 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Rule-based Differentiable Representation Learning
Mar 16, 2025Representation learning has emerged as a crucial focus in machine and deep learning, involving the extraction of meaningful and useful features and patterns from the input data, thereby enhancing the performance of various downstream tasks such as classification, clustering, and prediction. Current mainstream representation learning methods primarily rely on non-linear data mining techniques such as kernel methods and deep neural networks to extract abstract knowledge from complex datasets. However, most of these methods are black-box, lacking transparency and interpretability in the learning process, which constrains their practical utility. To this end, this paper introduces a novel representation learning method grounded in an interpretable fuzzy rule-based model. Specifically, it is built upon the Takagi-Sugeno-Kang fuzzy system (TSK-FS) to initially map input data to a high-dimensional fuzzy feature space through the antecedent part of the TSK-FS. Subsequently, a novel differentiable optimization method is proposed for the consequence part learning which can preserve the model's interpretability and transparency while further exploring the nonlinear relationships within the data. This optimization method retains the essence of traditional optimization, with certain parts of the process parameterized corresponding differentiable modules constructed, and a deep optimization process implemented. Consequently, this method not only enhances the model's performance but also ensures its interpretability. Moreover, a second-order geometry preservation method is introduced to further improve the robustness of the proposed method. Extensive experiments conducted on various benchmark datasets validate the superiority of the proposed method, highlighting its potential for advancing representation learning methodologies.
XAgents: A Framework for Interpretable Rule-Based Multi-Agents Cooperation
Nov 21, 2024



Extracting implicit knowledge and logical reasoning abilities from large language models (LLMs) has consistently been a significant challenge. The advancement of multi-agent systems has further en-hanced the capabilities of LLMs. Inspired by the structure of multi-polar neurons (MNs), we propose the XAgents framework, an in-terpretable multi-agent cooperative framework based on the IF-THEN rule-based system. The IF-Parts of the rules are responsible for logical reasoning and domain membership calculation, while the THEN-Parts are comprised of domain expert agents that generate domain-specific contents. Following the calculation of the member-ship, XAgetns transmits the task to the disparate domain rules, which subsequently generate the various responses. These re-sponses are analogous to the answers provided by different experts to the same question. The final response is reached at by eliminat-ing the hallucinations and erroneous knowledge of the LLM through membership computation and semantic adversarial genera-tion of the various domain rules. The incorporation of rule-based interpretability serves to bolster user confidence in the XAgents framework. We evaluate the efficacy of XAgents through a com-parative analysis with the latest AutoAgents, in which XAgents demonstrated superior performance across three distinct datasets. We perform post-hoc interpretable studies with SHAP algorithm and case studies, proving the interpretability of XAgent in terms of input-output feature correlation and rule-based semantics.
Generative Fuzzy System for Sequence Generation
Nov 21, 2024



Generative Models (GMs), particularly Large Language Models (LLMs), have garnered significant attention in machine learning and artificial intelligence for their ability to generate new data by learning the statistical properties of training data and creating data that resemble the original. This capability offers a wide range of applications across various domains. However, the complex structures and numerous model parameters of GMs make the input-output processes opaque, complicating the understanding and control of outputs. Moreover, the purely data-driven learning mechanism limits GM's ability to acquire broader knowledge. There remains substantial potential for enhancing the robustness and generalization capabilities of GMs. In this work, we introduce the fuzzy system, a classical modeling method that combines data and knowledge-driven mechanisms, to generative tasks. We propose a novel Generative Fuzzy System framework, named GenFS, which integrates the deep learning capabilities of GM with the interpretability and dual-driven mechanisms of fuzzy systems. Specifically, we propose an end-to-end GenFS-based model for sequence generation, called FuzzyS2S. A series of experimental studies were conducted on 12 datasets, covering three distinct categories of generative tasks: machine translation, code generation, and summary generation. The results demonstrate that FuzzyS2S outperforms the Transformer in terms of accuracy and fluency. Furthermore, it exhibits better performance on some datasets compared to state-of-the-art models T5 and CodeT5.
