 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Optimal Transport via Factored Couplings
Paper and Code
Oct 10, 2018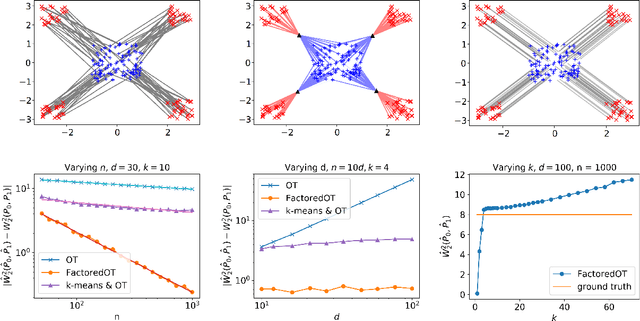
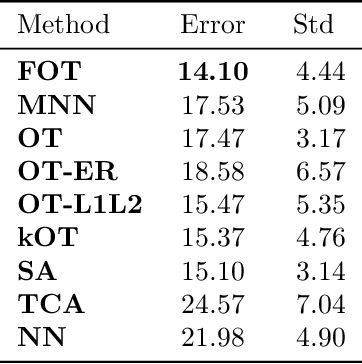
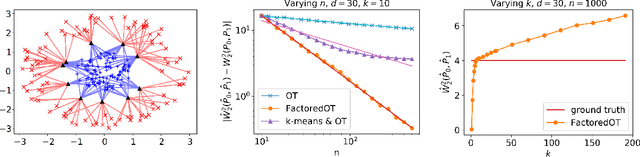

We propose a new method to estimate Wasserstein distances and optimal transport plans between two probability distributions from samples in high dimension. Unlike plug-in rules that simply replace the true distributions by their empirical counterparts, our method pro- motes couplings with low transport rank, a new structural assumption that is similar to the nonnegative rank of a matrix. Regularizing based on this assumption leads to drastic improvements on high-dimensional data for various tasks, including domain adaptation in single-cell RNA sequencing data. These findings are supported by a theoretical analysis that indicates that the transport rank is key in overcoming the curse of dimensionality inherent to data-driven optimal transport.