 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkelHCC: A Hyperbolic CLIP-Driven Cache Adaptation Framework for Skeleton-based One-Shot Action Recognition
Jun 02, 2026Skeleton-based action recognition aims to understand human behaviors from body joint sequences and is especially challenging in the one-shot setting, where only a single labeled exemplar is available for each novel action. A key challenge is learning representations that capture the hierarchical and compositional structure of human motion while aligning effectively with high-level action semantics under extreme data scarcity. Existing approaches, largely based on Euclidean embeddings and low-level motion cues, struggle to model the tree-like organization of skeleton data, limiting cross-modal alignment and generalization to unseen action categories. We propose SkelHCC, a unified skeleton hyperbolic CLIP-driven cache adaptation framework for one-shot skeleton-based action recognition. SkelHCC introduces an Explicitly Hierarchical Hyperbolic CLIP (EH-HCLIP) module that embeds skeleton sequences and action language into a shared hyperbolic space. By leveraging the negative curvature and exponential volume growth of hyperbolic geometry, EH-HCLIP naturally encodes the joint-part-body hierarchy of human anatomy and yields structurally consistent cross-modal representations. To support efficient one-shot adaptation, SkelHCC further integrates a training-free LLM-guided Multi-granularity Voting Cache (LMV-Cache) for context-aware inference. Experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD demonstrate that SkelHCC consistently outperforms state-of-the-art methods.
ToolFG: Towards Well-Grounded Fine-Grained Image Classification
Jun 01, 2026Fine-grained image classification (FGIC) has broad applications and has attracted significant research attention. In this paper, we explore a novel paradigm for solving FGIC by proposing \textbf{ToolFG}, the first tool-integrated MLLM-based framework tailored to FGIC. ToolFG enables MLLMs to autonomously and flexibly use external tools during the reasoning process, actively interact with images, and collect verifiable visual cues for distinguishing highly similar categories in a more \textit{reliable} and \textit{well-grounded} manner. To equip the model with such tool-use ability, we design a novel \textbf{MCTS-guided tool-use knowledge distillation mechanism}, which effectively mines tool-use- and FGIC-relevant knowledge from advanced proprietary MLLMs for model training. Furthermore, we propose a \textbf{model-tool co-evolution mechanism} that jointly refines the toolset and the model's tool-use policy, driving them toward a mutually adapted and FGIC-specialized state. Extensive experiments demonstrate the effectiveness of our framework.
NDPP-Grasp: Non-Differentiable Physical Plausibility Constraint-Guided Task-Oriented Dexterous Grasp Generation
Jun 01, 2026Task-oriented dexterous grasp generation aims to produce dexterous grasp poses that are both physically plausible and functionally suitable for specified manipulation tasks. Existing diffusion-based methods often address these two requirements in a decoupled manner: they first train a grasp diffusion model for task alignment and then rely on post-generation refinement to improve physical plausibility. However, this after-the-fact correction strategy applies physical plausibility guidance only once the grasp has already been generated, leaving the generation trajectory itself unguided by physical constraints and potentially leading to suboptimal grasps. To address this problem, we propose a novel framework that directly injects physical plausibility guidance into the denoising process of a task-aligned grasp diffusion model in a practical and effective manner, even when physical plausibility constraints are non-differentiable. This allows physical plausibility to shape grasp generation throughout denoising while preserving task alignment. Extensive experiments demonstrate the efficacy of our framework.
Translating Signals to Languages for sEMG-Based Activity Recognition
May 21, 2026Surface electromyography (sEMG) signal-based activity recognition has attracted increasing research attention in recent years. To develop accurate sEMG signal-based activity recognizers, numerous approaches have been proposed. Some studies focus on designing larger and more expressive model architectures to enhance the representational capacity of sEMG signals, while others aim to enrich model priors through large-scale pretraining, thereby improving recognition performance. Recently, large language models (LLMs) have shown remarkable generalization and reasoning capabilities in natural language processing, whose implicit knowledge, learned from extensive linguistic descriptions of actions, opens new possibilities for interpreting sEMG signals and inferring activity intentions. Motivated by this, we propose LLM-sEMG, a novel framework that leverages LLMs as sEMG activity recognizers. Within this framework, we design a language-oriented mapping mechanism that converts continuous sEMG sequences into sEMG language, integrating several strategies to further facilitate the signal-to-language mapping process. Extensive experiments demonstrate that the proposed framework achieves highly accurate sEMG signal-based activity recognition using large language models.
