 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Implementing BERT and fine-tuned RobertA to detect AI generated news by ChatGPT
Jun 09, 2023

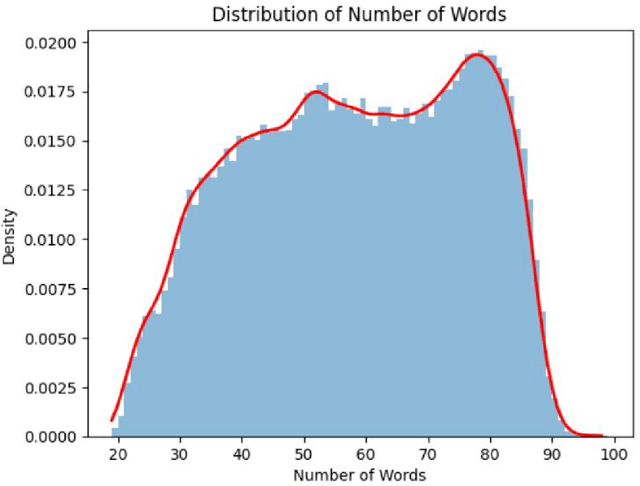
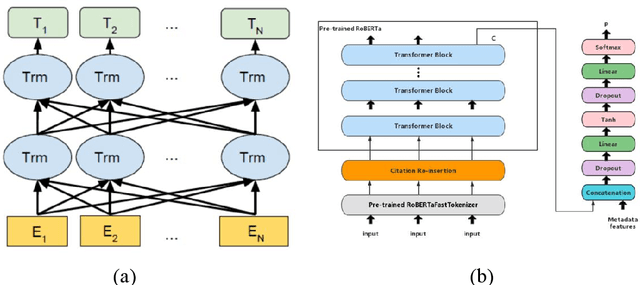
The abundance of information on social media has increased the necessity of accurate real-time rumour detection. Manual techniques of identifying and verifying fake news generated by AI tools are impracticable and time-consuming given the enormous volume of information generated every day. This has sparked an increase in interest in creating automated systems to find fake news on the Internet. The studies in this research demonstrate that the BERT and RobertA models with fine-tuning had the best success in detecting AI generated news. With a score of 98%, tweaked RobertA in particular showed excellent precision. In conclusion, this study has shown that neural networks can be used to identify bogus news AI generation news created by ChatGPT. The RobertA and BERT models' excellent performance indicates that these models can play a critical role in the fight against misinformation.
Testing the Ability of Language Models to Interpret Figurative Language
Apr 26, 2022



Figurative and metaphorical language are commonplace in discourse, and figurative expressions play an important role in communication and cognition. However, figurative language has been a relatively under-studied area in NLP, and it remains an open question to what extent modern language models can interpret nonliteral phrases. To address this question, we introduce Fig-QA, a Winograd-style nonliteral language understanding task consisting of correctly interpreting paired figurative phrases with divergent meanings. We evaluate the performance of several state-of-the-art language models on this task, and find that although language models achieve performance significantly over chance, they still fall short of human performance, particularly in zero- or few-shot settings. This suggests that further work is needed to improve the nonliteral reasoning capabilities of language models.