EMOCPD: Efficient Attention-based Models for Computational Protein Design Using Amino Acid Microenvironment
Oct 29, 2024



Computational protein design (CPD) refers to the use of computational methods to design proteins. Traditional methods relying on energy functions and heuristic algorithms for sequence design are inefficient and do not meet the demands of the big data era in biomolecules, with their accuracy limited by the energy functions and search algorithms. Existing deep learning methods are constrained by the learning capabilities of the networks, failing to extract effective information from sparse protein structures, which limits the accuracy of protein design. To address these shortcomings, we developed an Efficient attention-based Models for Computational Protein Design using amino acid microenvironment (EMOCPD). It aims to predict the category of each amino acid in a protein by analyzing the three-dimensional atomic environment surrounding the amino acids, and optimize the protein based on the predicted high-probability potential amino acid categories. EMOCPD employs a multi-head attention mechanism to focus on important features in the sparse protein microenvironment and utilizes an inverse residual structure to optimize the network architecture. The proposed EMOCPD achieves over 80% accuracy on the training set and 68.33% and 62.32% accuracy on two independent test sets, respectively, surpassing the best comparative methods by over 10%. In protein design, the thermal stability and protein expression of the predicted mutants from EMOCPD show significant improvements compared to the wild type, effectively validating EMOCPD's potential in designing superior proteins. Furthermore, the predictions of EMOCPD are influenced positively, negatively, or have minimal impact based on the content of the 20 amino acids, categorizing amino acids as positive, negative, or neutral. Research findings indicate that EMOCPD is more suitable for designing proteins with lower contents of negative amino acids.
Multi-Label Takagi-Sugeno-Kang Fuzzy System
Sep 20, 2023
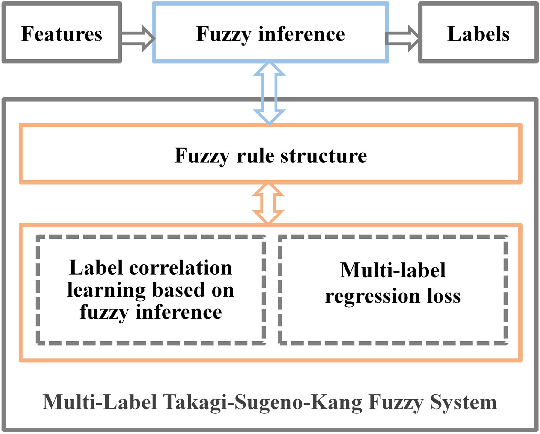
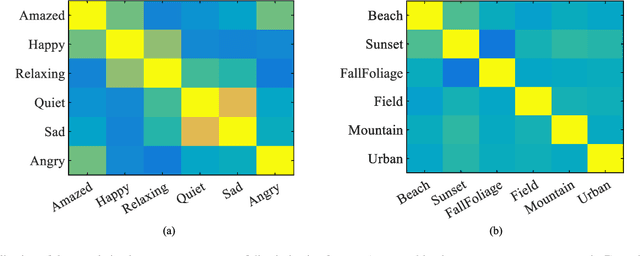
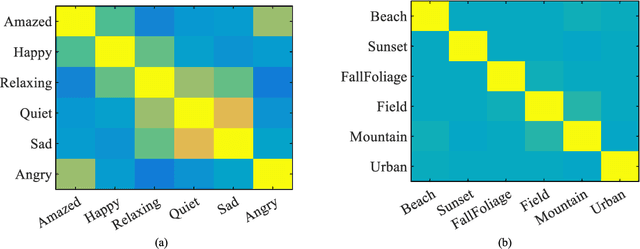
Multi-label classification can effectively identify the relevant labels of an instance from a given set of labels. However,the modeling of the relationship between the features and the labels is critical to the classification performance. To this end, we propose a new multi-label classification method, called Multi-Label Takagi-Sugeno-Kang Fuzzy System (ML-TSK FS), to improve the classification performance. The structure of ML-TSK FS is designed using fuzzy rules to model the relationship between features and labels. The fuzzy system is trained by integrating fuzzy inference based multi-label correlation learning with multi-label regression loss. The proposed ML-TSK FS is evaluated experimentally on 12 benchmark multi-label datasets. 1 The results show that the performance of ML-TSK FS is competitive with existing methods in terms of various evaluation metrics, indicating that it is able to model the feature-label relationship effectively using fuzzy inference rules and enhances the classification performance.
