 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELAS: Efficient Pre-Training of Low-Rank Large Language Models via 2:4 Activation Sparsity
May 05, 2026Large Language Models (LLMs) have achieved remarkable capabilities, but their immense computational demands during training remain a critical bottleneck for widespread adoption. Low-rank training has received attention in recent years due to its ability to significantly reduce training memory usage. Meanwhile, applying 2:4 structured sparsity to weights and activations to leverage NVIDIA GPU support for 2:4 structured sparse format has become a promising direction. However, existing low-rank methods often leave activation matrices in full-rank, which dominates memory consumption and limits throughput during large-batch training. Furthermore, directly applying sparsity to weights often leads to non-negligible performance degradation. To achieve efficient pre-training of LLMs, this paper proposes ELAS: Efficient pre-training of Low-rank LLMs via 2:4 Activation Sparsity, a novel framework for low-rank models via 2:4 activation sparsity. ELAS applies squared ReLU activation functions to the feed-forward networks in low-rank models and implements 2:4 structured sparsity on the activations after the squared ReLU operation. We evaluated ELAS through pre-training experiments on LLaMA models ranging from 60M to 1B parameters. The results demonstrate that ELAS maintains performance with minimal degradation after applying 2:4 activation sparsity, while achieving training and inference acceleration. Moreover, ELAS reduces activation memory overhead, particularly with large batch sizes. Code is available at ELAS Repo.
LoopAnimate: Loopable Salient Object Animation
Apr 14, 2024Research on diffusion model-based video generation has advanced rapidly. However, limitations in object fidelity and generation length hinder its practical applications. Additionally, specific domains like animated wallpapers require seamless looping, where the first and last frames of the video match seamlessly. To address these challenges, this paper proposes LoopAnimate, a novel method for generating videos with consistent start and end frames. To enhance object fidelity, we introduce a framework that decouples multi-level image appearance and textual semantic information. Building upon an image-to-image diffusion model, our approach incorporates both pixel-level and feature-level information from the input image, injecting image appearance and textual semantic embeddings at different positions of the diffusion model. Existing UNet-based video generation models require to input the entire videos during training to encode temporal and positional information at once. However, due to limitations in GPU memory, the number of frames is typically restricted to 16. To address this, this paper proposes a three-stage training strategy with progressively increasing frame numbers and reducing fine-tuning modules. Additionally, we introduce the Temporal E nhanced Motion Module(TEMM) to extend the capacity for encoding temporal and positional information up to 36 frames. The proposed LoopAnimate, which for the first time extends the single-pass generation length of UNet-based video generation models to 35 frames while maintaining high-quality video generation. Experiments demonstrate that LoopAnimate achieves state-of-the-art performance in both objective metrics, such as fidelity and temporal consistency, and subjective evaluation results.
u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Nov 09, 2023
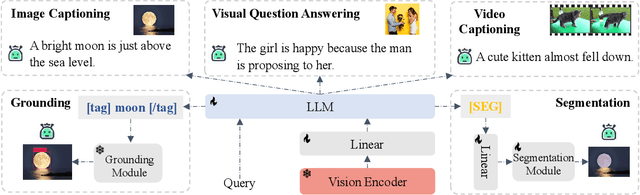
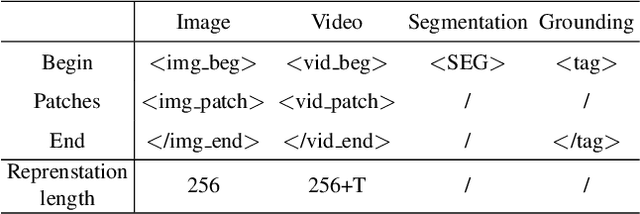

Recent advances such as LLaVA and Mini-GPT4 have successfully integrated visual information into LLMs, yielding inspiring outcomes and giving rise to a new generation of multi-modal LLMs, or MLLMs. Nevertheless, these methods struggle with hallucinations and the mutual interference between tasks. To tackle these problems, we propose an efficient and accurate approach to adapt to downstream tasks by utilizing LLM as a bridge to connect multiple expert models, namely u-LLaVA. Firstly, we incorporate the modality alignment module and multi-task modules into LLM. Then, we reorganize or rebuild multi-type public datasets to enable efficient modality alignment and instruction following. Finally, task-specific information is extracted from the trained LLM and provided to different modules for solving downstream tasks. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also release our model, the generated data, and the code base publicly available.
