 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Graph Condensation from the Causal Perspective
Jan 29, 2026The increasing scale of graph datasets has significantly improved the performance of graph representation learning methods, but it has also introduced substantial training challenges. Graph dataset condensation techniques have emerged to compress large datasets into smaller yet information-rich datasets, while maintaining similar test performance. However, these methods strictly require downstream applications to match the original dataset and task, which often fails in cross-task and cross-domain scenarios. To address these challenges, we propose a novel causal-invariance-based and transferable graph dataset condensation method, named \textbf{TGCC}, providing effective and transferable condensed datasets. Specifically, to preserve domain-invariant knowledge, we first extract domain causal-invariant features from the spatial domain of the graph using causal interventions. Then, to fully capture the structural and feature information of the original graph, we perform enhanced condensation operations. Finally, through spectral-domain enhanced contrastive learning, we inject the causal-invariant features into the condensed graph, ensuring that the compressed graph retains the causal information of the original graph. Experimental results on five public datasets and our novel \textbf{FinReport} dataset demonstrate that TGCC achieves up to a 13.41\% improvement in cross-task and cross-domain complex scenarios compared to existing methods, and achieves state-of-the-art performance on 5 out of 6 datasets in the single dataset and task scenario.
Affective Computing in the Era of Large Language Models: A Survey from the NLP Perspective
Jul 30, 2024



Affective Computing (AC), integrating computer science, psychology, and cognitive science knowledge, aims to enable machines to recognize, interpret, and simulate human emotions.To create more value, AC can be applied to diverse scenarios, including social media, finance, healthcare, education, etc. Affective Computing (AC) includes two mainstream tasks, i.e., Affective Understanding (AU) and Affective Generation (AG). Fine-tuning Pre-trained Language Models (PLMs) for AU tasks has succeeded considerably. However, these models lack generalization ability, requiring specialized models for specific tasks. Additionally, traditional PLMs face challenges in AG, particularly in generating diverse and emotionally rich responses. The emergence of Large Language Models (LLMs), such as the ChatGPT series and LLaMA models, brings new opportunities and challenges, catalyzing a paradigm shift in AC. LLMs possess capabilities of in-context learning, common sense reasoning, and advanced sequence generation, which present unprecedented opportunities for AU. To provide a comprehensive overview of AC in the LLMs era from an NLP perspective, we summarize the development of LLMs research in this field, aiming to offer new insights. Specifically, we first summarize the traditional tasks related to AC and introduce the preliminary study based on LLMs. Subsequently, we outline the relevant techniques of popular LLMs to improve AC tasks, including Instruction Tuning and Prompt Engineering. For Instruction Tuning, we discuss full parameter fine-tuning and parameter-efficient methods such as LoRA, P-Tuning, and Prompt Tuning. In Prompt Engineering, we examine Zero-shot, Few-shot, Chain of Thought (CoT), and Agent-based methods for AU and AG. To clearly understand the performance of LLMs on different Affective Computing tasks, we further summarize the existing benchmarks and evaluation methods.
Continuous-time q-Learning for Jump-Diffusion Models under Tsallis Entropy
Jul 04, 2024This paper studies continuous-time reinforcement learning for controlled jump-diffusion models by featuring the q-function (the continuous-time counterpart of Q-function) and the q-learning algorithms under the Tsallis entropy regularization. Contrary to the conventional Shannon entropy, the general form of Tsallis entropy renders the optimal policy not necessary a Gibbs measure, where some Lagrange multiplier and KKT multiplier naturally arise from certain constraints to ensure the learnt policy to be a probability distribution. As a consequence,the relationship between the optimal policy and the q-function also involves the Lagrange multiplier. In response, we establish the martingale characterization of the q-function under Tsallis entropy and devise two q-learning algorithms depending on whether the Lagrange multiplier can be derived explicitly or not. In the latter case, we need to consider different parameterizations of the q-function and the policy and update them alternatively. Finally, we examine two financial applications, namely an optimal portfolio liquidation problem and a non-LQ control problem. It is interesting to see therein that the optimal policies under the Tsallis entropy regularization can be characterized explicitly, which are distributions concentrate on some compact support. The satisfactory performance of our q-learning algorithm is illustrated in both examples.
LangGPT: Rethinking Structured Reusable Prompt Design Framework for LLMs from the Programming Language
Feb 26, 2024LLMs have demonstrated commendable performance across diverse domains. Nevertheless, formulating high-quality prompts to effectively instruct LLMs poses a challenge for non-AI experts. Existing research in prompt engineering suggests somewhat fragmented optimization principles and designs empirically dependent prompt optimizers. Unfortunately, these endeavors lack a structured design template, incurring high learning costs and resulting in low reusability. Inspired by structured reusable programming languages, we propose LangGPT, a dual-layer prompt design framework as the programming language for LLMs. LangGPT has an easy-to-learn normative structure and provides an extended structure for migration and reuse. Experiments illustrate that LangGPT significantly enhances the capacity of LLMs to produce responses of superior quality compared to baselines. Moreover, LangGPT has proven effective in guiding LLMs to generate high-quality prompts. We have built a community on LangGPT to facilitate the tuition and sharing of prompt design. We also analyzed the ease of use and reusability of LangGPT through a community user survey.