Multi-view Fuzzy Representation Learning with Rules based Model
Sep 20, 2023Unsupervised multi-view representation learning has been extensively studied for mining multi-view data. However, some critical challenges remain. On the one hand, the existing methods cannot explore multi-view data comprehensively since they usually learn a common representation between views, given that multi-view data contains both the common information between views and the specific information within each view. On the other hand, to mine the nonlinear relationship between data, kernel or neural network methods are commonly used for multi-view representation learning. However, these methods are lacking in interpretability. To this end, this paper proposes a new multi-view fuzzy representation learning method based on the interpretable Takagi-Sugeno-Kang (TSK) fuzzy system (MVRL_FS). The method realizes multi-view representation learning from two aspects. First, multi-view data are transformed into a high-dimensional fuzzy feature space, while the common information between views and specific information of each view are explored simultaneously. Second, a new regularization method based on L_(2,1)-norm regression is proposed to mine the consistency information between views, while the geometric structure of the data is preserved through the Laplacian graph. Finally, extensive experiments on many benchmark multi-view datasets are conducted to validate the superiority of the proposed method.
Cooperation Learning Enhanced Colonic Polyp Segmentation Based on Transformer-CNN Fusion
Jan 17, 2023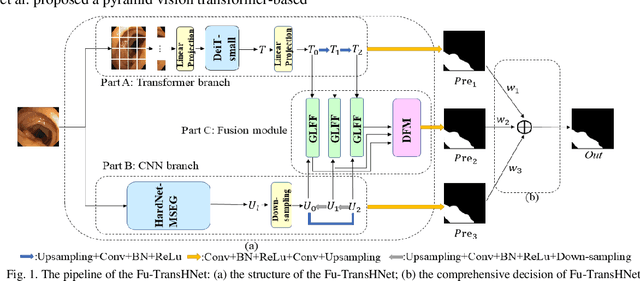
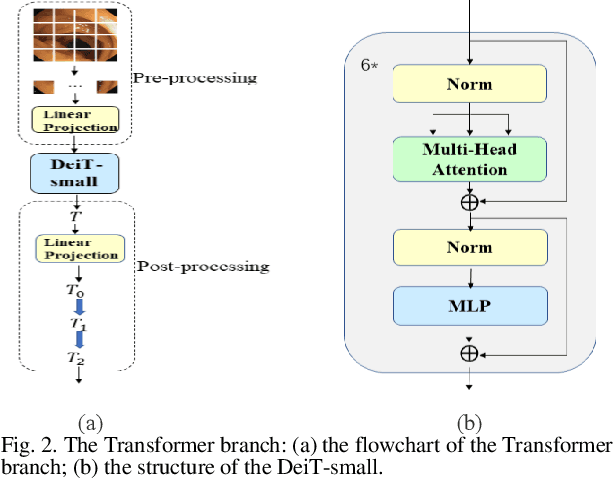
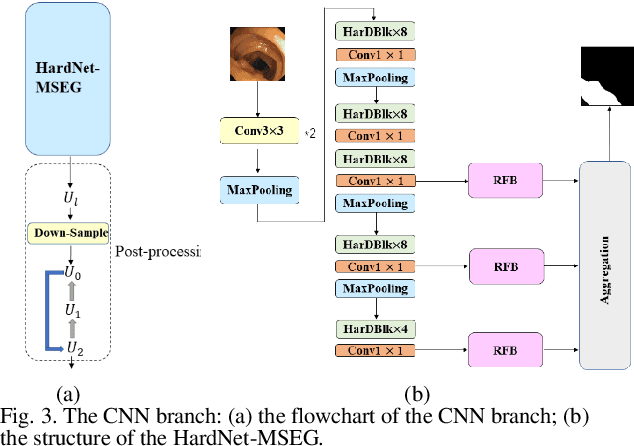
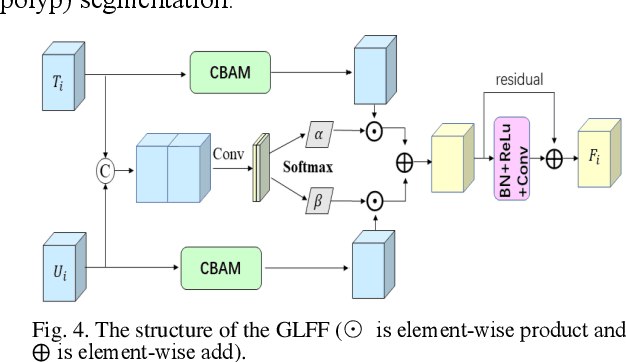
