 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARK denoises spatial transcriptomics images via adaptive regularization
Dec 10, 2025We present an approach to denoising spatial transcriptomics images that is particularly effective for uncovering cell identities in the regime of ultra-low sequencing depths, and also allows for interpolation of gene expression. The method -- Spatial Transcriptomics via Adaptive Regularization and Kernels (STARK) -- augments kernel ridge regression with an incrementally adaptive graph Laplacian regularizer. In each iteration, we (1) perform kernel ridge regression with a fixed graph to update the image, and (2) update the graph based on the new image. The kernel ridge regression step involves reducing the infinite dimensional problem on a space of images to finite dimensions via a modified representer theorem. Starting with a purely spatial graph, and updating it as we improve our image makes the graph more robust to noise in low sequencing depth regimes. We show that the aforementioned approach optimizes a block-convex objective through an alternating minimization scheme wherein the sub-problems have closed form expressions that are easily computed. This perspective allows us to prove convergence of the iterates to a stationary point of this non-convex objective. Statistically, such stationary points converge to the ground truth with rate $\mathcal{O}(R^{-1/2})$ where $R$ is the number of reads. In numerical experiments on real spatial transcriptomics data, the denoising performance of STARK, evaluated in terms of label transfer accuracy, shows consistent improvement over the competing methods tested.
Langevin SDEs have unique transient dynamics
May 27, 2025The overdamped Langevin stochastic differential equation (SDE) is a classical physical model used for chemical, genetic, and hydrological dynamics. In this work, we prove that the drift and diffusion terms of a Langevin SDE are jointly identifiable from temporal marginal distributions if and only if the process is observed out of equilibrium. This complete characterization of structural identifiability removes the long-standing assumption that the diffusion must be known to identify the drift. We then complement our theory with experiments in the finite sample setting and study the practical identifiability of the drift and diffusion, in order to propose heuristics for optimal data collection.
Identifying Drift, Diffusion, and Causal Structure from Temporal Snapshots
Oct 30, 2024Stochastic differential equations (SDEs) are a fundamental tool for modelling dynamic processes, including gene regulatory networks (GRNs), contaminant transport, financial markets, and image generation. However, learning the underlying SDE from observational data is a challenging task, especially when individual trajectories are not observable. Motivated by burgeoning research in single-cell datasets, we present the first comprehensive approach for jointly estimating the drift and diffusion of an SDE from its temporal marginals. Assuming linear drift and additive diffusion, we prove that these parameters are identifiable from marginals if and only if the initial distribution is not invariant to a class of generalized rotations, a condition that is satisfied by most distributions. We further prove that the causal graph of any SDE with additive diffusion can be recovered from the SDE parameters. To complement this theory, we adapt entropy-regularized optimal transport to handle anisotropic diffusion, and introduce APPEX (Alternating Projection Parameter Estimation from $X_0$), an iterative algorithm designed to estimate the drift, diffusion, and causal graph of an additive noise SDE, solely from temporal marginals. We show that each of these steps are asymptotically optimal with respect to the Kullback-Leibler divergence, and demonstrate APPEX's effectiveness on simulated data from linear additive noise SDEs.
Wasserstein Mirror Gradient Flow as the limit of the Sinkhorn Algorithm
Jul 31, 2023

We prove that the sequence of marginals obtained from the iterations of the Sinkhorn algorithm or the iterative proportional fitting procedure (IPFP) on joint densities, converges to an absolutely continuous curve on the $2$-Wasserstein space, as the regularization parameter $\varepsilon$ goes to zero and the number of iterations is scaled as $1/\varepsilon$ (and other technical assumptions). This limit, which we call the Sinkhorn flow, is an example of a Wasserstein mirror gradient flow, a concept we introduce here inspired by the well-known Euclidean mirror gradient flows. In the case of Sinkhorn, the gradient is that of the relative entropy functional with respect to one of the marginals and the mirror is half of the squared Wasserstein distance functional from the other marginal. Interestingly, the norm of the velocity field of this flow can be interpreted as the metric derivative with respect to the linearized optimal transport (LOT) distance. An equivalent description of this flow is provided by the parabolic Monge-Amp\`{e}re PDE whose connection to the Sinkhorn algorithm was noticed by Berman (2020). We derive conditions for exponential convergence for this limiting flow. We also construct a Mckean-Vlasov diffusion whose marginal distributions follow the Sinkhorn flow.
