 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangGPT: Rethinking Structured Reusable Prompt Design Framework for LLMs from the Programming Language
Feb 26, 2024LLMs have demonstrated commendable performance across diverse domains. Nevertheless, formulating high-quality prompts to effectively instruct LLMs poses a challenge for non-AI experts. Existing research in prompt engineering suggests somewhat fragmented optimization principles and designs empirically dependent prompt optimizers. Unfortunately, these endeavors lack a structured design template, incurring high learning costs and resulting in low reusability. Inspired by structured reusable programming languages, we propose LangGPT, a dual-layer prompt design framework as the programming language for LLMs. LangGPT has an easy-to-learn normative structure and provides an extended structure for migration and reuse. Experiments illustrate that LangGPT significantly enhances the capacity of LLMs to produce responses of superior quality compared to baselines. Moreover, LangGPT has proven effective in guiding LLMs to generate high-quality prompts. We have built a community on LangGPT to facilitate the tuition and sharing of prompt design. We also analyzed the ease of use and reusability of LangGPT through a community user survey.
Optical Flow for Video Super-Resolution: A Survey
Mar 20, 2022


Video super-resolution is currently one of the most active research topics in computer vision as it plays an important role in many visual applications. Generally, video super-resolution contains a significant component, i.e., motion compensation, which is used to estimate the displacement between successive video frames for temporal alignment. Optical flow, which can supply dense and sub-pixel motion between consecutive frames, is among the most common ways for this task. To obtain a good understanding of the effect that optical flow acts in video super-resolution, in this work, we conduct a comprehensive review on this subject for the first time. This investigation covers the following major topics: the function of super-resolution (i.e., why we require super-resolution); the concept of video super-resolution (i.e., what is video super-resolution); the description of evaluation metrics (i.e., how (video) superresolution performs); the introduction of optical flow based video super-resolution; the investigation of using optical flow to capture temporal dependency for video super-resolution. Prominently, we give an in-depth study of the deep learning based video super-resolution method, where some representative algorithms are analyzed and compared. Additionally, we highlight some promising research directions and open issues that should be further addressed.
Slow-Fast Visual Tempo Learning for Video-based Action Recognition
Feb 24, 2022
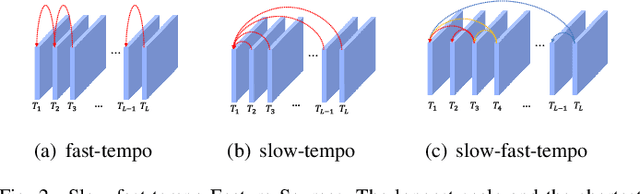


Action visual tempo characterizes the dynamics and the temporal scale of an action, which is helpful to distinguish human actions that share high similarities in visual dynamics and appearance. Previous methods capture the visual tempo either by sampling raw videos with multiple rates, which requires a costly multi-layer network to handle each rate, or by hierarchically sampling backbone features, which relies heavily on high-level features that miss fine-grained temporal dynamics. In this work, we propose a Temporal Correlation Module (TCM), which can be easily embedded into the current action recognition backbones in a plug-in-and-play manner, to extract action visual tempo from low-level backbone features at single-layer remarkably. Specifically, our TCM contains two main components: a Multi-scale Temporal Dynamics Module (MTDM) and a Temporal Attention Module (TAM). MTDM applies a correlation operation to learn pixel-wise fine-grained temporal dynamics for both fast-tempo and slow-tempo. TAM adaptively emphasizes expressive features and suppresses inessential ones via analyzing the global information across various tempos. Extensive experiments conducted on several action recognition benchmarks, e.g. Something-Something V1 & V2, Kinetics-400, UCF-101, and HMDB-51, have demonstrated that the proposed TCM is effective to promote the performance of the existing video-based action recognition models for a large margin. The source code is publicly released at https://github.com/zphyix/TCM.
The Multi-Modal Video Reasoning and Analyzing Competition
Aug 18, 2021



In this paper, we introduce the Multi-Modal Video Reasoning and Analyzing Competition (MMVRAC) workshop in conjunction with ICCV 2021. This competition is composed of four different tracks, namely, video question answering, skeleton-based action recognition, fisheye video-based action recognition, and person re-identification, which are based on two datasets: SUTD-TrafficQA and UAV-Human. We summarize the top-performing methods submitted by the participants in this competition and show their results achieved in the competition.