CLIP Brings Better Features to Visual Aesthetics Learners
Jul 28, 2023The success of pre-training approaches on a variety of downstream tasks has revitalized the field of computer vision. Image aesthetics assessment (IAA) is one of the ideal application scenarios for such methods due to subjective and expensive labeling procedure. In this work, an unified and flexible two-phase \textbf{C}LIP-based \textbf{S}emi-supervised \textbf{K}nowledge \textbf{D}istillation paradigm is proposed, namely \textbf{\textit{CSKD}}. Specifically, we first integrate and leverage a multi-source unlabeled dataset to align rich features between a given visual encoder and an off-the-shelf CLIP image encoder via feature alignment loss. Notably, the given visual encoder is not limited by size or structure and, once well-trained, it can seamlessly serve as a better visual aesthetic learner for both student and teacher. In the second phase, the unlabeled data is also utilized in semi-supervised IAA learning to further boost student model performance when applied in latency-sensitive production scenarios. By analyzing the attention distance and entropy before and after feature alignment, we notice an alleviation of feature collapse issue, which in turn showcase the necessity of feature alignment instead of training directly based on CLIP image encoder. Extensive experiments indicate the superiority of CSKD, which achieves state-of-the-art performance on multiple widely used IAA benchmarks.
A Federated Data-Driven Evolutionary Algorithm for Expensive Multi/Many-objective Optimization
Jun 22, 2021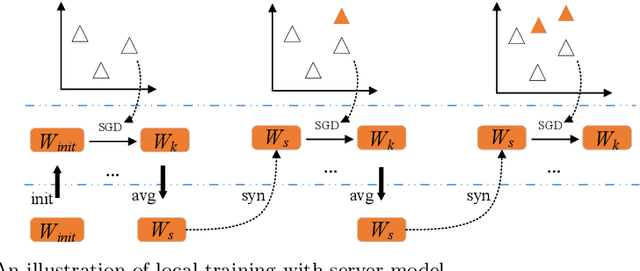
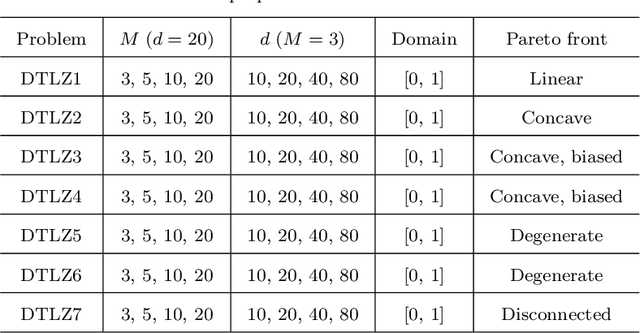
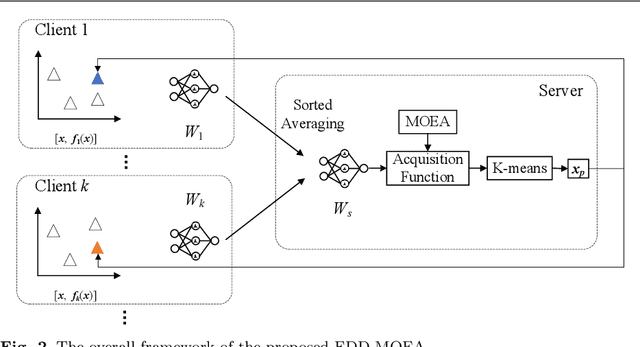

Data-driven optimization has found many successful applications in the real world and received increased attention in the field of evolutionary optimization. Most existing algorithms assume that the data used for optimization is always available on a central server for construction of surrogates. This assumption, however, may fail to hold when the data must be collected in a distributed way and is subject to privacy restrictions. This paper aims to propose a federated data-driven evolutionary multi-/many-objective optimization algorithm. To this end, we leverage federated learning for surrogate construction so that multiple clients collaboratively train a radial-basis-function-network as the global surrogate. Then a new federated acquisition function is proposed for the central server to approximate the objective values using the global surrogate and estimate the uncertainty level of the approximated objective values based on the local models. The performance of the proposed algorithm is verified on a series of multi/many-objective benchmark problems by comparing it with two state-of-the-art surrogate-assisted multi-objective evolutionary algorithms.