Graph-Fraudster: Adversarial Attacks on Graph Neural Network Based Vertical Federated Learning
Oct 13, 2021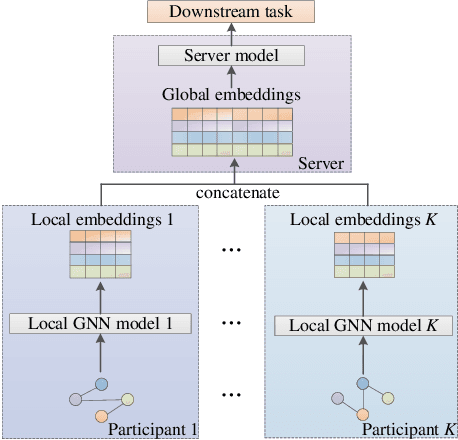
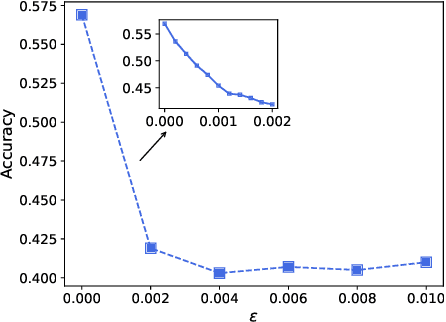
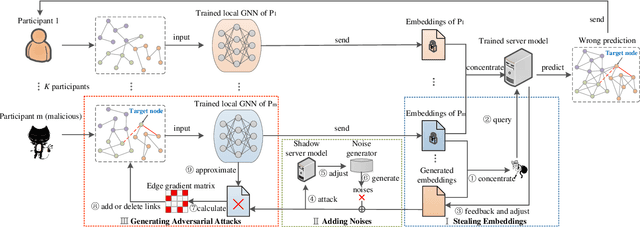
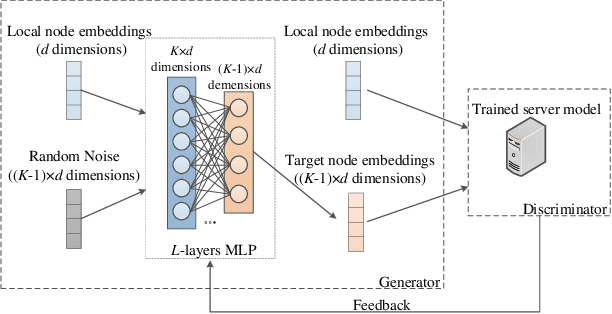
Graph neural network (GNN) models have achieved great success on graph representation learning. Challenged by large scale private data collection from user-side, GNN models may not be able to reflect the excellent performance, without rich features and complete adjacent relationships. Addressing to the problem, vertical federated learning (VFL) is proposed to implement local data protection through training a global model collaboratively. Consequently, for graph-structured data, it is natural idea to construct VFL framework with GNN models. However, GNN models are proven to be vulnerable to adversarial attacks. Whether the vulnerability will be brought into the VFL has not been studied. In this paper, we devote to study the security issues of GNN based VFL (GVFL), i.e., robustness against adversarial attacks. Further, we propose an adversarial attack method, named Graph-Fraudster. It generates adversarial perturbations based on the noise-added global node embeddings via GVFL's privacy leakage, and the gradient of pairwise node. First, it steals the global node embeddings and sets up a shadow server model for attack generator. Second, noises are added into node embeddings to confuse the shadow server model. At last, the gradient of pairwise node is used to generate attacks with the guidance of noise-added node embeddings. To the best of our knowledge, this is the first study of adversarial attacks on GVFL. The extensive experiments on five benchmark datasets demonstrate that Graph-Fraudster performs better than three possible baselines in GVFL. Furthermore, Graph-Fraudster can remain a threat to GVFL even if two possible defense mechanisms are applied. This paper reveals that GVFL is vulnerable to adversarial attack similar to centralized GNN models.