Manifold Learning with Sparse Regularised Optimal Transport
Jul 19, 2023Manifold learning is a central task in modern statistics and data science. Many datasets (cells, documents, images, molecules) can be represented as point clouds embedded in a high dimensional ambient space, however the degrees of freedom intrinsic to the data are usually far fewer than the number of ambient dimensions. The task of detecting a latent manifold along which the data are embedded is a prerequisite for a wide family of downstream analyses. Real-world datasets are subject to noisy observations and sampling, so that distilling information about the underlying manifold is a major challenge. We propose a method for manifold learning that utilises a symmetric version of optimal transport with a quadratic regularisation that constructs a sparse and adaptive affinity matrix, that can be interpreted as a generalisation of the bistochastic kernel normalisation. We prove that the resulting kernel is consistent with a Laplace-type operator in the continuous limit, establish robustness to heteroskedastic noise and exhibit these results in simulations. We identify a highly efficient computational scheme for computing this optimal transport for discrete data and demonstrate that it outperforms competing methods in a set of examples.
Beyond kNN: Adaptive, Sparse Neighborhood Graphs via Optimal Transport
Aug 01, 2022
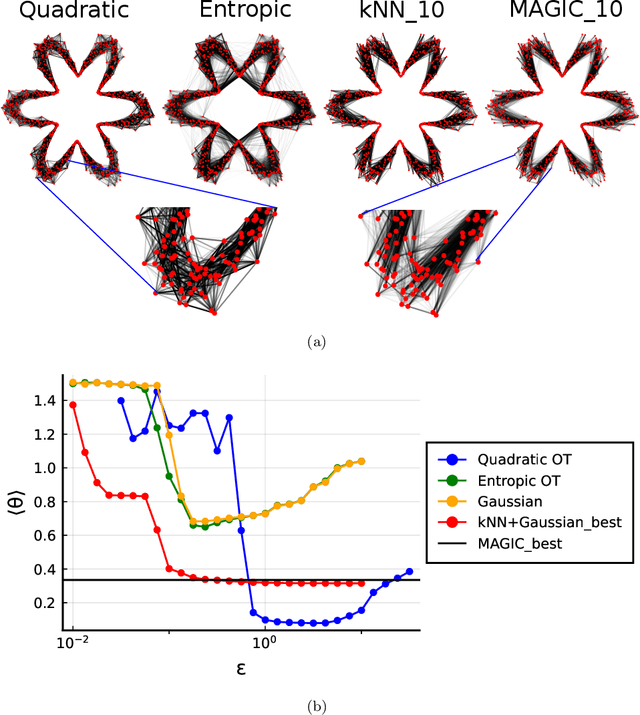
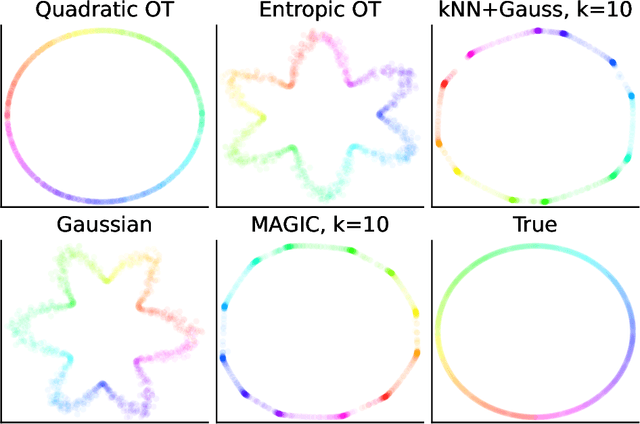
Nearest neighbour graphs are widely used to capture the geometry or topology of a dataset. One of the most common strategies to construct such a graph is based on selecting a fixed number k of nearest neighbours (kNN) for each point. However, the kNN heuristic may become inappropriate when sampling density or noise level varies across datasets. Strategies that try to get around this typically introduce additional parameters that need to be tuned. We propose a simple approach to construct an adaptive neighbourhood graph from a single parameter, based on quadratically regularised optimal transport. Our numerical experiments show that graphs constructed in this manner perform favourably in unsupervised and semi-supervised learning applications.
Trajectory Inference via Mean-field Langevin in Path Space
May 18, 2022

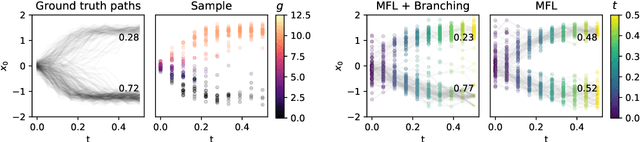
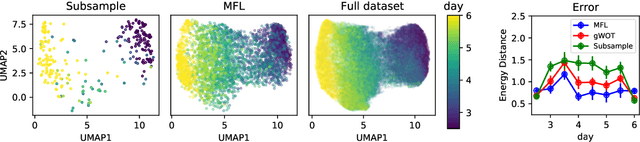
Trajectory inference aims at recovering the dynamics of a population from snapshots of its temporal marginals. To solve this task, a min-entropy estimator relative to the Wiener measure in path space was introduced by Lavenant et al. arXiv:2102.09204, and shown to consistently recover the dynamics of a large class of drift-diffusion processes from the solution of an infinite dimensional convex optimization problem. In this paper, we introduce a grid-free algorithm to compute this estimator. Our method consists in a family of point clouds (one per snapshot) coupled via Schr\"odinger bridges which evolve with noisy gradient descent. We study the mean-field limit of the dynamics and prove its global convergence at an exponential rate to the desired estimator. Overall, this leads to an inference method with end-to-end theoretical guarantees that solves an interpretable model for trajectory inference. We also present how to adapt the method to deal with mass variations, a useful extension when dealing with single cell RNA-sequencing data where cells can branch and die.