CLIP Brings Better Features to Visual Aesthetics Learners
Jul 28, 2023The success of pre-training approaches on a variety of downstream tasks has revitalized the field of computer vision. Image aesthetics assessment (IAA) is one of the ideal application scenarios for such methods due to subjective and expensive labeling procedure. In this work, an unified and flexible two-phase \textbf{C}LIP-based \textbf{S}emi-supervised \textbf{K}nowledge \textbf{D}istillation paradigm is proposed, namely \textbf{\textit{CSKD}}. Specifically, we first integrate and leverage a multi-source unlabeled dataset to align rich features between a given visual encoder and an off-the-shelf CLIP image encoder via feature alignment loss. Notably, the given visual encoder is not limited by size or structure and, once well-trained, it can seamlessly serve as a better visual aesthetic learner for both student and teacher. In the second phase, the unlabeled data is also utilized in semi-supervised IAA learning to further boost student model performance when applied in latency-sensitive production scenarios. By analyzing the attention distance and entropy before and after feature alignment, we notice an alleviation of feature collapse issue, which in turn showcase the necessity of feature alignment instead of training directly based on CLIP image encoder. Extensive experiments indicate the superiority of CSKD, which achieves state-of-the-art performance on multiple widely used IAA benchmarks.
Box-Level Active Detection
Mar 23, 2023Active learning selects informative samples for annotation within budget, which has proven efficient recently on object detection. However, the widely used active detection benchmarks conduct image-level evaluation, which is unrealistic in human workload estimation and biased towards crowded images. Furthermore, existing methods still perform image-level annotation, but equally scoring all targets within the same image incurs waste of budget and redundant labels. Having revealed above problems and limitations, we introduce a box-level active detection framework that controls a box-based budget per cycle, prioritizes informative targets and avoids redundancy for fair comparison and efficient application. Under the proposed box-level setting, we devise a novel pipeline, namely Complementary Pseudo Active Strategy (ComPAS). It exploits both human annotations and the model intelligence in a complementary fashion: an efficient input-end committee queries labels for informative objects only; meantime well-learned targets are identified by the model and compensated with pseudo-labels. ComPAS consistently outperforms 10 competitors under 4 settings in a unified codebase. With supervision from labeled data only, it achieves 100% supervised performance of VOC0712 with merely 19% box annotations. On the COCO dataset, it yields up to 4.3% mAP improvement over the second-best method. ComPAS also supports training with the unlabeled pool, where it surpasses 90% COCO supervised performance with 85% label reduction. Our source code is publicly available at https://github.com/lyumengyao/blad.
Unsupervised Learning of Local Discriminative Representation for Medical Images
Dec 17, 2020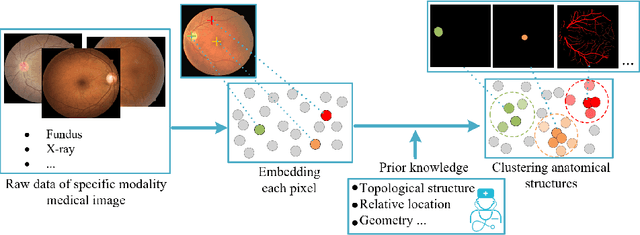
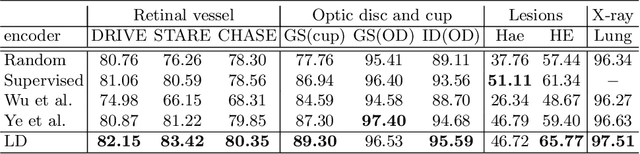
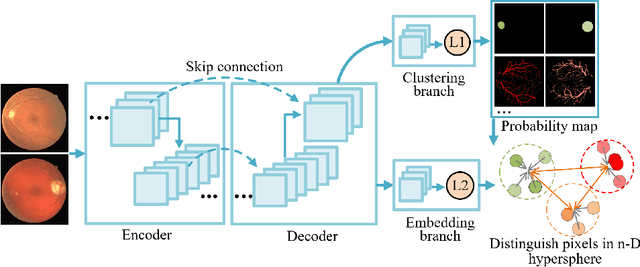
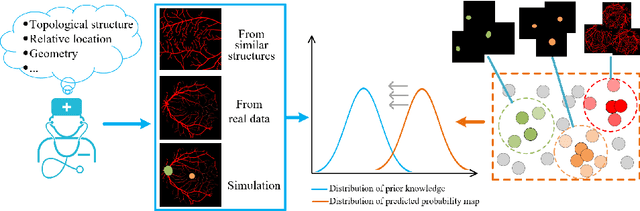
Local discriminative representation is needed in many medical image analysis tasks such as identifying sub-types of lesion or segmenting detailed components of anatomical structures by measuring similarity of local image regions. However, the commonly applied supervised representation learning methods require a large amount of annotated data, and unsupervised discriminative representation learning distinguishes different images by learning a global feature. In order to avoid the limitations of these two methods and be suitable for localized medical image analysis tasks, we introduce local discrimination into unsupervised representation learning in this work. The model contains two branches: one is an embedding branch which learns an embedding function to disperse dissimilar pixels over a low-dimensional hypersphere; and the other is a clustering branch which learns a clustering function to classify similar pixels into the same cluster. These two branches are trained simultaneously in a mutually beneficial pattern, and the learnt local discriminative representations are able to well measure the similarity of local image regions. These representations can be transferred to enhance various downstream tasks. Meanwhile, they can also be applied to cluster anatomical structures from unlabeled medical images under the guidance of topological priors from simulation or other structures with similar topological characteristics. The effectiveness and usefulness of the proposed method are demonstrated by enhancing various downstream tasks and clustering anatomical structures in retinal images and chest X-ray images. The corresponding code is available at https://github.com/HuaiChen-1994/LDLearning.