Salient Feature Extractor for Adversarial Defense on Deep Neural Networks
May 14, 2021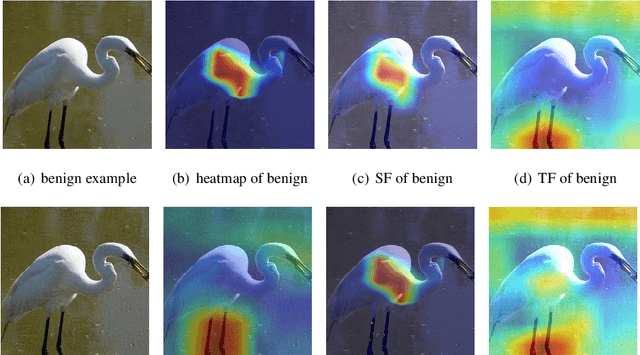

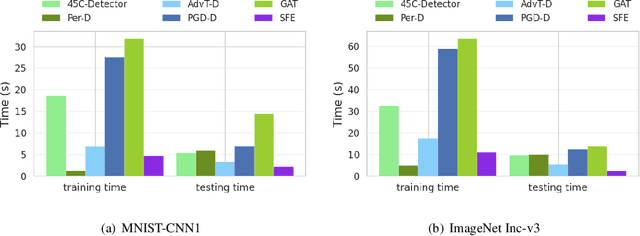
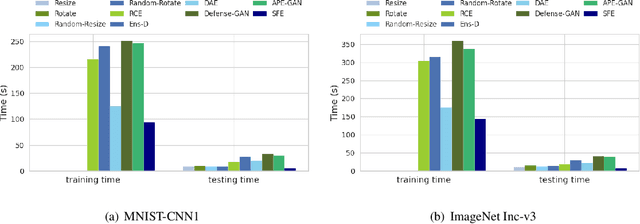
Recent years have witnessed unprecedented success achieved by deep learning models in the field of computer vision. However, their vulnerability towards carefully crafted adversarial examples has also attracted the increasing attention of researchers. Motivated by the observation that adversarial examples are due to the non-robust feature learned from the original dataset by models, we propose the concepts of salient feature(SF) and trivial feature(TF). The former represents the class-related feature, while the latter is usually adopted to mislead the model. We extract these two features with coupled generative adversarial network model and put forward a novel detection and defense method named salient feature extractor (SFE) to defend against adversarial attacks. Concretely, detection is realized by separating and comparing the difference between SF and TF of the input. At the same time, correct labels are obtained by re-identifying SF to reach the purpose of defense. Extensive experiments are carried out on MNIST, CIFAR-10, and ImageNet datasets where SFE shows state-of-the-art results in effectiveness and efficiency compared with baselines. Furthermore, we provide an interpretable understanding of the defense and detection process.
SUPER: A Novel Lane Detection System
May 14, 2020

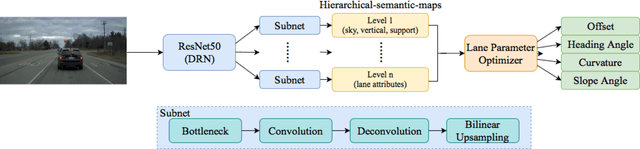
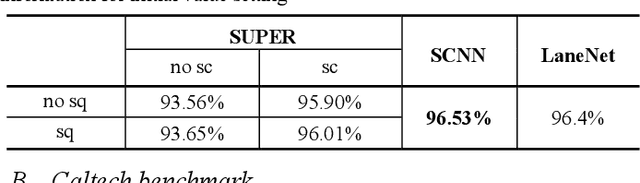
AI-based lane detection algorithms were actively studied over the last few years. Many have demonstrated superior performance compared with traditional feature-based methods. The accuracy, however, is still generally in the low 80% or high 90%, or even lower when challenging images are used. In this paper, we propose a real-time lane detection system, called Scene Understanding Physics-Enhanced Real-time (SUPER) algorithm. The proposed method consists of two main modules: 1) a hierarchical semantic segmentation network as the scene feature extractor and 2) a physics enhanced multi-lane parameter optimization module for lane inference. We train the proposed system using heterogeneous data from Cityscapes, Vistas and Apollo, and evaluate the performance on four completely separate datasets (that were never seen before), including Tusimple, Caltech, URBAN KITTI-ROAD, and X-3000. The proposed approach performs the same or better than lane detection models already trained on the same dataset and performs well even on datasets it was never trained on. Real-world vehicle tests were also conducted. Preliminary test results show promising real-time lane-detection performance compared with the Mobileye.
