 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearly Dimension-Independent Convergence of Mean-Field Black-Box Variational Inference
May 27, 2025We prove that, given a mean-field location-scale variational family, black-box variational inference (BBVI) with the reparametrization gradient converges at an almost dimension-independent rate. Specifically, for strongly log-concave and log-smooth targets, the number of iterations for BBVI with a sub-Gaussian family to achieve an objective $\epsilon$-close to the global optimum is $\mathrm{O}(\log d)$, which improves over the $\mathrm{O}(d)$ dependence of full-rank location-scale families. For heavy-tailed families, we provide a weaker $\mathrm{O}(d^{2/k})$ dimension dependence, where $k$ is the number of finite moments. Additionally, if the Hessian of the target log-density is constant, the complexity is free of any explicit dimension dependence. We also prove that our bound on the gradient variance, which is key to our result, cannot be improved using only spectral bounds on the Hessian of the target log-density.
AutoSGD: Automatic Learning Rate Selection for Stochastic Gradient Descent
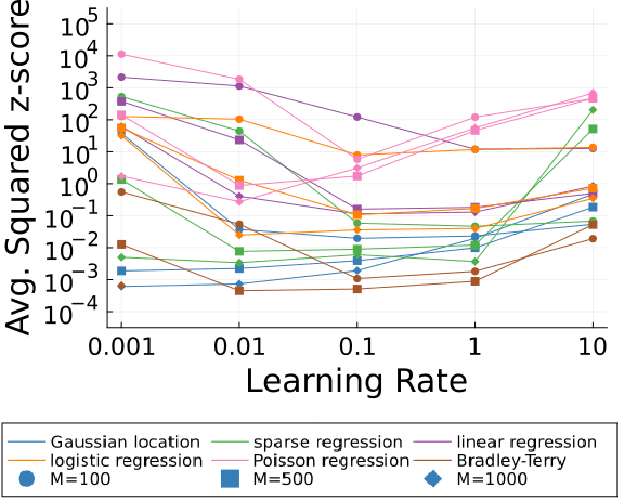
May 27, 2025The learning rate is an important tuning parameter for stochastic gradient descent (SGD) and can greatly influence its performance. However, appropriate selection of a learning rate schedule across all iterations typically requires a non-trivial amount of user tuning effort. To address this, we introduce AutoSGD: an SGD method that automatically determines whether to increase or decrease the learning rate at a given iteration and then takes appropriate action. We introduce theory supporting the convergence of AutoSGD, along with its deterministic counterpart for standard gradient descent. Empirical results suggest strong performance of the method on a variety of traditional optimization problems and machine learning tasks.
Tuning Sequential Monte Carlo Samplers via Greedy Incremental Divergence Minimization
Mar 19, 2025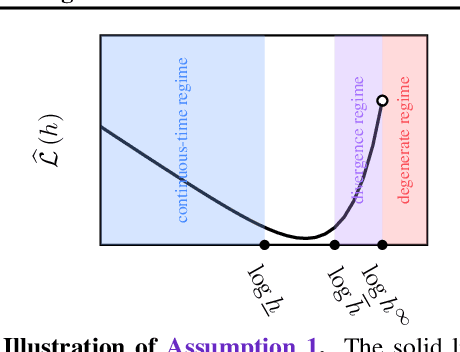

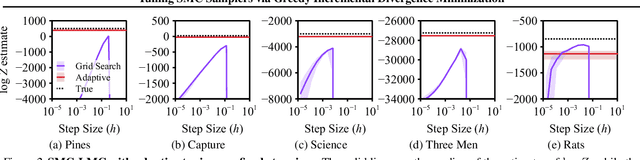
The performance of sequential Monte Carlo (SMC) samplers heavily depends on the tuning of the Markov kernels used in the path proposal. For SMC samplers with unadjusted Markov kernels, standard tuning objectives, such as the Metropolis-Hastings acceptance rate or the expected-squared jump distance, are no longer applicable. While stochastic gradient-based end-to-end optimization has been explored for tuning SMC samplers, they often incur excessive training costs, even for tuning just the kernel step sizes. In this work, we propose a general adaptation framework for tuning the Markov kernels in SMC samplers by minimizing the incremental Kullback-Leibler (KL) divergence between the proposal and target paths. For step size tuning, we provide a gradient- and tuning-free algorithm that is generally applicable for kernels such as Langevin Monte Carlo (LMC). We further demonstrate the utility of our approach by providing a tailored scheme for tuning \textit{kinetic} LMC used in SMC samplers. Our implementations are able to obtain a full \textit{schedule} of tuned parameters at the cost of a few vanilla SMC runs, which is a fraction of gradient-based approaches.
