 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale empirical tuning and comparison of default optimizers for variational inference
Jun 05, 2026Black-box variational inference (BBVI) is a methodology for posterior approximation that relies on stochastic optimization. In practice, the stochastic optimizers underpinning BBVI generally require extensive problem-specific tuning, which undermines its promise as a truly "black box" inference algorithm. However, over the past decade, many new adaptive stochastic optimization algorithms have been developed that reduce or remove entirely the need for tuning. In this work, we investigate this new collection of adaptive methods in the context of BBVI, with the goal of establishing the current state of the art in tuning-free optimization-based inference. In particular, we present a large-scale empirical evaluation of 56 stochastic gradient-based optimization algorithms applied to 1092 Bayesian inference optimization problems, involving over 550,000 individual optimization runs and 15 core-years of compute. The optimization algorithms we evaluate are chosen to represent a wide spectrum of recent approaches and the benchmark problems are chosen to span a range of difficulty, with posterior target dimension 1-10^4, condition number 1-10^8, and a range of variational families. Our results show that no single method dominates, but running a selection of 5 algorithms suffices to reliably get close to the best-possible observed performance. We thus provide a strong baseline for applications where expert tuning is not possible and for comparison when developing new stochastic optimization algorithms.
A Theoretical Comparison of No-U-Turn Sampler Variants: Necessary and Su?cient Convergence Conditions and Mixing Time Analysis under Gaussian Targets
Mar 19, 2026The No-U-Turn Sampler (NUTS) is the computational workhorse of modern Bayesian software libraries, yet its qualitative and quantitative convergence guarantees were established only recently. A significant gap remains in the theoretical comparison of its two main variants: NUTS-mul and NUTS-BPS, which use multinomial sampling and biased progressive sampling, respectively, for index selection. In this paper, we address this gap in three contributions. First, we derive the first necessary conditions for geometric ergodicity for both variants. Second, we establish the first sufficient conditions for geometric ergodicity and ergodicity for NUTS-mul. Third, we obtain the first mixing time result for NUTS-BPS on a standard Gaussian distribution. Our results show that NUTS-mul and NUTS-BPS exhibit nearly identical qualitative behavior, with geometric ergodicity depending on the tail properties of the target distribution. However, they differ quantitatively in their convergence rates. More precisely, when initialized in the typical set of the canonical Gaussian measure, the mixing times of both NUTS-mul and NUTS-BPS scale as $O(d^{1/4})$ up to logarithmic factors, where $d$ denotes the dimension. Nevertheless, the associated constants are strictly smaller for NUTS-BPS.
Purely Agentic Black-Box Optimization for Biological Design
Jan 29, 2026Many key challenges in biological design-such as small-molecule drug discovery, antimicrobial peptide development, and protein engineering-can be framed as black-box optimization over vast, complex structured spaces. Existing methods rely mainly on raw structural data and struggle to exploit the rich scientific literature. While large language models (LLMs) have been added to these pipelines, they have been confined to narrow roles within structure-centered optimizers. We instead cast biological black-box optimization as a fully agentic, language-based reasoning process. We introduce Purely Agentic BLack-box Optimization (PABLO), a hierarchical agentic system that uses scientific LLMs pretrained on chemistry and biology literature to generate and iteratively refine biological candidates. On both the standard GuacaMol molecular design and antimicrobial peptide optimization tasks, PABLO achieves state-of-the-art performance, substantially improving sample efficiency and final objective values over established baselines. Compared to prior optimization methods that incorporate LLMs, PABLO achieves competitive token usage per run despite relying on LLMs throughout the optimization loop. Beyond raw performance, the agentic formulation offers key advantages for realistic design: it naturally incorporates semantic task descriptions, retrieval-augmented domain knowledge, and complex constraints. In follow-up in vitro validation, PABLO-optimized peptides showed strong activity against drug-resistant pathogens, underscoring the practical potential of PABLO for therapeutic discovery.