Multi-View Fuzzy Clustering with The Alternative Learning between Shared Hidden Space and Partition
Aug 12, 2019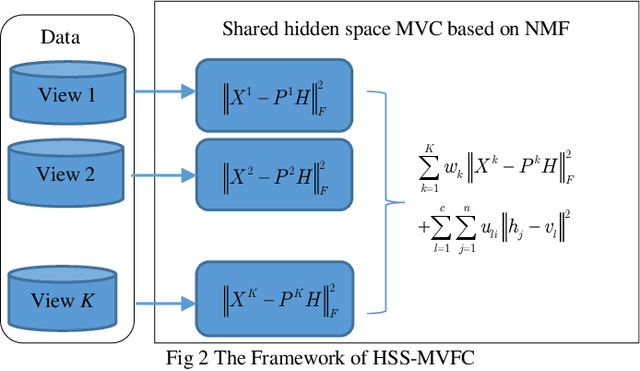
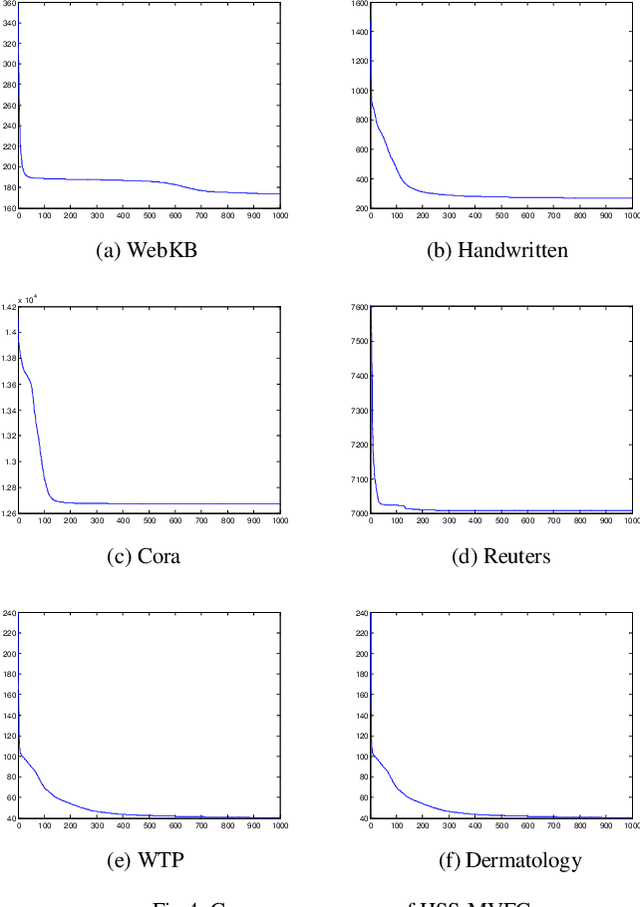

As the multi-view data grows in the real world, multi-view clus-tering has become a prominent technique in data mining, pattern recognition, and machine learning. How to exploit the relation-ship between different views effectively using the characteristic of multi-view data has become a crucial challenge. Aiming at this, a hidden space sharing multi-view fuzzy clustering (HSS-MVFC) method is proposed in the present study. This method is based on the classical fuzzy c-means clustering model, and obtains associ-ated information between different views by introducing shared hidden space. Especially, the shared hidden space and the fuzzy partition can be learned alternatively and contribute to each other. Meanwhile, the proposed method uses maximum entropy strategy to control the weights of different views while learning the shared hidden space. The experimental result shows that the proposed multi-view clustering method has better performance than many related clustering methods.