Federated Learning on Non-IID Data: A Survey
Jun 12, 2021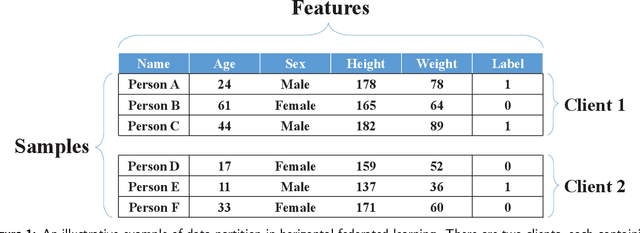
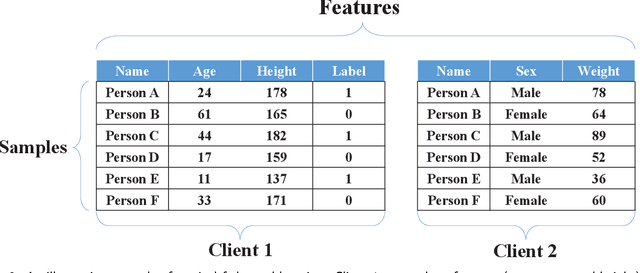

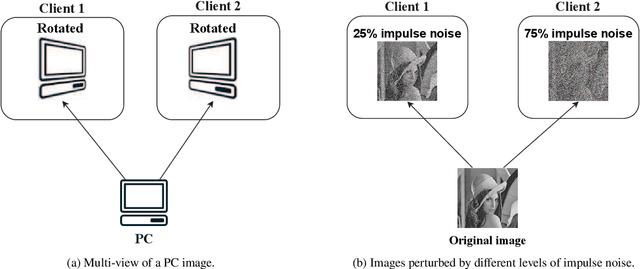
Federated learning is an emerging distributed machine learning framework for privacy preservation. However, models trained in federated learning usually have worse performance than those trained in the standard centralized learning mode, especially when the training data are not independent and identically distributed (Non-IID) on the local devices. In this survey, we pro-vide a detailed analysis of the influence of Non-IID data on both parametric and non-parametric machine learning models in both horizontal and vertical federated learning. In addition, cur-rent research work on handling challenges of Non-IID data in federated learning are reviewed, and both advantages and disadvantages of these approaches are discussed. Finally, we suggest several future research directions before concluding the paper.
A Federated Data-Driven Evolutionary Algorithm
Feb 16, 2021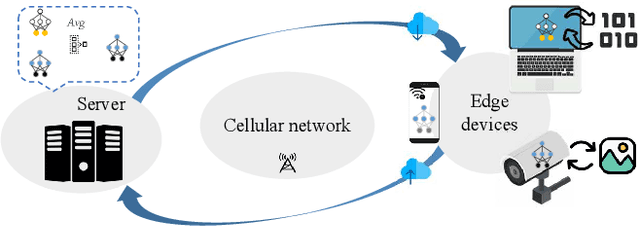
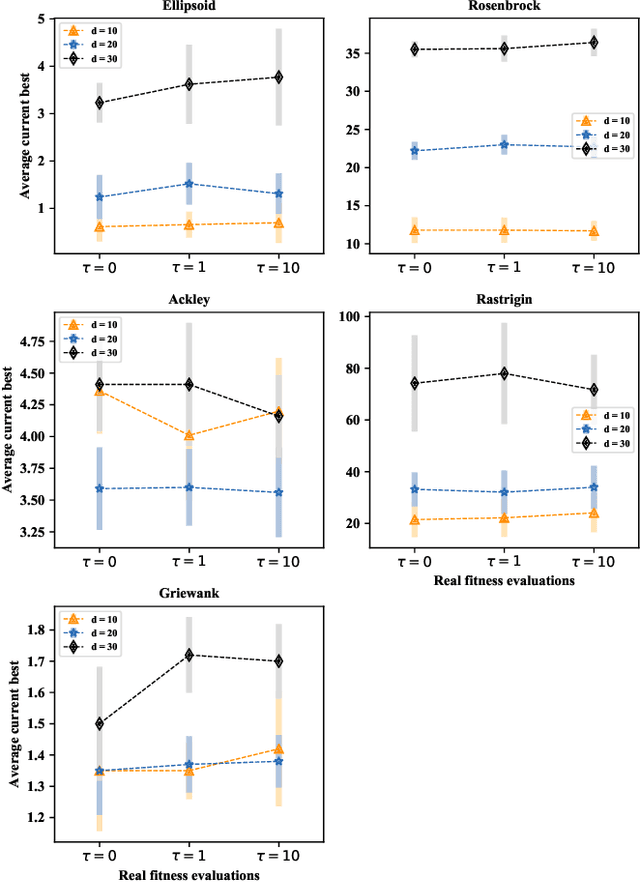