MicroscopyMatching: Towards a Ready-to-use Framework for Microscopy Image Analysis in Diverse Conditions
May 14, 2026Analyzing microscopy images to extract biological object properties (e.g., their morphological organization, temporal dynamics, and population density) is fundamental to various biomedical research. Yet conducting this manually is costly and time-consuming. Though deep learning-based approaches have been explored to automate this process, the substantial diversity of microscopy analysis settings in practice (including variations of biological object types, sample processing protocols, imaging equipment, and analysis tasks, etc.) often renders them ineffective. As a result, these approaches typically require extensive adaptation for different settings, which, however, can impose burdens that are often practically unsustainable for laboratories, forcing biomedical researchers to still commonly rely on manual analysis, thereby severely bottlenecking the pace of biomedical research progress. This situation has created a pressing and long-standing need for a reliable and broadly applicable microscopy image analysis tool, yet such a tool is still missing. To address this gap, we present the first ready-to-use microscopy image analysis framework, MicroscopyMatching, that can reliably perform key analysis tasks (including segmentation, tracking, and counting) across diverse microscopy analysis settings. From a fundamentally different perspective, MicroscopyMatching reformulates diverse microscopy image analysis tasks as a unified matching problem, effectively handling this problem by exploiting the robust matching capability from pre-trained latent diffusion models.
Is Monitoring Enough? Strategic Agent Selection For Stealthy Attack in Multi-Agent Discussions
Mar 22, 2026Multi-agent discussions have been widely adopted, motivating growing efforts to develop attacks that expose their vulnerabilities. In this work, we study a practical yet largely unexplored attack scenario, the discussion-monitored scenario, where anomaly detectors continuously monitor inter-agent communications and block detected adversarial messages. Although existing attacks are effective without discussion monitoring, we show that they exhibit detectable patterns and largely fail under such monitoring constraints. But does this imply that monitoring alone is sufficient to secure multi-agent discussions? To answer this question, we develop a novel attack method explicitly tailored to the discussion-monitored scenario. Extensive experiments demonstrate that effective attacks remain possible even under continuous monitoring, indicating that monitoring alone does not eliminate adversarial risks.
DiffGraph: An Automated Agent-driven Model Merging Framework for In-the-Wild Text-to-Image Generation
Mar 20, 2026The rapid growth of the text-to-image (T2I) community has fostered a thriving online ecosystem of expert models, which are variants of pretrained diffusion models specialized for diverse generative abilities. Yet, existing model merging methods remain limited in fully leveraging abundant online expert resources and still struggle to meet diverse in-the-wild user needs. We present DiffGraph, a novel agent-driven graph-based model merging framework, which automatically harnesses online experts and flexibly merges them for diverse user needs. Our DiffGraph constructs a scalable graph and organizes ever-expanding online experts within it through node registration and calibration. Then, DiffGraph dynamically activates specific subgraphs based on user needs, enabling flexible combinations of different experts to achieve user-desired generation. Extensive experiments show the efficacy of our method.
Generalized Hand-Object Pose Estimation with Occlusion Awareness
Mar 19, 2026Generalized 3D hand-object pose estimation from a single RGB image remains challenging due to the large variations in object appearances and interaction patterns, especially under heavy occlusion. We propose GenHOI, a framework for generalized hand-object pose estimation with occlusion awareness. GenHOI integrates hierarchical semantic knowledge with hand priors to enhance model generalization under challenging occlusion conditions. Specifically, we introduce a hierarchical semantic prompt that encodes object states, hand configurations, and interaction patterns via textual descriptions. This enables the model to learn abstract high-level representations of hand-object interactions for generalization to unseen objects and novel interactions while compensating for missing or ambiguous visual cues. To enable robust occlusion reasoning, we adopt a multi-modal masked modeling strategy over RGB images, predicted point clouds, and textual descriptions. Moreover, we leverage hand priors as stable spatial references to extract implicit interaction constraints. This allows reliable pose inference even under significant variations in object shapes and interaction patterns. Extensive experiments on the challenging DexYCB and HO3Dv2 benchmarks demonstrate that our method achieves state-of-the-art performance in hand-object pose estimation.