Concise Fuzzy System Modeling Integrating Soft Subspace Clustering and Sparse Learning
Apr 24, 2019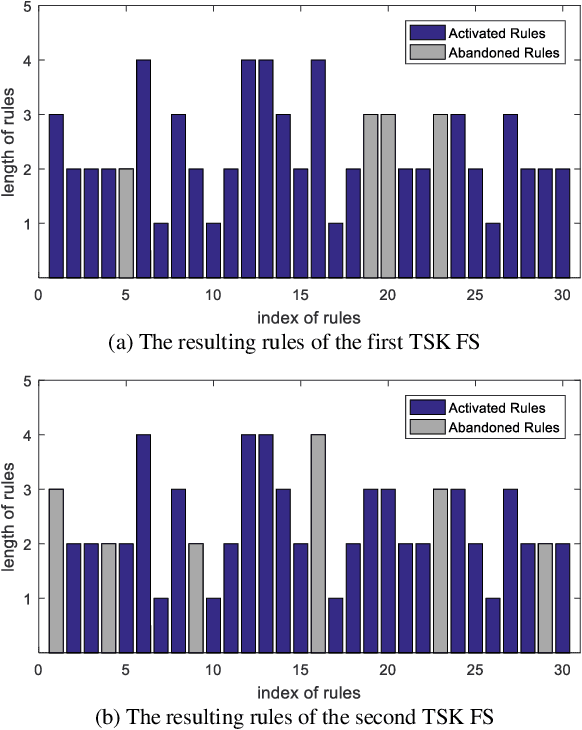
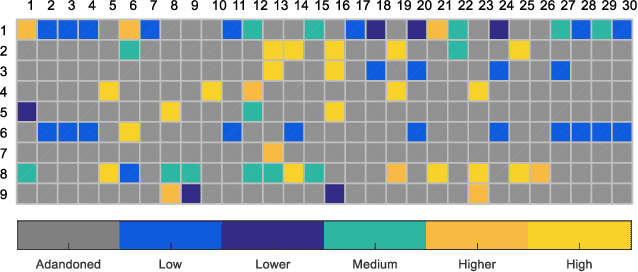
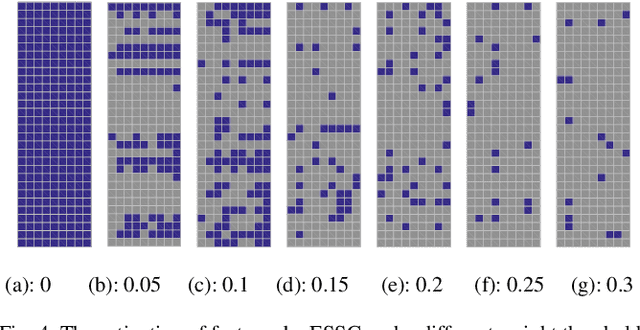
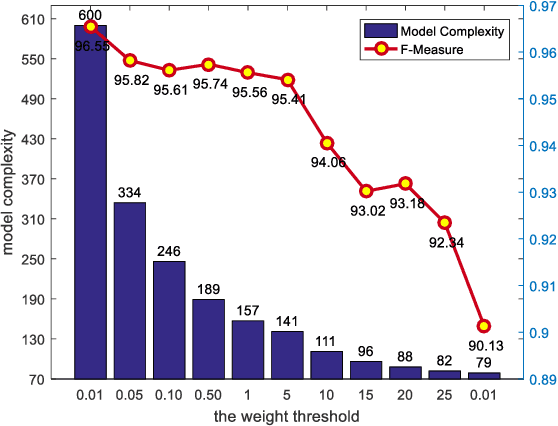
The superior interpretability and uncertainty modeling ability of Takagi-Sugeno-Kang fuzzy system (TSK FS) make it possible to describe complex nonlinear systems intuitively and efficiently. However, classical TSK FS usually adopts the whole feature space of the data for model construction, which can result in lengthy rules for high-dimensional data and lead to degeneration in interpretability. Furthermore, for highly nonlinear modeling task, it is usually necessary to use a large number of rules which further weakens the clarity and interpretability of TSK FS. To address these issues, a concise zero-order TSK FS construction method, called ESSC-SL-CTSK-FS, is proposed in this paper by integrating the techniques of enhanced soft subspace clustering (ESSC) and sparse learning (SL). In this method, ESSC is used to generate the antecedents and various sparse subspace for different fuzzy rules, whereas SL is used to optimize the consequent parameters of the fuzzy rules, based on which the number of fuzzy rules can be effectively reduced. Finally, the proposed ESSC-SL-CTSK-FS method is used to construct con-cise zero-order TSK FS that can explain the scenes in high-dimensional data modeling more clearly and easily. Experiments are conducted on various real-world datasets to confirm the advantages.