Traditional segmentation methods for colonic polyps are mainly designed based on low-level features. They could not accurately extract the location of small colonic polyps. Although the existing deep learning methods can improve the segmentation accuracy, their effects are still unsatisfied. To meet the above challenges, we propose a hybrid network called Fusion-Transformer-HardNetMSEG (i.e., Fu-TransHNet) in this study. Fu-TransHNet uses deep learning of different mechanisms to fuse each other and is enhanced with multi-view collaborative learning techniques. Firstly, the Fu-TransHNet utilizes the Transformer branch and the CNN branch to realize the global feature learning and local feature learning, respectively. Secondly, a fusion module is designed to integrate the features from two branches. The fusion module consists of two parts: 1) the Global-Local Feature Fusion (GLFF) part and 2) the Dense Fusion of Multi-scale features (DFM) part. The former is built to compensate the feature information mission from two branches at the same scale; the latter is constructed to enhance the feature representation. Thirdly, the above two branches and fusion modules utilize multi-view cooperative learning techniques to obtain their respective weights that denote their importance and then make a final decision comprehensively. Experimental results showed that the Fu-TransHNet network was superior to the existing methods on five widely used benchmark datasets. In particular, on the ETIS-LaribPolypDB dataset containing many small-target colonic polyps, the mDice obtained by Fu-TransHNet were 12.4% and 6.2% higher than the state-of-the-art methods HardNet-MSEG and TransFuse-s, respectively.
A Robust Multilabel Method Integrating Rule-based Transparent Model, Soft Label Correlation Learning and Label Noise Resistance
Jan 09, 2023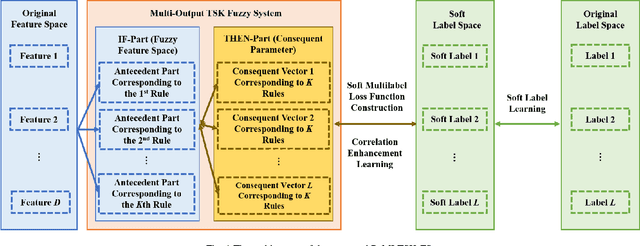
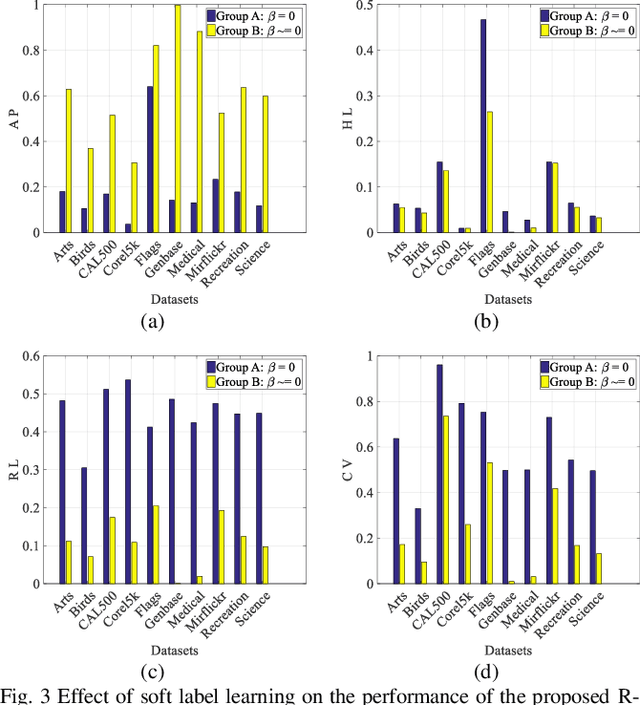
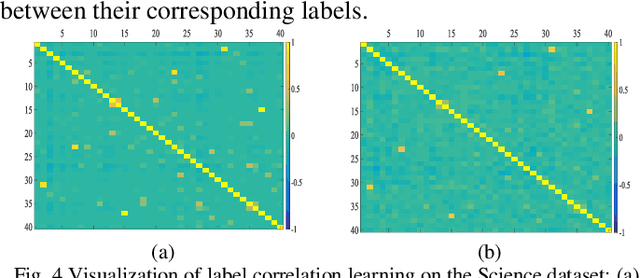
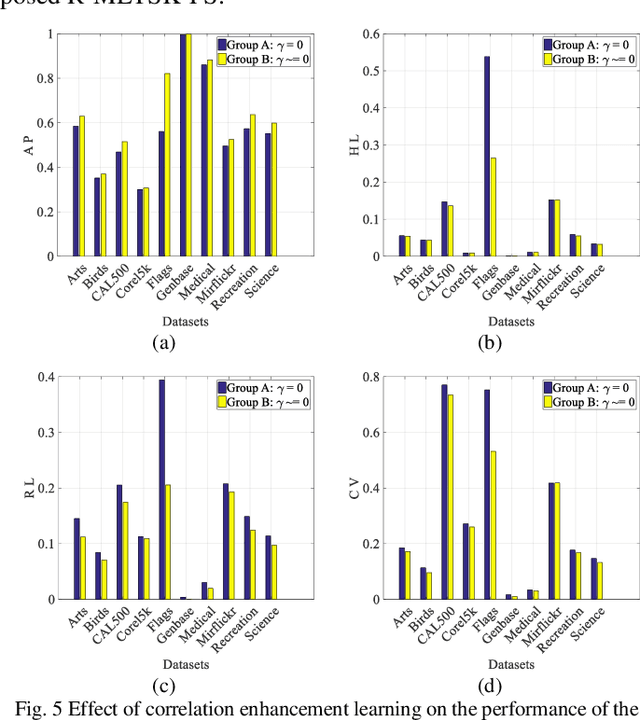
