 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxBERT: An Interpretable Chinese Spelling Correction Method Driven by Associative Knowledge Network
Mar 04, 2025Deep learning has shown promising performance on various machine learning tasks. Nevertheless, the uninterpretability of deep learning models severely restricts the usage domains that require feature explanations, such as text correction. Therefore, a novel interpretable deep learning model (named AxBERT) is proposed for Chinese spelling correction by aligning with an associative knowledge network (AKN). Wherein AKN is constructed based on the co-occurrence relations among Chinese characters, which denotes the interpretable statistic logic contrasted with uninterpretable BERT logic. And a translator matrix between BERT and AKN is introduced for the alignment and regulation of the attention component in BERT. In addition, a weight regulator is designed to adjust the attention distributions in BERT to appropriately model the sentence semantics. Experimental results on SIGHAN datasets demonstrate that AxBERT can achieve extraordinary performance, especially upon model precision compared to baselines. Our interpretable analysis, together with qualitative reasoning, can effectively illustrate the interpretability of AxBERT.
UA-PDFL: A Personalized Approach for Decentralized Federated Learning
Dec 16, 2024



Federated learning (FL) is a privacy preserving machine learning paradigm designed to collaboratively learn a global model without data leakage. Specifically, in a typical FL system, the central server solely functions as an coordinator to iteratively aggregate the collected local models trained by each client, potentially introducing single-point transmission bottleneck and security threats. To mitigate this issue, decentralized federated learning (DFL) has been proposed, where all participating clients engage in peer-to-peer communication without a central server. Nonetheless, DFL still suffers from training degradation as FL does due to the non-independent and identically distributed (non-IID) nature of client data. And incorporating personalization layers into DFL may be the most effective solutions to alleviate the side effects caused by non-IID data. Therefore, in this paper, we propose a novel unit representation aided personalized decentralized federated learning framework, named UA-PDFL, to deal with the non-IID challenge in DFL. By adaptively adjusting the level of personalization layers through the guidance of the unit representation, UA-PDFL is able to address the varying degrees of data skew. Based on this scheme, client-wise dropout and layer-wise personalization are proposed to further enhance the learning performance of DFL. Extensive experiments empirically prove the effectiveness of our proposed method.
Privacy Attack in Federated Learning is Not Easy: An Experimental Study
Sep 28, 2024



Federated learning (FL) is an emerging distributed machine learning paradigm proposed for privacy preservation. Unlike traditional centralized learning approaches, FL enables multiple users to collaboratively train a shared global model without disclosing their own data, thereby significantly reducing the potential risk of privacy leakage. However, recent studies have indicated that FL cannot entirely guarantee privacy protection, and attackers may still be able to extract users' private data through the communicated model gradients. Although numerous privacy attack FL algorithms have been developed, most are designed to reconstruct private data from a single step of calculated gradients. It remains uncertain whether these methods are effective in realistic federated environments or if they have other limitations. In this paper, we aim to help researchers better understand and evaluate the effectiveness of privacy attacks on FL. We analyze and discuss recent research papers on this topic and conduct experiments in a real FL environment to compare the performance of various attack methods. Our experimental results reveal that none of the existing state-of-the-art privacy attack algorithms can effectively breach private client data in realistic FL settings, even in the absence of defense strategies. This suggests that privacy attacks in FL are more challenging than initially anticipated.
Motion Mapping Cognition: A Nondecomposable Primary Process in Human Vision
Feb 02, 2024


Human intelligence seems so mysterious that we have not successfully understood its foundation until now. Here, I want to present a basic cognitive process, motion mapping cognition (MMC), which should be a nondecomposable primary function in human vision. Wherein, I point out that, MMC process can be used to explain most of human visual functions in fundamental, but can not be effectively modelled by traditional visual processing ways including image segmentation, object recognition, object tracking etc. Furthermore, I state that MMC may be looked as an extension of Chen's theory of topological perception on human vision, and seems to be unsolvable using existing intelligent algorithm skills. Finally, along with the requirements of MMC problem, an interesting computational model, quantized topological matching principle can be derived by developing the idea of optimal transport theory. Above results may give us huge inspiration to develop more robust and interpretable machine vision models.
Federated Two Stage Decoupling With Adaptive Personalization Layers
Aug 30, 2023



Federated learning has gained significant attention due to its groundbreaking ability to enable distributed learning while maintaining privacy constraints. However, as a consequence of data heterogeneity among decentralized devices, it inherently experiences significant learning degradation and slow convergence speed. Therefore, it is natural to employ the concept of clustering homogeneous clients into the same group, allowing only the model weights within each group to be aggregated. While most existing clustered federated learning methods employ either model gradients or inference outputs as metrics for client partitioning, with the goal of grouping similar devices together, may still have heterogeneity within each cluster. Moreover, there is a scarcity of research exploring the underlying reasons for determining the appropriate timing for clustering, resulting in the common practice of assigning each client to its own individual cluster, particularly in the context of highly non independent and identically distributed (Non-IID) data. In this paper, we introduce a two-stage decoupling federated learning algorithm with adaptive personalization layers named FedTSDP, where client clustering is performed twice according to inference outputs and model weights, respectively. Hopkins amended sampling is adopted to determine the appropriate timing for clustering and the sampling weight of public unlabeled data. In addition, a simple yet effective approach is developed to adaptively adjust the personalization layers based on varying degrees of data skew. Experimental results show that our proposed method has reliable performance on both IID and non-IID scenarios.
An Adversarial Multi-Task Learning Method for Chinese Text Correction with Semantic Detection
Jun 28, 2023Text correction, especially the semantic correction of more widely used scenes, is strongly required to improve, for the fluency and writing efficiency of the text. An adversarial multi-task learning method is proposed to enhance the modeling and detection ability of character polysemy in Chinese sentence context. Wherein, two models, the masked language model and scoring language model, are introduced as a pair of not only coupled but also adversarial learning tasks. Moreover, the Monte Carlo tree search strategy and a policy network are introduced to accomplish the efficient Chinese text correction task with semantic detection. The experiments are executed on three datasets and five comparable methods, and the experimental results show that our method can obtain good performance in Chinese text correction task for better semantic rationality.
Constructing Word-Context-Coupled Space Aligned with Associative Knowledge Relations for Interpretable Language Modeling
May 19, 2023



