-CTSK-FS, is proposed in this paper by integrating the techniques of enhanced soft subspace clustering (ESSC) and sparse learning (SL). In this method, ESSC is used to generate the antecedents and various sparse subspace for different fuzzy rules, whereas SL is used to optimize the consequent parameters of the fuzzy rules, based on which the number of fuzzy rules can be effectively reduced. Finally, the proposed ESSC-SL-CTSK-FS method is used to construct con-cise zero-order TSK FS that can explain the scenes in high-dimensional data modeling more clearly and easily. Experiments are conducted on various real-world datasets to confirm the advantages.
Multi-View Fuzzy Logic System with the Cooperation between Visible and Hidden Views
Jul 23, 2018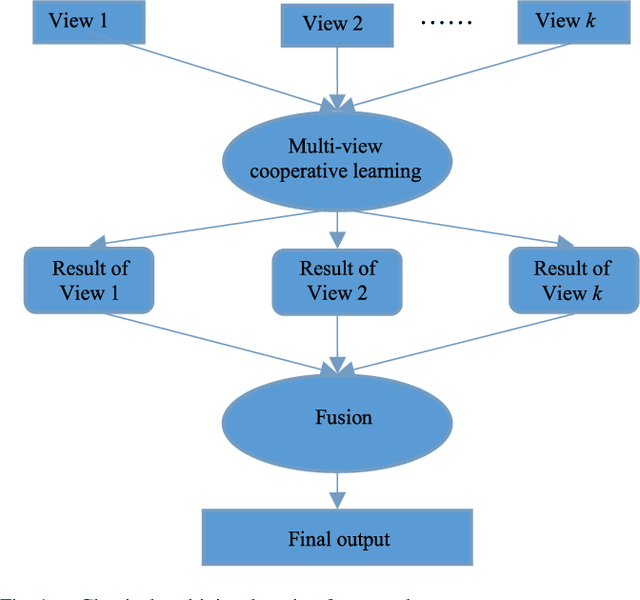
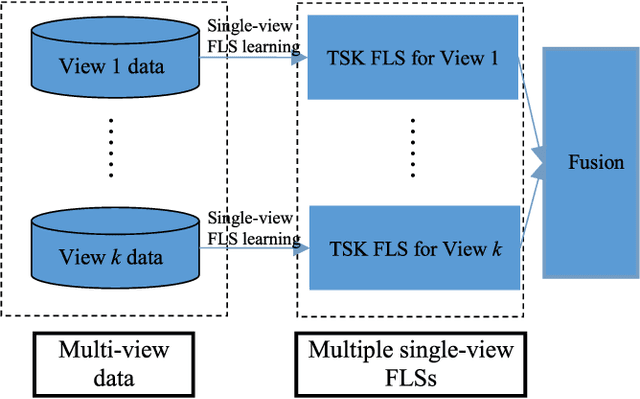
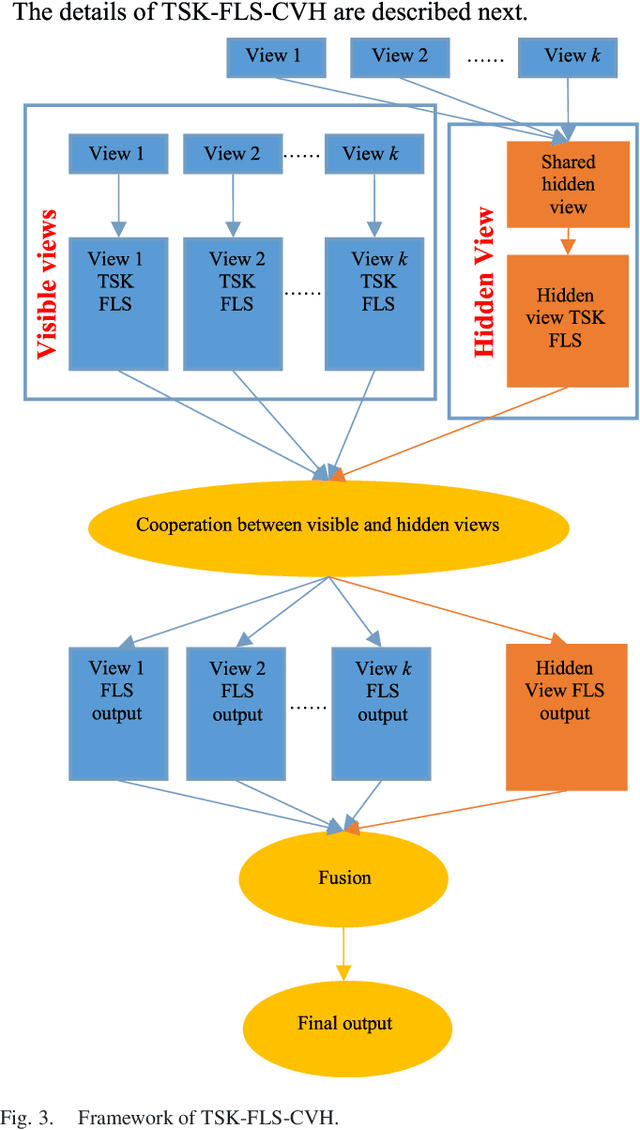
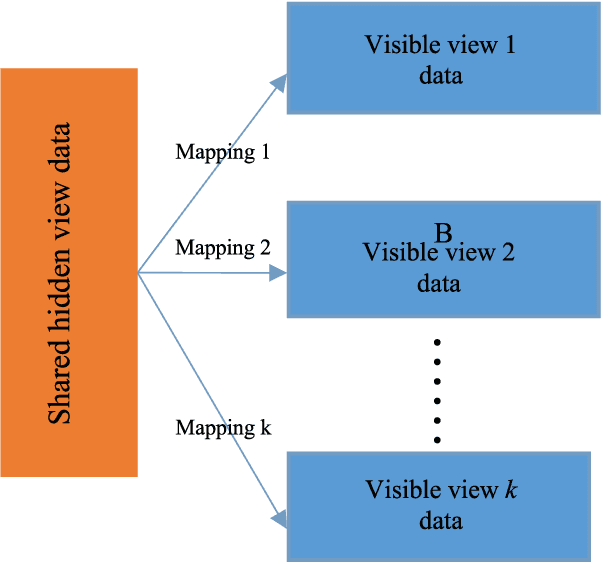
Multi-view datasets are frequently encountered in learning tasks, such as web data mining and multimedia information analysis. Given a multi-view dataset, traditional learning algorithms usually decompose it into several single-view datasets, from each of which a single-view model is learned. In contrast, a multi-view learning algorithm can achieve better performance by cooperative learning on the multi-view data. However, existing multi-view approaches mainly focus on the views that are visible and ignore the hidden information behind the visible views, which usually contains some intrinsic information of the multi-view data, or vice versa. To address this problem, this paper proposes a multi-view fuzzy logic system, which utilizes both the hidden information shared by the multiple visible views and the information of each visible view. Extensive experiments were conducted to validate its effectiveness.