When Visual Privacy Protection Meets Multimodal Large Language Models
Mar 14, 2026The emergence of Multimodal Large Language Models (MLLMs) and the widespread usage of MLLM cloud services such as GPT-4V raised great concerns about privacy leakage in visual data. As these models are typically deployed in cloud services, users are required to submit their images and videos, posing serious privacy risks. However, how to tackle such privacy concerns is an under-explored problem. Thus, in this paper, we aim to conduct a new investigation to protect visual privacy when enjoying the convenience brought by MLLM services. We address the practical case where the MLLM is a "black box", i.e., we only have access to its input and output without knowing its internal model information. To tackle such a challenging yet demanding problem, we propose a novel framework, in which we carefully design the learning objective with Pareto optimality to seek a better trade-off between visual privacy and MLLM's performance, and propose critical-history enhanced optimization to effectively optimize the framework with the black-box MLLM. Our experiments show that our method is effective on different benchmarks.
Learning to Generate Cross-Task Unexploitable Examples
Dec 15, 2025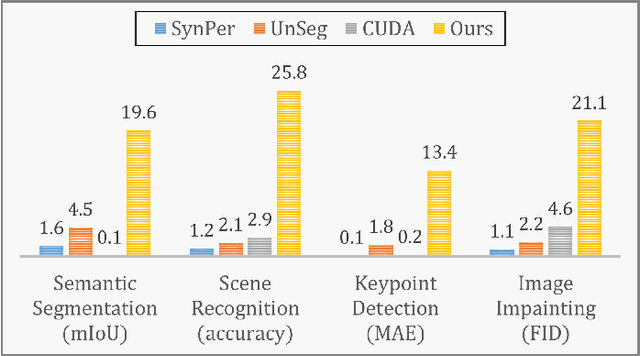
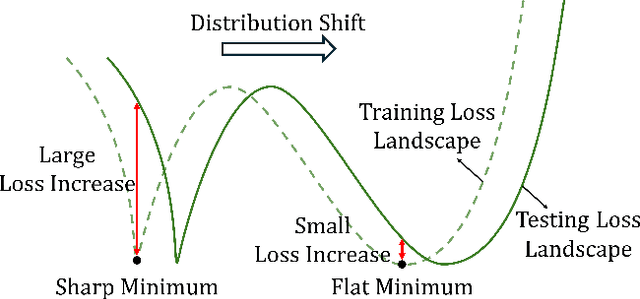

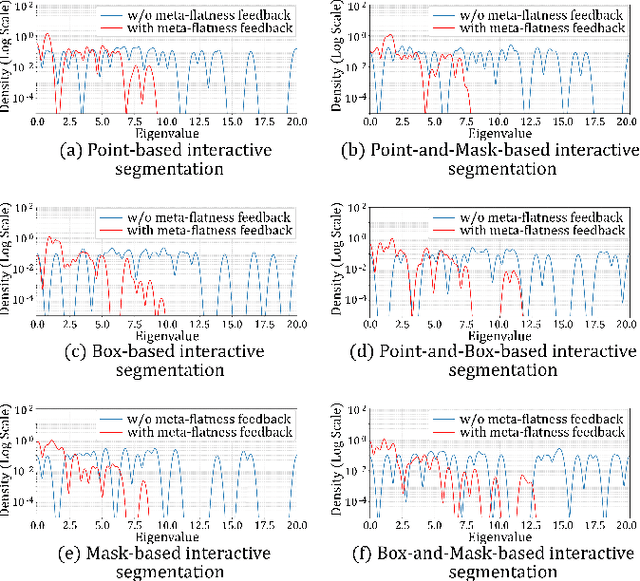
Unexploitable example generation aims to transform personal images into their unexploitable (unlearnable) versions before they are uploaded online, thereby preventing unauthorized exploitation of online personal images. Recently, this task has garnered significant research attention due to its critical relevance to personal data privacy. Yet, despite recent progress, existing methods for this task can still suffer from limited practical applicability, as they can fail to generate examples that are broadly unexploitable across different real-world computer vision tasks. To deal with this problem, in this work, we propose a novel Meta Cross-Task Unexploitable Example Generation (MCT-UEG) framework. At the core of our framework, to optimize the unexploitable example generator for effectively producing broadly unexploitable examples, we design a flat-minima-oriented meta training and testing scheme. Extensive experiments show the efficacy of our framework.