Towards a mathematical theory of trajectory inference
Feb 18, 2021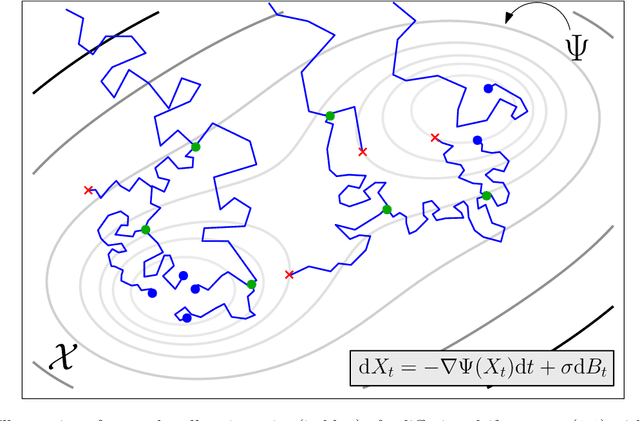

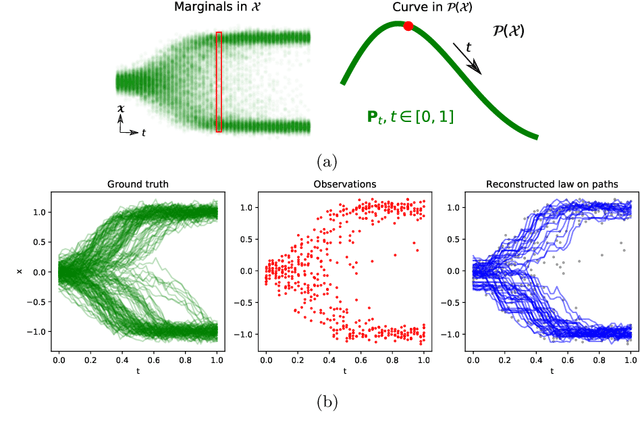
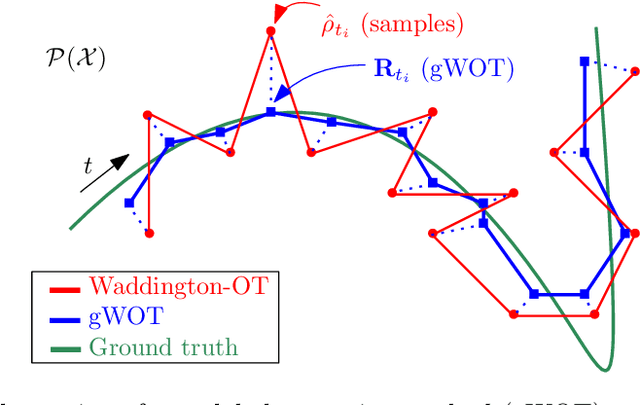
We devise a theoretical framework and a numerical method to infer trajectories of a stochastic process from snapshots of its temporal marginals. This problem arises in the analysis of single cell RNA-sequencing data, which provide high dimensional measurements of cell states but cannot track the trajectories of the cells over time. We prove that for a class of stochastic processes it is possible to recover the ground truth trajectories from limited samples of the temporal marginals at each time-point, and provide an efficient algorithm to do so in practice. The method we develop, Global Waddington-OT (gWOT), boils down to a smooth convex optimization problem posed globally over all time-points involving entropy-regularized optimal transport. We demonstrate that this problem can be solved efficiently in practice and yields good reconstructions, as we show on several synthetic and real datasets.