Nearly Dimension-Independent Convergence of Mean-Field Black-Box Variational Inference
May 27, 2025We prove that, given a mean-field location-scale variational family, black-box variational inference (BBVI) with the reparametrization gradient converges at an almost dimension-independent rate. Specifically, for strongly log-concave and log-smooth targets, the number of iterations for BBVI with a sub-Gaussian family to achieve an objective $\epsilon$-close to the global optimum is $\mathrm{O}(\log d)$, which improves over the $\mathrm{O}(d)$ dependence of full-rank location-scale families. For heavy-tailed families, we provide a weaker $\mathrm{O}(d^{2/k})$ dimension dependence, where $k$ is the number of finite moments. Additionally, if the Hessian of the target log-density is constant, the complexity is free of any explicit dimension dependence. We also prove that our bound on the gradient variance, which is key to our result, cannot be improved using only spectral bounds on the Hessian of the target log-density.
Tuning Sequential Monte Carlo Samplers via Greedy Incremental Divergence Minimization
Mar 19, 2025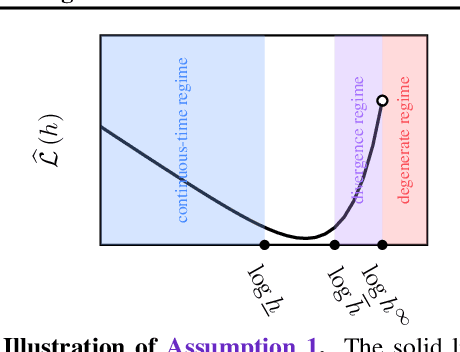

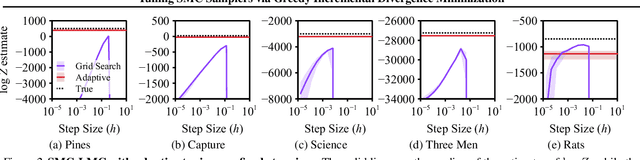
The performance of sequential Monte Carlo (SMC) samplers heavily depends on the tuning of the Markov kernels used in the path proposal. For SMC samplers with unadjusted Markov kernels, standard tuning objectives, such as the Metropolis-Hastings acceptance rate or the expected-squared jump distance, are no longer applicable. While stochastic gradient-based end-to-end optimization has been explored for tuning SMC samplers, they often incur excessive training costs, even for tuning just the kernel step sizes. In this work, we propose a general adaptation framework for tuning the Markov kernels in SMC samplers by minimizing the incremental Kullback-Leibler (KL) divergence between the proposal and target paths. For step size tuning, we provide a gradient- and tuning-free algorithm that is generally applicable for kernels such as Langevin Monte Carlo (LMC). We further demonstrate the utility of our approach by providing a tailored scheme for tuning \textit{kinetic} LMC used in SMC samplers. Our implementations are able to obtain a full \textit{schedule} of tuned parameters at the cost of a few vanilla SMC runs, which is a fraction of gradient-based approaches.
Personalized Convolutional Dictionary Learning of Physiological Time Series
Mar 10, 2025Human physiological signals tend to exhibit both global and local structures: the former are shared across a population, while the latter reflect inter-individual variability. For instance, kinetic measurements of the gait cycle during locomotion present common characteristics, although idiosyncrasies may be observed due to biomechanical disposition or pathology. To better represent datasets with local-global structure, this work extends Convolutional Dictionary Learning (CDL), a popular method for learning interpretable representations, or dictionaries, of time-series data. In particular, we propose Personalized CDL (PerCDL), in which a local dictionary models local information as a personalized spatiotemporal transformation of a global dictionary. The transformation is learnable and can combine operations such as time warping and rotation. Formal computational and statistical guarantees for PerCDL are provided and its effectiveness on synthetic and real human locomotion data is demonstrated.
