 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiased Novel Category Discovering and Localization
Feb 29, 2024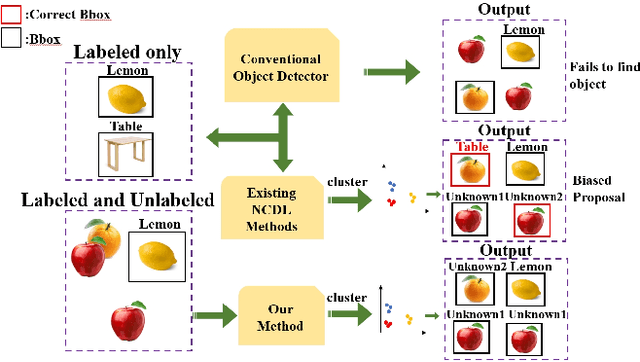

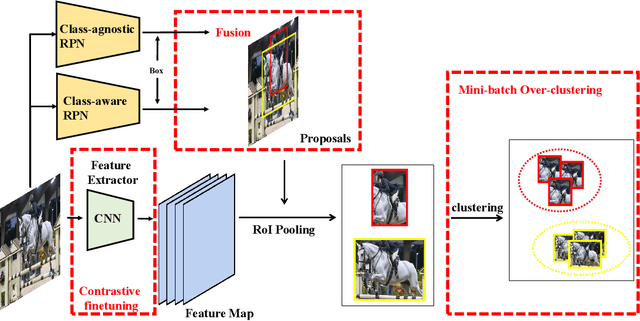

In recent years, object detection in deep learning has experienced rapid development. However, most existing object detection models perform well only on closed-set datasets, ignoring a large number of potential objects whose categories are not defined in the training set. These objects are often identified as background or incorrectly classified as pre-defined categories by the detectors. In this paper, we focus on the challenging problem of Novel Class Discovery and Localization (NCDL), aiming to train detectors that can detect the categories present in the training data, while also actively discover, localize, and cluster new categories. We analyze existing NCDL methods and identify the core issue: object detectors tend to be biased towards seen objects, and this leads to the neglect of unseen targets. To address this issue, we first propose an Debiased Region Mining (DRM) approach that combines class-agnostic Region Proposal Network (RPN) and class-aware RPN in a complementary manner. Additionally, we suggest to improve the representation network through semi-supervised contrastive learning by leveraging unlabeled data. Finally, we adopt a simple and efficient mini-batch K-means clustering method for novel class discovery. We conduct extensive experiments on the NCDL benchmark, and the results demonstrate that the proposed DRM approach significantly outperforms previous methods, establishing a new state-of-the-art.
u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Nov 09, 2023
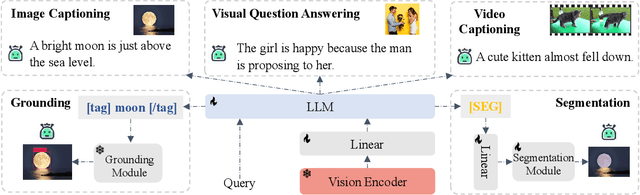
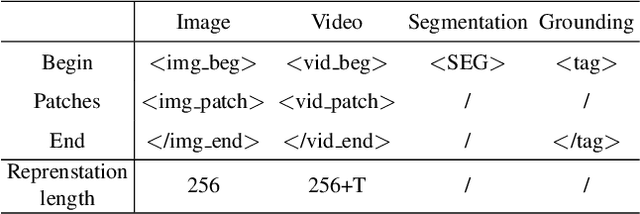

Recent advances such as LLaVA and Mini-GPT4 have successfully integrated visual information into LLMs, yielding inspiring outcomes and giving rise to a new generation of multi-modal LLMs, or MLLMs. Nevertheless, these methods struggle with hallucinations and the mutual interference between tasks. To tackle these problems, we propose an efficient and accurate approach to adapt to downstream tasks by utilizing LLM as a bridge to connect multiple expert models, namely u-LLaVA. Firstly, we incorporate the modality alignment module and multi-task modules into LLM. Then, we reorganize or rebuild multi-type public datasets to enable efficient modality alignment and instruction following. Finally, task-specific information is extracted from the trained LLM and provided to different modules for solving downstream tasks. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also release our model, the generated data, and the code base publicly available.
