 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxBERT: An Interpretable Chinese Spelling Correction Method Driven by Associative Knowledge Network
Mar 04, 2025Deep learning has shown promising performance on various machine learning tasks. Nevertheless, the uninterpretability of deep learning models severely restricts the usage domains that require feature explanations, such as text correction. Therefore, a novel interpretable deep learning model (named AxBERT) is proposed for Chinese spelling correction by aligning with an associative knowledge network (AKN). Wherein AKN is constructed based on the co-occurrence relations among Chinese characters, which denotes the interpretable statistic logic contrasted with uninterpretable BERT logic. And a translator matrix between BERT and AKN is introduced for the alignment and regulation of the attention component in BERT. In addition, a weight regulator is designed to adjust the attention distributions in BERT to appropriately model the sentence semantics. Experimental results on SIGHAN datasets demonstrate that AxBERT can achieve extraordinary performance, especially upon model precision compared to baselines. Our interpretable analysis, together with qualitative reasoning, can effectively illustrate the interpretability of AxBERT.
UA-PDFL: A Personalized Approach for Decentralized Federated Learning
Dec 16, 2024



Federated learning (FL) is a privacy preserving machine learning paradigm designed to collaboratively learn a global model without data leakage. Specifically, in a typical FL system, the central server solely functions as an coordinator to iteratively aggregate the collected local models trained by each client, potentially introducing single-point transmission bottleneck and security threats. To mitigate this issue, decentralized federated learning (DFL) has been proposed, where all participating clients engage in peer-to-peer communication without a central server. Nonetheless, DFL still suffers from training degradation as FL does due to the non-independent and identically distributed (non-IID) nature of client data. And incorporating personalization layers into DFL may be the most effective solutions to alleviate the side effects caused by non-IID data. Therefore, in this paper, we propose a novel unit representation aided personalized decentralized federated learning framework, named UA-PDFL, to deal with the non-IID challenge in DFL. By adaptively adjusting the level of personalization layers through the guidance of the unit representation, UA-PDFL is able to address the varying degrees of data skew. Based on this scheme, client-wise dropout and layer-wise personalization are proposed to further enhance the learning performance of DFL. Extensive experiments empirically prove the effectiveness of our proposed method.
Privacy Attack in Federated Learning is Not Easy: An Experimental Study
Sep 28, 2024



Federated learning (FL) is an emerging distributed machine learning paradigm proposed for privacy preservation. Unlike traditional centralized learning approaches, FL enables multiple users to collaboratively train a shared global model without disclosing their own data, thereby significantly reducing the potential risk of privacy leakage. However, recent studies have indicated that FL cannot entirely guarantee privacy protection, and attackers may still be able to extract users' private data through the communicated model gradients. Although numerous privacy attack FL algorithms have been developed, most are designed to reconstruct private data from a single step of calculated gradients. It remains uncertain whether these methods are effective in realistic federated environments or if they have other limitations. In this paper, we aim to help researchers better understand and evaluate the effectiveness of privacy attacks on FL. We analyze and discuss recent research papers on this topic and conduct experiments in a real FL environment to compare the performance of various attack methods. Our experimental results reveal that none of the existing state-of-the-art privacy attack algorithms can effectively breach private client data in realistic FL settings, even in the absence of defense strategies. This suggests that privacy attacks in FL are more challenging than initially anticipated.
Federated Two Stage Decoupling With Adaptive Personalization Layers
Aug 30, 2023