Tuning-free coreset Markov chain Monte Carlo
Oct 24, 2024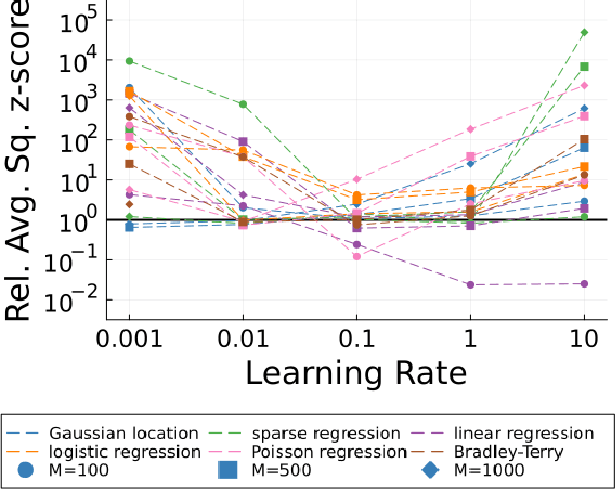


A Bayesian coreset is a small, weighted subset of a data set that replaces the full data during inference to reduce computational cost. The state-of-the-art coreset construction algorithm, Coreset Markov chain Monte Carlo (Coreset MCMC), uses draws from an adaptive Markov chain targeting the coreset posterior to train the coreset weights via stochastic gradient optimization. However, the quality of the constructed coreset, and thus the quality of its posterior approximation, is sensitive to the stochastic optimization learning rate. In this work, we propose a learning-rate-free stochastic gradient optimization procedure, Hot-start Distance over Gradient (Hot DoG), for training coreset weights in Coreset MCMC without user tuning effort. Empirical results demonstrate that Hot DoG provides higher quality posterior approximations than other learning-rate-free stochastic gradient methods, and performs competitively to optimally-tuned ADAM.
AutoStep: Locally adaptive involutive MCMC
Oct 24, 2024



Many common Markov chain Monte Carlo (MCMC) kernels can be formulated using a deterministic involutive proposal with a step size parameter. Selecting an appropriate step size is often a challenging task in practice; and for complex multiscale targets, there may not be one choice of step size that works well globally. In this work, we address this problem with a novel class of involutive MCMC methods -- AutoStep MCMC -- that selects an appropriate step size at each iteration adapted to the local geometry of the target distribution. We prove that AutoStep MCMC is $\pi$-invariant and has other desirable properties under mild assumptions on the target distribution $\pi$ and involutive proposal. Empirical results examine the effect of various step size selection design choices, and show that AutoStep MCMC is competitive with state-of-the-art methods in terms of effective sample size per unit cost on a range of challenging target distributions.