Covering Multiple Objectives with a Small Set of Solutions Using Bayesian Optimization
Jan 31, 2025In multi-objective black-box optimization, the goal is typically to find solutions that optimize a set of T black-box objective functions, $f_1$, ..., $f_T$, simultaneously. Traditional approaches often seek a single Pareto-optimal set that balances trade-offs among all objectives. In this work, we introduce a novel problem setting that departs from this paradigm: finding a smaller set of K solutions, where K < T, that collectively "covers" the T objectives. A set of solutions is defined as "covering" if, for each objective $f_1$, ..., $f_T$, there is at least one good solution. A motivating example for this problem setting occurs in drug design. For example, we may have T pathogens and aim to identify a set of K < T antibiotics such that at least one antibiotic can be used to treat each pathogen. To address this problem, we propose Multi-Objective Coverage Bayesian Optimization (MOCOBO), a principled algorithm designed to efficiently find a covering set. We validate our approach through extensive experiments on challenging high-dimensional tasks, including applications in peptide and molecular design. Experiments demonstrate MOCOBO's ability to find high-performing covering sets of solutions. Additionally, we show that the small sets of K < T solutions found by MOCOBO can match or nearly match the performance of T individually optimized solutions for the same objectives. Our results highlight MOCOBO's potential to tackle complex multi-objective problems in domains where finding at least one high-performing solution for each objective is critical.
Fully Bayesian Wideband Direction-of-Arrival Estimation and Detection via RJMCMC
Dec 12, 2024



We propose a fully Bayesian approach to wideband, or broadband, direction-of-arrival (DoA) estimation and signal detection. Unlike previous works in wideband DoA estimation and detection, where the signals were modeled in the time-frequency domain, we directly model the time-domain representation and treat the non-causal part of the source signal as latent variables. Furthermore, our Bayesian model allows for closed-form marginalization of the latent source signals by leveraging conjugacy. To further speed up computation, we exploit the sparse ``stripe matrix structure'' of the considered system, which stems from the circulant matrix representation of linear time-invariant (LTI) systems. This drastically reduces the time complexity of computing the likelihood from $\mathcal{O}(N^3 k^3)$ to $\mathcal{O}(N k^3)$, where $N$ is the number of samples received by the array and $k$ is the number of sources. These computational improvements allow for efficient posterior inference through reversible jump Markov chain Monte Carlo (RJMCMC). We use the non-reversible extension of RJMCMC (NRJMCMC), which often achieves lower autocorrelation and faster convergence than the conventional reversible variant. Detection, estimation, and reconstruction of the latent source signals can then all be performed in a fully Bayesian manner through the samples drawn using NRJMCMC. We evaluate the detection performance of the procedure by comparing against generalized likelihood ratio testing (GLRT) and information criteria.
Approximation-Aware Bayesian Optimization
Jun 06, 2024High-dimensional Bayesian optimization (BO) tasks such as molecular design often require 10,000 function evaluations before obtaining meaningful results. While methods like sparse variational Gaussian processes (SVGPs) reduce computational requirements in these settings, the underlying approximations result in suboptimal data acquisitions that slow the progress of optimization. In this paper we modify SVGPs to better align with the goals of BO: targeting informed data acquisition rather than global posterior fidelity. Using the framework of utility-calibrated variational inference, we unify GP approximation and data acquisition into a joint optimization problem, thereby ensuring optimal decisions under a limited computational budget. Our approach can be used with any decision-theoretic acquisition function and is compatible with trust region methods like TuRBO. We derive efficient joint objectives for the expected improvement and knowledge gradient acquisition functions in both the standard and batch BO settings. Our approach outperforms standard SVGPs on high-dimensional benchmark tasks in control and molecular design.
Demystifying SGD with Doubly Stochastic Gradients
Jun 03, 2024Optimization objectives in the form of a sum of intractable expectations are rising in importance (e.g., diffusion models, variational autoencoders, and many more), a setting also known as "finite sum with infinite data." For these problems, a popular strategy is to employ SGD with doubly stochastic gradients (doubly SGD): the expectations are estimated using the gradient estimator of each component, while the sum is estimated by subsampling over these estimators. Despite its popularity, little is known about the convergence properties of doubly SGD, except under strong assumptions such as bounded variance. In this work, we establish the convergence of doubly SGD with independent minibatching and random reshuffling under general conditions, which encompasses dependent component gradient estimators. In particular, for dependent estimators, our analysis allows fined-grained analysis of the effect correlations. As a result, under a per-iteration computational budget of $b \times m$, where $b$ is the minibatch size and $m$ is the number of Monte Carlo samples, our analysis suggests where one should invest most of the budget in general. Furthermore, we prove that random reshuffling (RR) improves the complexity dependence on the subsampling noise.