Federated learning has gained significant attention due to its groundbreaking ability to enable distributed learning while maintaining privacy constraints. However, as a consequence of data heterogeneity among decentralized devices, it inherently experiences significant learning degradation and slow convergence speed. Therefore, it is natural to employ the concept of clustering homogeneous clients into the same group, allowing only the model weights within each group to be aggregated. While most existing clustered federated learning methods employ either model gradients or inference outputs as metrics for client partitioning, with the goal of grouping similar devices together, may still have heterogeneity within each cluster. Moreover, there is a scarcity of research exploring the underlying reasons for determining the appropriate timing for clustering, resulting in the common practice of assigning each client to its own individual cluster, particularly in the context of highly non independent and identically distributed (Non-IID) data. In this paper, we introduce a two-stage decoupling federated learning algorithm with adaptive personalization layers named FedTSDP, where client clustering is performed twice according to inference outputs and model weights, respectively. Hopkins amended sampling is adopted to determine the appropriate timing for clustering and the sampling weight of public unlabeled data. In addition, a simple yet effective approach is developed to adaptively adjust the personalization layers based on varying degrees of data skew. Experimental results show that our proposed method has reliable performance on both IID and non-IID scenarios.
PIVODL: Privacy-preserving vertical federated learning over distributed labels
Aug 25, 2021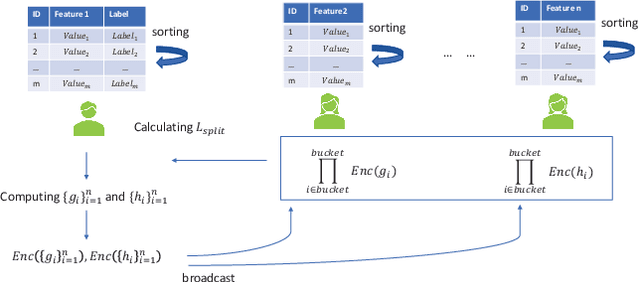
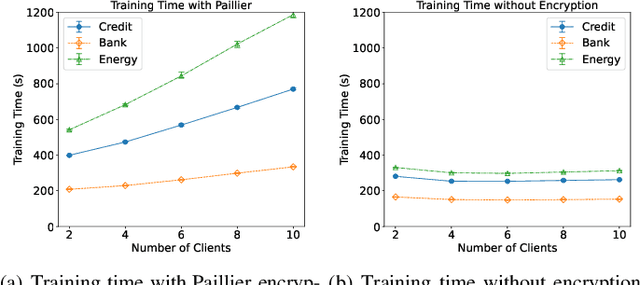
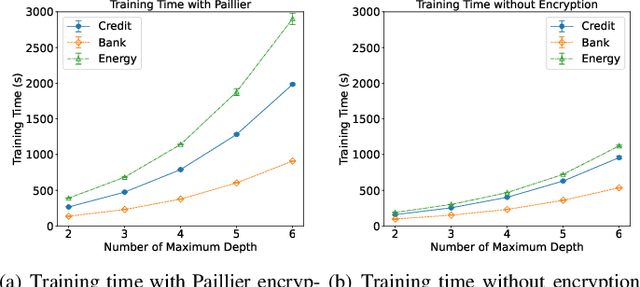
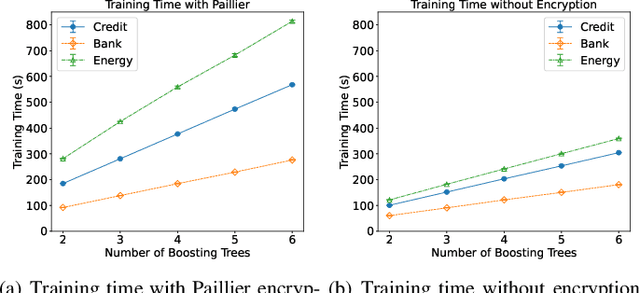
Federated learning (FL) is an emerging privacy preserving machine learning protocol that allows multiple devices to collaboratively train a shared global model without revealing their private local data. Non-parametric models like gradient boosting decision trees (GBDT) have been commonly used in FL for vertically partitioned data. However, all these studies assume that all the data labels are stored on only one client, which may be unrealistic for real-world applications. Therefore, in this work, we propose a secure vertical FL framework, named PIVODL, to train GBDT with data labels distributed on multiple devices. Both homomorphic encryption and differential privacy are adopted to prevent label information from being leaked through transmitted gradients and leaf values. Our experimental results show that both information leakage and model performance degradation of the proposed PIVODL are negligible.
Federated Learning on Non-IID Data: A Survey
Jun 12, 2021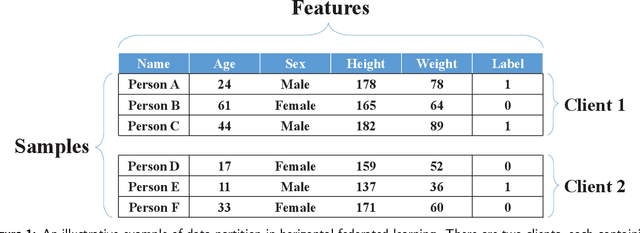
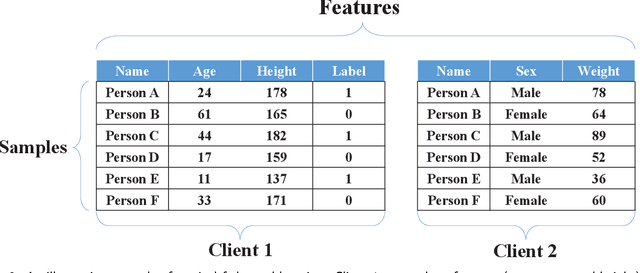