Inject Semantic Concepts into Image Tagging for Open-Set Recognition
Oct 23, 2023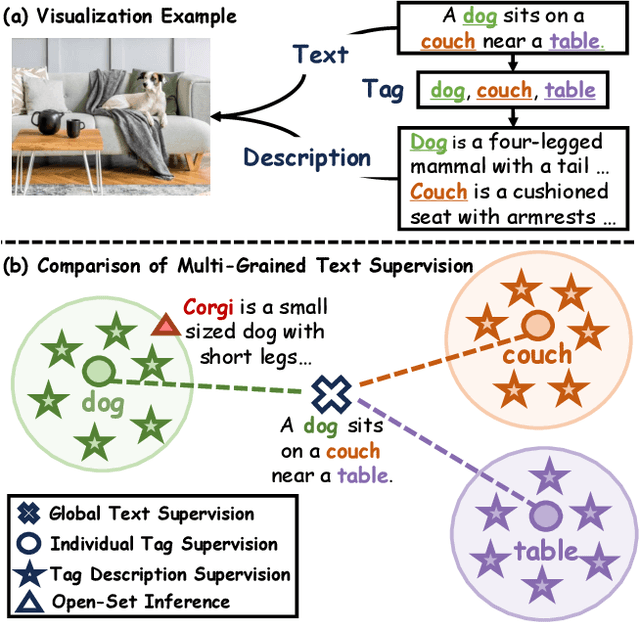
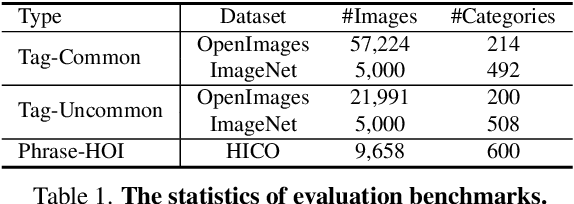
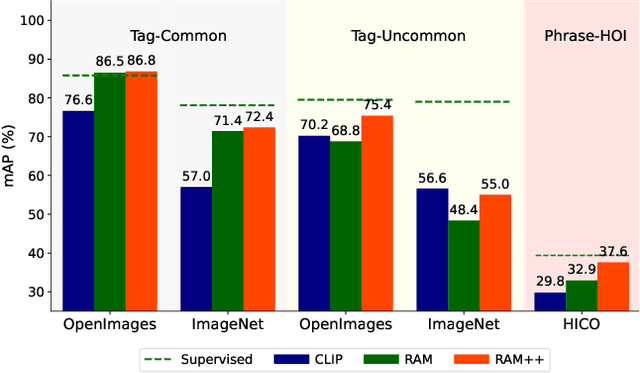
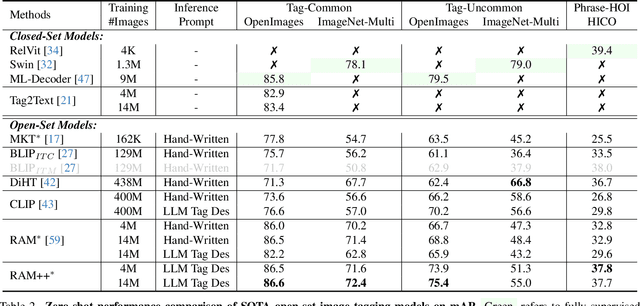
In this paper, we introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark. Code, datasets and pre-trained models are available at \url{https://github.com/xinyu1205/recognize-anything}.
