 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning on Non-IID Data: A Survey
Paper and Code
Jun 12, 2021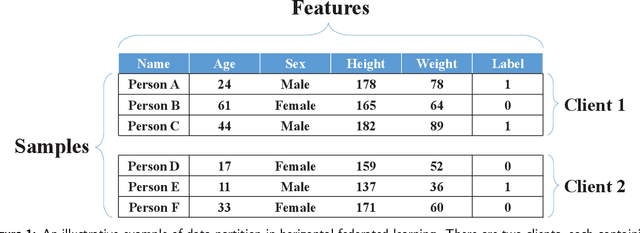
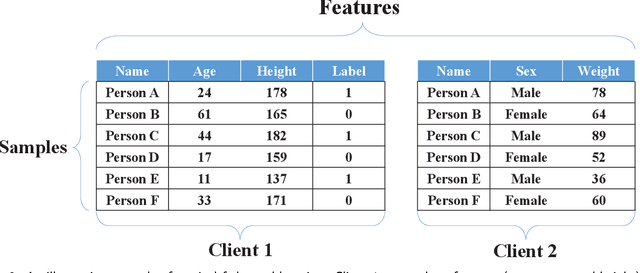

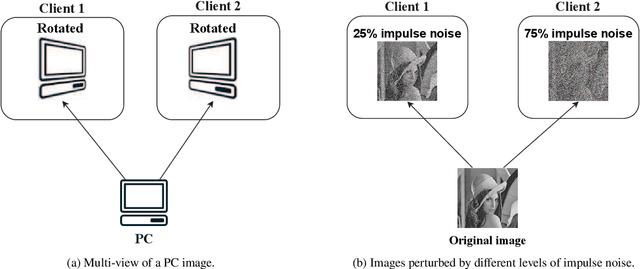
Federated learning is an emerging distributed machine learning framework for privacy preservation. However, models trained in federated learning usually have worse performance than those trained in the standard centralized learning mode, especially when the training data are not independent and identically distributed (Non-IID) on the local devices. In this survey, we pro-vide a detailed analysis of the influence of Non-IID data on both parametric and non-parametric machine learning models in both horizontal and vertical federated learning. In addition, cur-rent research work on handling challenges of Non-IID data in federated learning are reviewed, and both advantages and disadvantages of these approaches are discussed. Finally, we suggest several future research directions before concluding the paper.