Model transparency, label correlation learning and the robust-ness to label noise are crucial for multilabel learning. However, few existing methods study these three characteristics simultaneously. To address this challenge, we propose the robust multilabel Takagi-Sugeno-Kang fuzzy system (R-MLTSK-FS) with three mechanisms. First, we design a soft label learning mechanism to reduce the effect of label noise by explicitly measuring the interactions between labels, which is also the basis of the other two mechanisms. Second, the rule-based TSK FS is used as the base model to efficiently model the inference relationship be-tween features and soft labels in a more transparent way than many existing multilabel models. Third, to further improve the performance of multilabel learning, we build a correlation enhancement learning mechanism based on the soft label space and the fuzzy feature space. Extensive experiments are conducted to demonstrate the superiority of the proposed method.
Graph Fuzzy System: Concepts, Models and Algorithms
Oct 30, 2022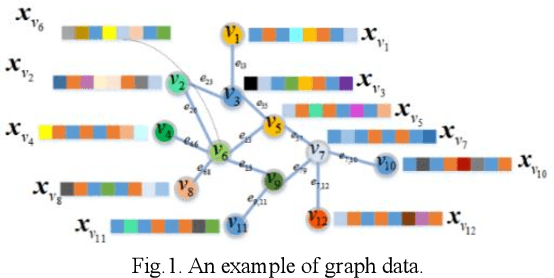
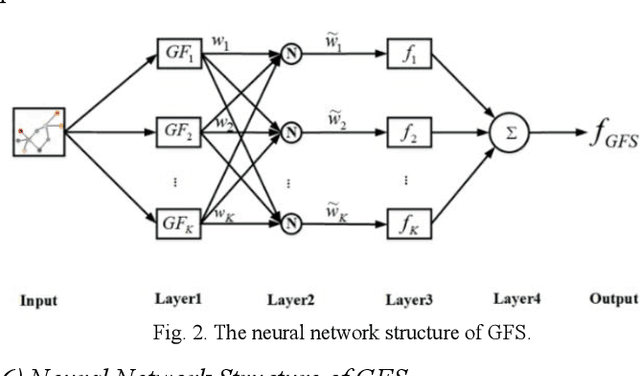

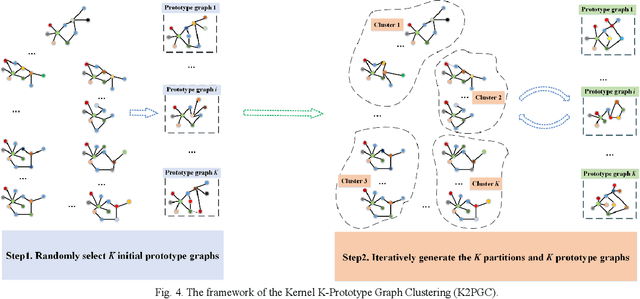
Fuzzy systems (FSs) have enjoyed wide applications in various fields, including pattern recognition, intelligent control, data mining and bioinformatics, which is attributed to the strong interpretation and learning ability. In traditional application scenarios, FSs are mainly applied to model Euclidean space data and cannot be used to handle graph data of non-Euclidean structure in nature, such as social networks and traffic route maps. Therefore, development of FS modeling method that is suitable for graph data and can retain the advantages of traditional FSs is an important research. To meet this challenge, a new type of FS for graph data modeling called Graph Fuzzy System (GFS) is proposed in this paper, where the concepts, modeling framework and construction algorithms are systematically developed. First, GFS related concepts, including graph fuzzy rule base, graph fuzzy sets and graph consequent processing unit (GCPU), are defined. A GFS modeling framework is then constructed and the antecedents and