CLIP Brings Better Features to Visual Aesthetics Learners
Jul 28, 2023The success of pre-training approaches on a variety of downstream tasks has revitalized the field of computer vision. Image aesthetics assessment (IAA) is one of the ideal application scenarios for such methods due to subjective and expensive labeling procedure. In this work, an unified and flexible two-phase \textbf{C}LIP-based \textbf{S}emi-supervised \textbf{K}nowledge \textbf{D}istillation paradigm is proposed, namely \textbf{\textit{CSKD}}. Specifically, we first integrate and leverage a multi-source unlabeled dataset to align rich features between a given visual encoder and an off-the-shelf CLIP image encoder via feature alignment loss. Notably, the given visual encoder is not limited by size or structure and, once well-trained, it can seamlessly serve as a better visual aesthetic learner for both student and teacher. In the second phase, the unlabeled data is also utilized in semi-supervised IAA learning to further boost student model performance when applied in latency-sensitive production scenarios. By analyzing the attention distance and entropy before and after feature alignment, we notice an alleviation of feature collapse issue, which in turn showcase the necessity of feature alignment instead of training directly based on CLIP image encoder. Extensive experiments indicate the superiority of CSKD, which achieves state-of-the-art performance on multiple widely used IAA benchmarks.
Recognize Anything: A Strong Image Tagging Model
Jun 09, 2023



We present the Recognize Anything Model (RAM): a strong foundation model for image tagging. RAM makes a substantial step for large models in computer vision, demonstrating the zero-shot ability to recognize any common category with high accuracy. RAM introduces a new paradigm for image tagging, leveraging large-scale image-text pairs for training instead of manual annotations. The development of RAM comprises four key steps. Firstly, annotation-free image tags are obtained at scale through automatic text semantic parsing. Subsequently, a preliminary model is trained for automatic annotation by unifying the caption and tagging tasks, supervised by the original texts and parsed tags, respectively. Thirdly, a data engine is employed to generate additional annotations and clean incorrect ones. Lastly, the model is retrained with the processed data and fine-tuned using a smaller but higher-quality dataset. We evaluate the tagging capabilities of RAM on numerous benchmarks and observe impressive zero-shot performance, significantly outperforming CLIP and BLIP. Remarkably, RAM even surpasses the fully supervised manners and exhibits competitive performance with the Google tagging API. We are releasing the RAM at \url{https://recognize-anything.github.io/} to foster the advancements of large models in computer vision.
Correlation Filter Selection for Visual Tracking Using Reinforcement Learning
Nov 08, 2018
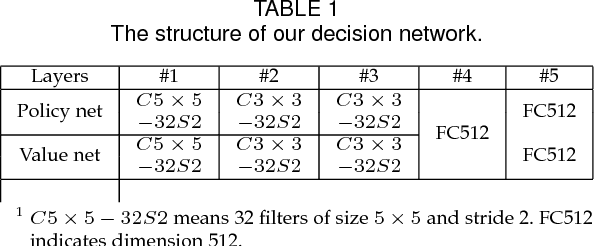
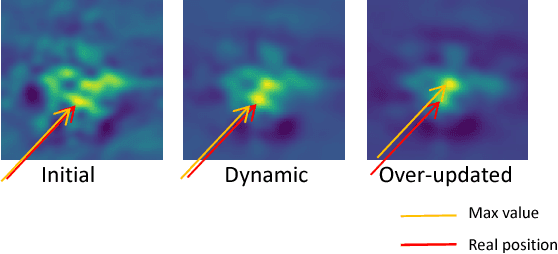

Correlation filter has been proven to be an effective tool for a number of approaches in visual tracking, particularly for seeking a good balance between tracking accuracy and speed. However, correlation filter based models are susceptible to wrong updates stemming from inaccurate tracking results. To date, little effort has been devoted towards handling the correlation filter update problem. In this paper, we propose a novel approach to address the correlation filter update problem. In our approach, we update and maintain multiple correlation filter models in parallel, and we use deep reinforcement learning for the selection of an optimal correlation filter model among them. To facilitate the decision process in an efficient manner, we propose a decision-net to deal target appearance modeling, which is trained through hundreds of challenging videos using proximal policy optimization and a lightweight learning network. An exhaustive evaluation of the proposed approach on the OTB100 and OTB2013 benchmarks show that the approach is effective enough to achieve the average success rate of 62.3% and the average precision score of 81.2%, both exceeding the performance of traditional correlation filter based trackers.