General bounds on the quality of Bayesian coresets
May 20, 2024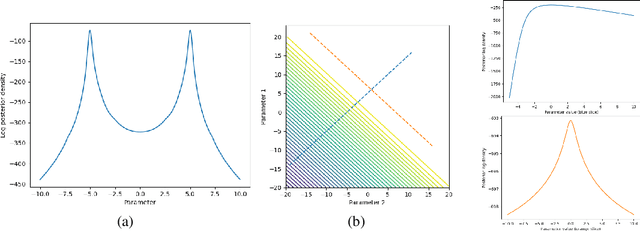
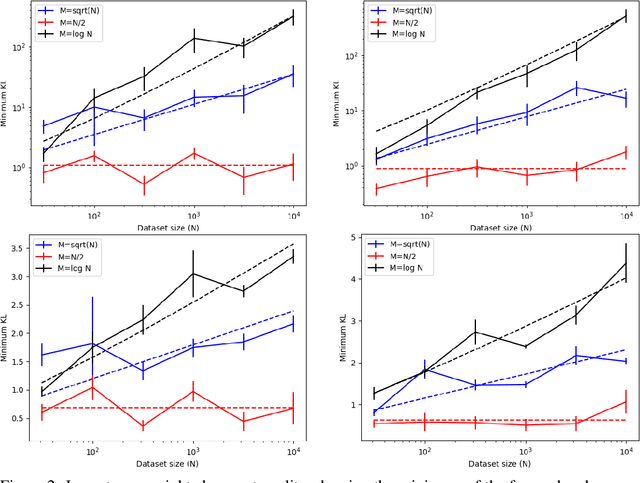
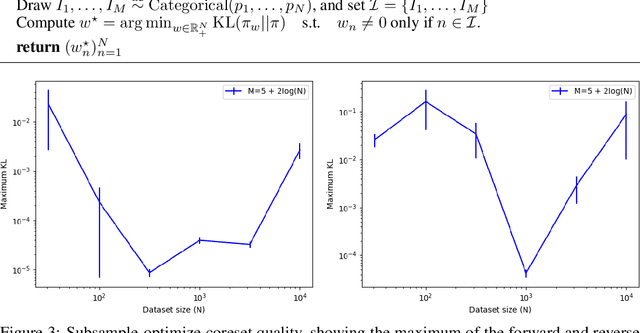
Bayesian coresets speed up posterior inference in the large-scale data regime by approximating the full-data log-likelihood function with a surrogate log-likelihood based on a small, weighted subset of the data. But while Bayesian coresets and methods for construction are applicable in a wide range of models, existing theoretical analysis of the posterior inferential error incurred by coreset approximations only apply in restrictive settings -- i.e., exponential family models, or models with strong log-concavity and smoothness assumptions. This work presents general upper and lower bounds on the Kullback-Leibler (KL) divergence of coreset approximations that reflect the full range of applicability of Bayesian coresets. The lower bounds require only mild model assumptions typical of Bayesian asymptotic analyses, while the upper bounds require the log-likelihood functions to satisfy a generalized subexponentiality criterion that is weaker than conditions used in earlier work. The lower bounds are applied to obtain fundamental limitations on the quality of coreset approximations, and to provide a theoretical explanation for the previously-observed poor empirical performance of importance sampling-based construction methods. The upper bounds are used to analyze the performance of recent subsample-optimize methods. The flexibility of the theory is demonstrated in validation experiments involving multimodal, unidentifiable, heavy-tailed Bayesian posterior distributions.
MCMC-driven learning
Feb 14, 2024



This paper is intended to appear as a chapter for the Handbook of Markov Chain Monte Carlo. The goal of this chapter is to unify various problems at the intersection of Markov chain Monte Carlo (MCMC) and machine learning$\unicode{x2014}$which includes black-box variational inference, adaptive MCMC, normalizing flow construction and transport-assisted MCMC, surrogate-likelihood MCMC, coreset construction for MCMC with big data, Markov chain gradient descent, Markovian score climbing, and more$\unicode{x2014}$within one common framework. By doing so, the theory and methods developed for each may be translated and generalized.
Coreset Markov Chain Monte Carlo
Oct 25, 2023
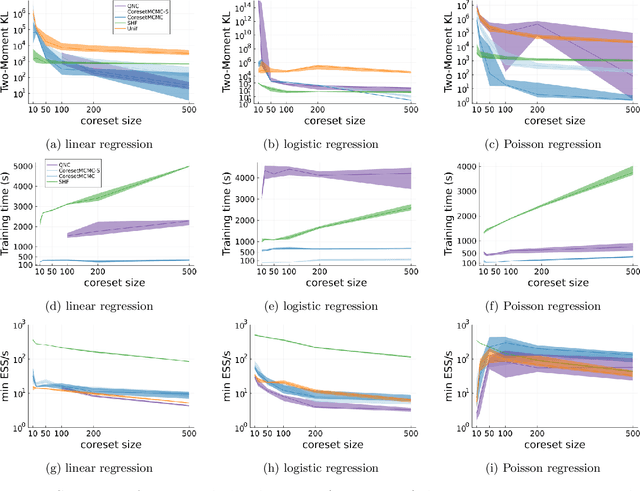
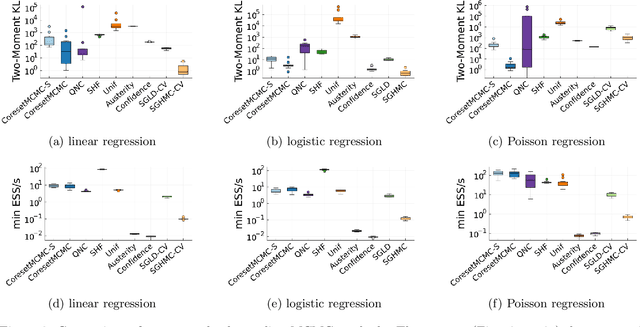
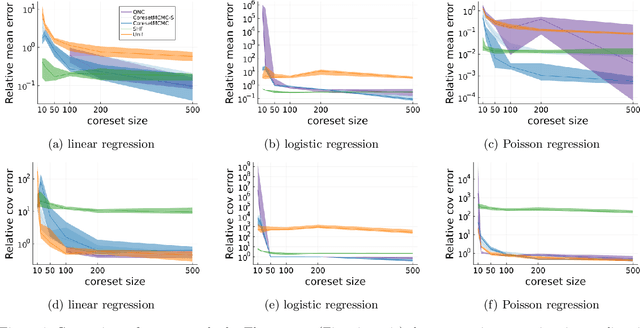