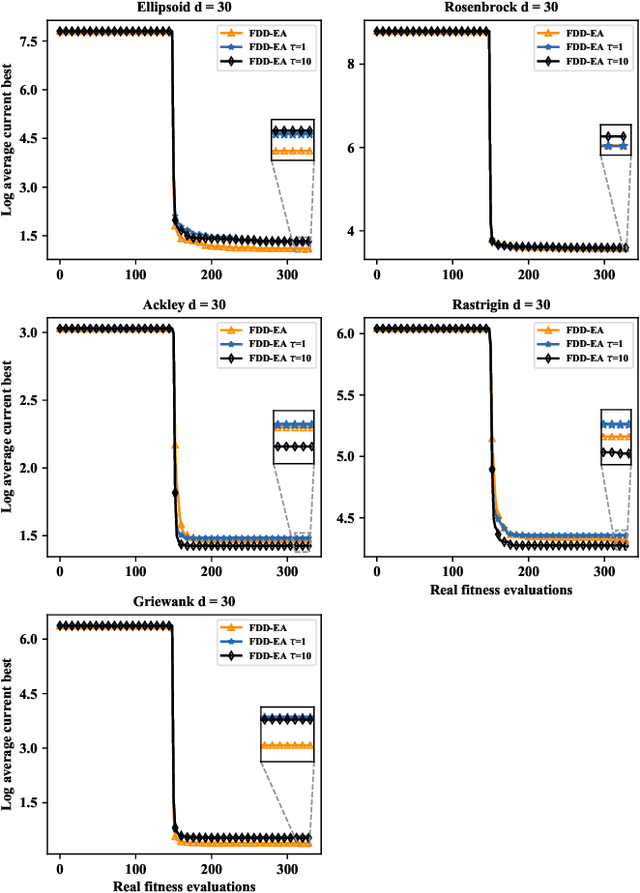
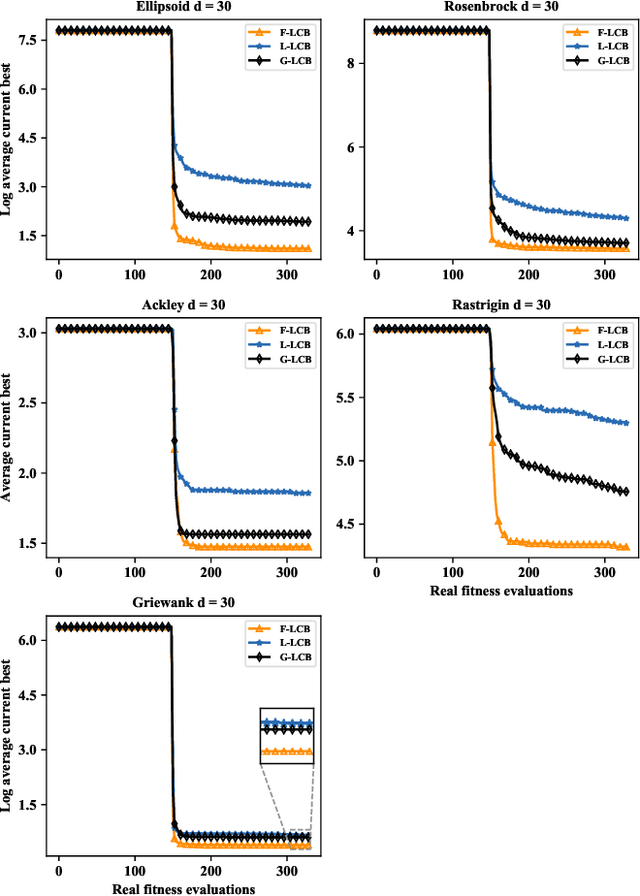
Data-driven evolutionary optimization has witnessed great success in solving complex real-world optimization problems. However, existing data-driven optimization algorithms require that all data are centrally stored, which is not always practical and may be vulnerable to privacy leakage and security threats if the data must be collected from different devices. To address the above issue, this paper proposes a federated data-driven evolutionary optimization framework that is able to perform data driven optimization when the data is distributed on multiple devices. On the basis of federated learning, a sorted model aggregation method is developed for aggregating local surrogates based on radial-basis-function networks. In addition, a federated surrogate management strategy is suggested by designing an acquisition function that takes into account the information of both the global and local surrogate models. Empirical studies on a set of widely used benchmark functions in the presence of various data distributions demonstrate the effectiveness of the proposed framework.