consequents of the GFS are presented and analyzed. Finally, a learning framework of GFS is proposed, in which a kernel K-prototype graph clustering (K2PGC) is proposed to develop the construction algorithm for the GFS antecedent generation, and then based on graph neural network (GNNs), consequent parameters learning algorithm is proposed for GFS. Specifically, three different versions of the GFS implementation algorithm are developed for comprehensive evaluations with experiments on various benchmark graph classification datasets. The results demonstrate that the proposed GFS inherits the advantages of both existing mainstream GNNs methods and conventional FSs methods while achieving better performance than the counterparts.
Dual Representation Learning for One-Step Clustering of Multi-View Data
Aug 30, 2022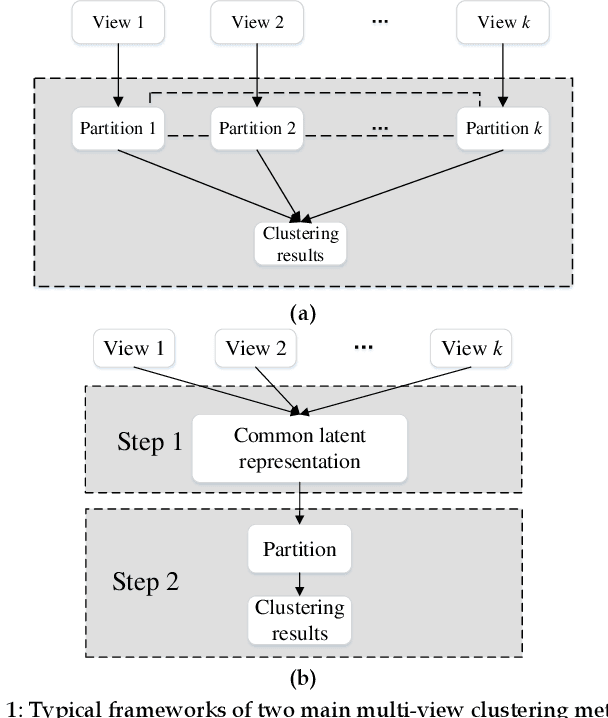

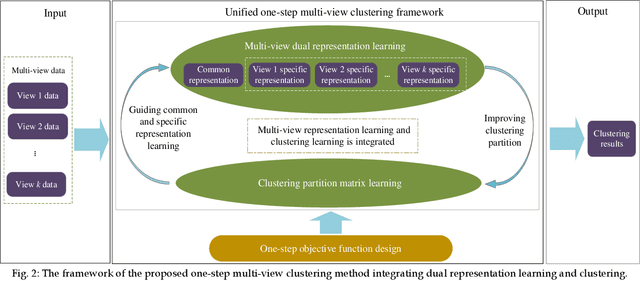

Multi-view data are commonly encountered in data mining applications. Effective extraction of information from multi-view data requires specific design of clustering methods to cater for data with multiple views, which is non-trivial and challenging. In this paper, we propose a novel one-step multi-view clustering method by exploiting the dual representation of both the common and specific information of different views. The motivation originates from the rationale that multi-view data contain not only the consistent knowledge between views but also the unique knowledge of each view. Meanwhile, to make the representation learning more specific to the clustering task, a one-step learning framework is proposed to integrate representation learning and clustering partition as a whole. With this framework, the representation learning and clustering partition mutually benefit each other, which effectively improve the clustering performance. Results from extensive experiments conducted on benchmark multi-view datasets clearly demonstrate the superiority of the proposed method.