A Bayesian coreset is a small, weighted subset of data that replaces the full dataset during inference in order to reduce computational cost. However, state of the art methods for tuning coreset weights are expensive, require nontrivial user input, and impose constraints on the model. In this work, we propose a new method -- Coreset MCMC -- that simulates a Markov chain targeting the coreset posterior, while simultaneously updating the coreset weights using those same draws. Coreset MCMC is simple to implement and tune, and can be used with any existing MCMC kernel. We analyze Coreset MCMC in a representative setting to obtain key insights about the convergence behaviour of the method. Empirical results demonstrate that Coreset MCMC provides higher quality posterior approximations and reduced computational cost compared with other coreset construction methods. Further, compared with other general subsampling MCMC methods, we find that Coreset MCMC has a higher sampling efficiency with competitively accurate posterior approximations.
Mixed Variational Flows for Discrete Variables
Aug 29, 2023
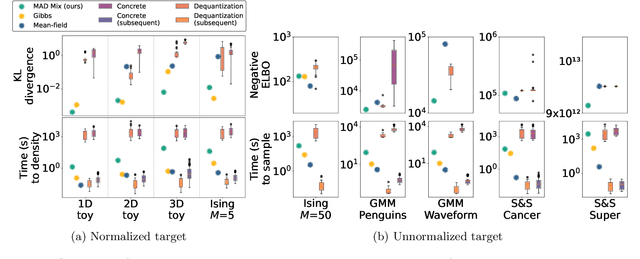

Variational flows allow practitioners to learn complex continuous distributions, but approximating discrete distributions remains a challenge. Current methodologies typically embed the discrete target in a continuous space - usually via continuous relaxation or dequantization - and then apply a continuous flow. These approaches involve a surrogate target that may not capture the original discrete target, might have biased or unstable gradients, and can create a difficult optimization problem. In this work, we develop a variational flow family for discrete distributions without any continuous embedding. First, we develop a measure-preserving and discrete (MAD) invertible map that leaves the discrete target invariant, and then create a mixed variational flow (MAD Mix) based on that map. We also develop an extension to MAD Mix that handles joint discrete and continuous models. Our experiments suggest that MAD Mix produces more reliable approximations than continuous-embedding flows while being significantly faster to train.
Embracing the chaos: analysis and diagnosis of numerical instability in variational flows
Jul 12, 2023



In this paper, we investigate the impact of numerical instability on the reliability of sampling, density evaluation, and evidence lower bound (ELBO) estimation in variational flows. We first empirically demonstrate that common flows can exhibit a catastrophic accumulation of error: the numerical flow map deviates significantly from the exact map -- which affects sampling -- and the numerical inverse flow map does not accurately recover the initial input -- which affects density and ELBO computations. Surprisingly though, we find that results produced by flows are often accurate enough for applications despite the presence of serious numerical instability. In this work, we treat variational flows as dynamical systems, and leverage shadowing theory to elucidate this behavior via theoretical guarantees on the error of sampling, density evaluation, and ELBO estimation. Finally, we develop and empirically test a diagnostic procedure that can be used to validate results produced by numerically unstable flows in practice.