As the foundation of current natural language processing methods, pre-trained language model has achieved excellent performance. However, the black-box structure of the deep neural network in pre-trained language models seriously limits the interpretability of the language modeling process. After revisiting the coupled requirement of deep neural representation and semantics logic of language modeling, a Word-Context-Coupled Space (W2CSpace) is proposed by introducing the alignment processing between uninterpretable neural representation and interpretable statistical logic. Moreover, a clustering process is also designed to connect the word- and context-level semantics. Specifically, an associative knowledge network (AKN), considered interpretable statistical logic, is introduced in the alignment process for word-level semantics. Furthermore, the context-relative distance is employed as the semantic feature for the downstream classifier, which is greatly different from the current uninterpretable semantic representations of pre-trained models. Our experiments for performance evaluation and interpretable analysis are executed on several types of datasets, including SIGHAN, Weibo, and ChnSenti. Wherein a novel evaluation strategy for the interpretability of machine learning models is first proposed. According to the experimental results, our language model can achieve better performance and highly credible interpretable ability compared to related state-of-the-art methods.
Graph Fuzzy System: Concepts, Models and Algorithms
Oct 30, 2022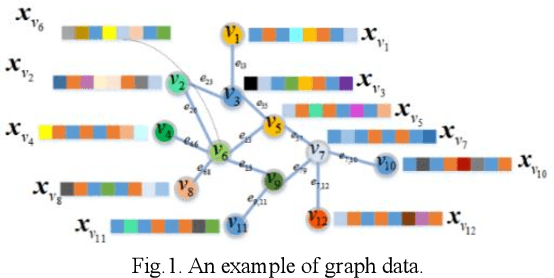
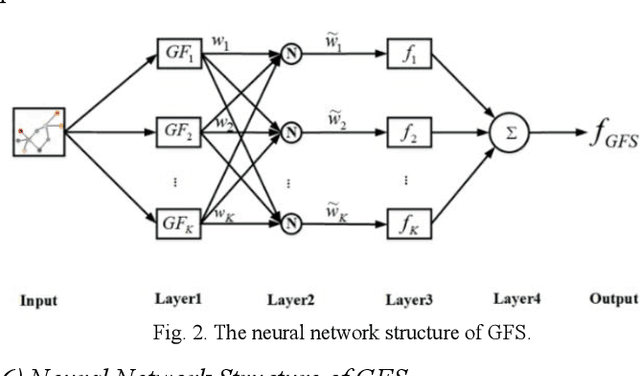

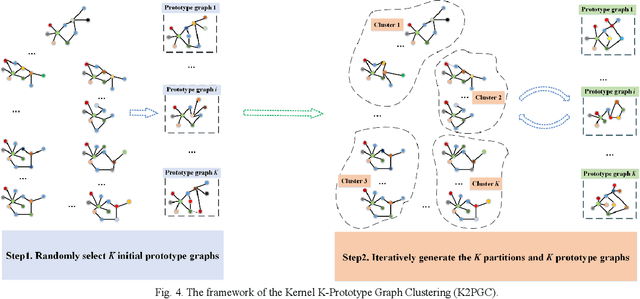
Fuzzy systems (FSs) have enjoyed wide applications in various fields, including pattern recognition, intelligent control, data mining and bioinformatics, which is attributed to the strong interpretation and learning ability. In traditional application scenarios, FSs are mainly applied to model Euclidean space data and cannot be used to handle graph data of non-Euclidean structure in nature, such as social networks and traffic route maps. Therefore, development of FS modeling method that is suitable for graph data and can retain the advantages of traditional FSs is an important research. To meet this challenge, a new type of FS for graph data modeling called Graph Fuzzy System (GFS) is proposed in this paper, where the concepts, modeling framework and construction algorithms are systematically developed. First, GFS related concepts, including graph fuzzy rule base, graph fuzzy sets and graph consequent processing unit (GCPU), are defined. A GFS modeling framework is then constructed and the antecedents and consequents of the GFS are presented and analyzed. Finally, a learning framework of GFS is proposed, in which a kernel K-prototype graph clustering (K2PGC) is proposed to develop the construction algorithm for the GFS antecedent generation, and then based on graph neural network (GNNs), consequent parameters learning algorithm is proposed for GFS. Specifically, three different versions of the GFS implementation algorithm are developed for comprehensive evaluations with experiments on various benchmark graph classification datasets. The results demonstrate that the proposed GFS inherits the advantages of both existing mainstream GNNs methods and conventional FSs methods while achieving better performance than the counterparts.