Reconstructing probabilistic trees of cellular differentiation from single-cell RNA-seq data
Nov 28, 2018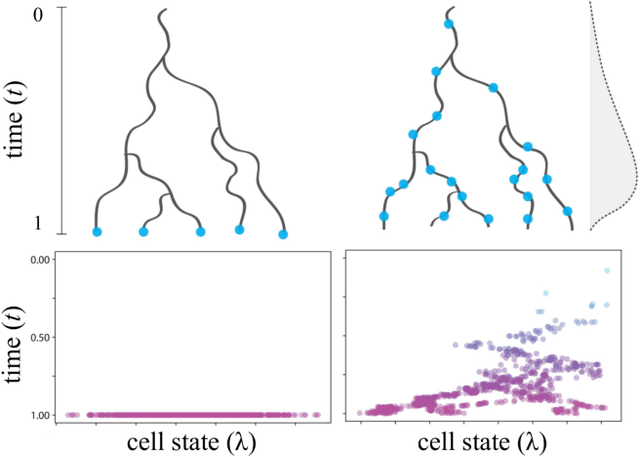


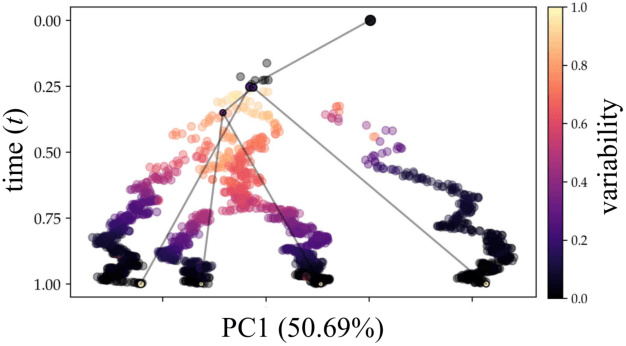
Until recently, transcriptomics was limited to bulk RNA sequencing, obscuring the underlying expression patterns of individual cells in favor of a global average. Thanks to technological advances, we can now profile gene expression across thousands or millions of individual cells in parallel. This new type of data has led to the intriguing discovery that individual cell profiles can reflect the imprint of time or dynamic processes. However, synthesizing this information to reconstruct dynamic biological phenomena from data that are noisy, heterogenous, and sparse---and from processes that may unfold asynchronously---poses a complex computational and statistical challenge. Here, we develop a full generative model for probabilistically reconstructing trees of cellular differentiation from single-cell RNA-seq data. Specifically, we extend the framework of the classical Dirichlet diffusion tree to simultaneously infer branch topology and latent cell states along continuous trajectories over the full tree. In tandem, we construct a novel Markov chain Monte Carlo sampler that interleaves Metropolis-Hastings and message passing to leverage model structure for efficient inference. Finally, we demonstrate that these techniques can recover latent trajectories from simulated single-cell transcriptomes. While this work is motivated by cellular differentiation, we derive a tractable model that provides flexible densities for any data (coupled with an appropriate noise model) that arise from continuous evolution along a latent nonparametric tree.
Statistical Optimal Transport via Factored Couplings
Oct 10, 2018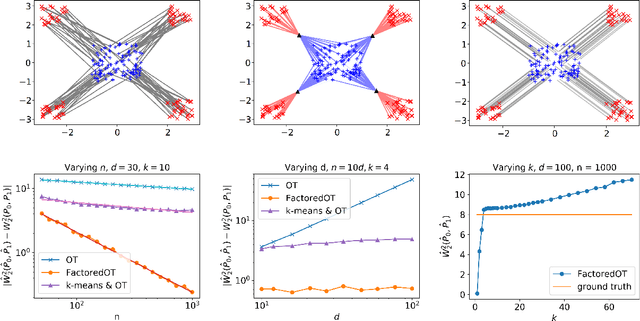
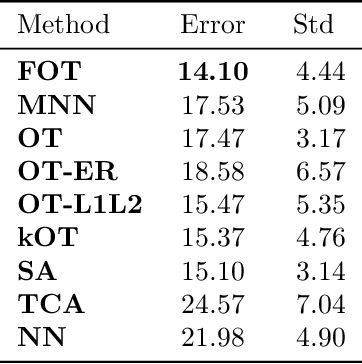
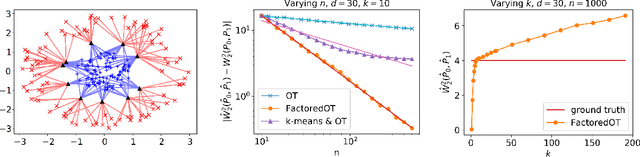

We propose a new method to estimate Wasserstein distances and optimal transport plans between two probability distributions from samples in high dimension. Unlike plug-in rules that simply replace the true distributions by their empirical counterparts, our method pro- motes couplings with low transport rank, a new structural assumption that is similar to the nonnegative rank of a matrix. Regularizing based on this assumption leads to drastic improvements on high-dimensional data for various tasks, including domain adaptation in single-cell RNA sequencing data. These findings are supported by a theoretical analysis that indicates that the transport rank is key in overcoming the curse of dimensionality inherent to data-driven optimal transport.