Ternary Compression for Communication-Efficient Federated Learning
Mar 07, 2020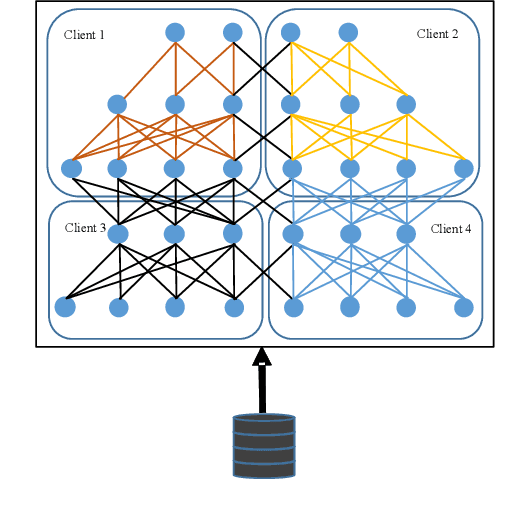
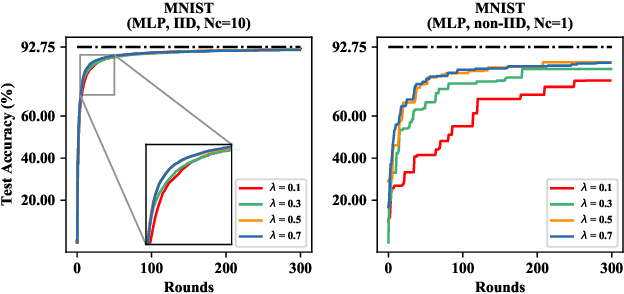
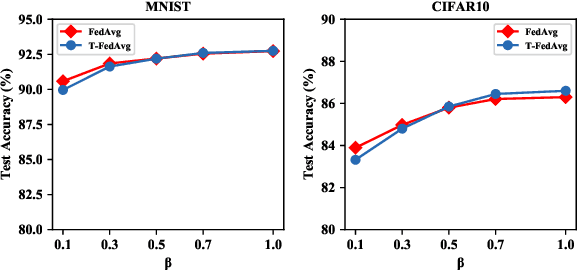
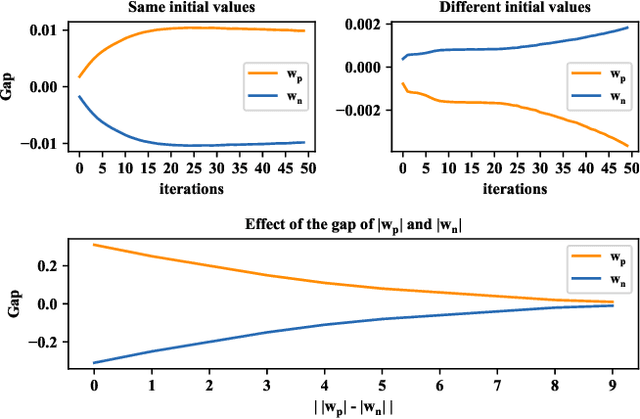
Learning over massive data stored in different locations is essential in many real-world applications. However, sharing data is full of challenges due to the increasing demands of privacy and security with the growing use of smart mobile devices and IoT devices. Federated learning provides a potential solution to privacy-preserving and secure machine learning, by means of jointly training a global model without uploading data distributed on multiple devices to a central server. However, most existing work on federated learning adopts machine learning models with full-precision weights, and almost all these models contain a large number of redundant parameters that do not need to be transmitted to the server, consuming an excessive amount of communication costs. To address this issue, we propose a federated trained ternary quantization (FTTQ) algorithm, which optimizes the quantized networks on the clients through a self-learning quantization factor. A convergence proof of the quantization factor and the unbiasedness of FTTQ is given. In addition, we propose a ternary federated averaging protocol (T-FedAvg) to reduce the upstream and downstream communication of federated learning systems. Empirical experiments are conducted to train widely used deep learning models on publicly available datasets, and our results demonstrate the effectiveness of FTTQ and T-FedAvg compared with the canonical federated learning algorithms in reducing communication costs and maintaining the learning performance.