IAN: The Individual Aggregation Network for Person Search
May 16, 2017
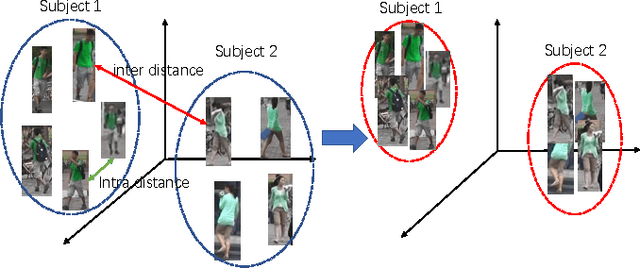
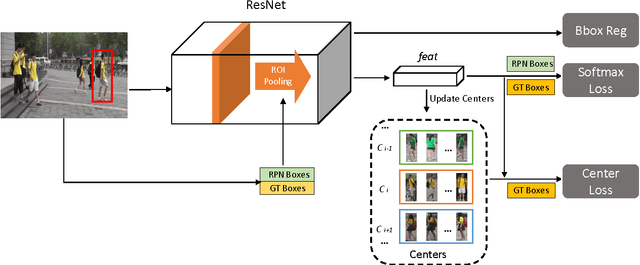
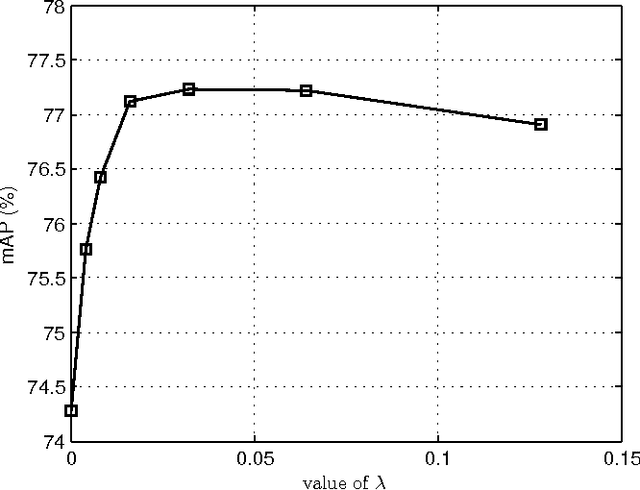
Person search in real-world scenarios is a new challenging computer version task with many meaningful applications. The challenge of this task mainly comes from: (1) unavailable bounding boxes for pedestrians and the model needs to search for the person over the whole gallery images; (2) huge variance of visual appearance of a particular person owing to varying poses, lighting conditions, and occlusions. To address these two critical issues in modern person search applications, we propose a novel Individual Aggregation Network (IAN) that can accurately localize persons by learning to minimize intra-person feature variations. IAN is built upon the state-of-the-art object detection framework, i.e., faster R-CNN, so that high-quality region proposals for pedestrians can be produced in an online manner. In addition, to relieve the negative effect caused by varying visual appearances of the same individual, IAN introduces a novel center loss that can increase the intra-class compactness of feature representations. The engaged center loss encourages persons with the same identity to have similar feature characteristics. Extensive experimental results on two benchmarks, i.e., CUHK-SYSU and PRW, well demonstrate the superiority of the proposed model. In particular, IAN achieves 77.23% mAP and 80.45% top-1 accuracy on CUHK-SYSU, which outperform the state-of-the-art by 1.7% and 1.85%, respectively.