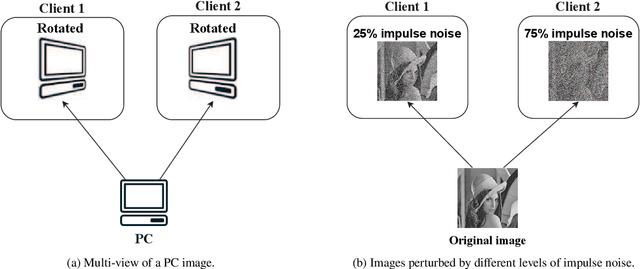
Federated learning is an emerging distributed machine learning framework for privacy preservation. However, models trained in federated learning usually have worse performance than those trained in the standard centralized learning mode, especially when the training data are not independent and identically distributed (Non-IID) on the local devices. In this survey, we pro-vide a detailed analysis of the influence of Non-IID data on both parametric and non-parametric machine learning models in both horizontal and vertical federated learning. In addition, cur-rent research work on handling challenges of Non-IID data in federated learning are reviewed, and both advantages and disadvantages of these approaches are discussed. Finally, we suggest several future research directions before concluding the paper.
Real-time Federated Evolutionary Neural Architecture Search
Mar 04, 2020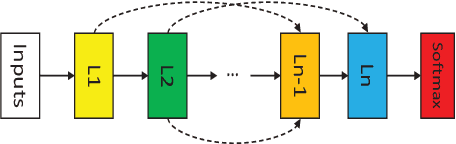
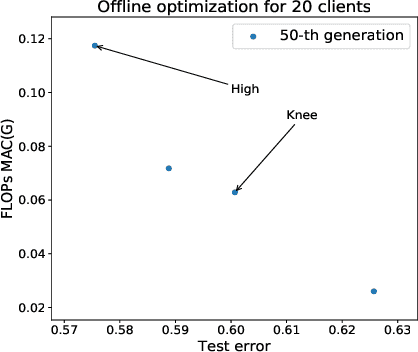
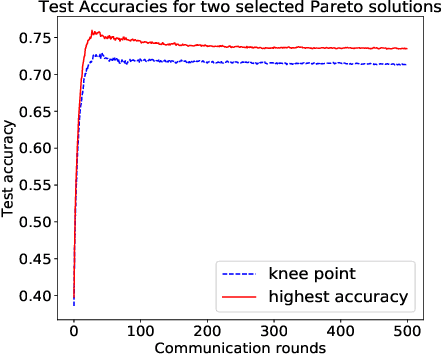
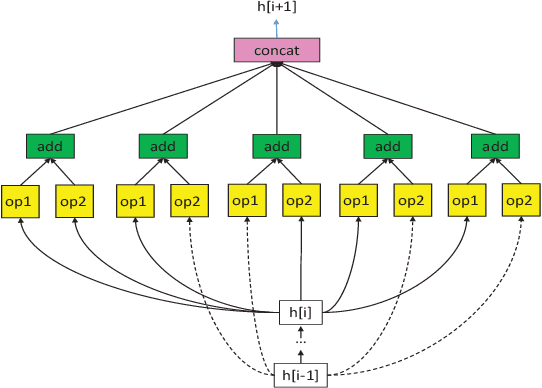
Federated learning is a distributed machine learning approach to privacy preservation and two major technical challenges prevent a wider application of federated learning. One is that federated learning raises high demands on communication, since a large number of model parameters must be transmitted between the server and the clients. The other challenge is that training large machine learning models such as deep neural networks in federated learning requires a large amount of computational resources, which may be unrealistic for edge devices such as mobile phones. The problem becomes worse when deep neural architecture search is to be carried out in federated learning. To address the above challenges, we propose an evolutionary approach to real-time federated neural architecture search that not only optimize the model performance but also reduces the local payload. During the search, a double-sampling technique is introduced, in which for each individual, a randomly sampled sub-model of a master model is transmitted to a number of randomly sampled clients for training without reinitialization. This way, we effectively reduce computational and communication costs required for evolutionary optimization and avoid big performance fluctuations of the local models, making the proposed framework well suited for real-time federated neural architecture search.
Multi-objective Evolutionary Federated Learning
Dec 18, 2018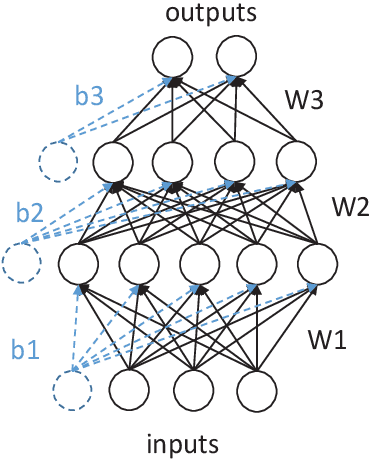
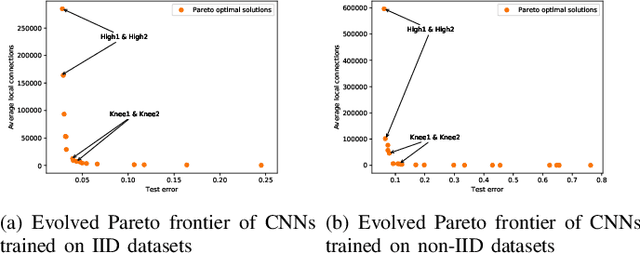


Federated learning is an emerging technique used to prevent the leakage of private information. Unlike centralized learning that needs to collect data from users and store them collectively on a cloud server, federated learning makes it possible to learn a global model while the data are distributed on the users' devices. However, compared with the traditional centralized approach, the federated setting consumes considerable communication resources of the clients, which is indispensable for updating global models and prevents this technique from being widely used. In this paper, we aim to optimize the structure of the neural network models in federated learning using a multi-objective evolutionary algorithm to simultaneously minimize the communication costs and the global model test errors. A scalable method for encoding network connectivity is adapted to federated learning to enhance the efficiency in evolving deep neural networks. Experimental results on both multilayer perceptrons and convolutional neural networks indicate that the proposed optimization method is able to find optimized neural network models that can not only significantly reduce communication costs but also improve the learning performance of federated learning compared with the standard fully connected neural networks.