 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Test-Time Guidance Is Enough: Fast Image and Video Editing with Diffusion Guidance
Feb 15, 2026Text-driven image and video editing can be naturally cast as inpainting problems, where masked regions are reconstructed to remain consistent with both the observed content and the editing prompt. Recent advances in test-time guidance for diffusion and flow models provide a principled framework for this task; however, existing methods rely on costly vector--Jacobian product (VJP) computations to approximate the intractable guidance term, limiting their practical applicability. Building upon the recent work of Moufad et al. (2025), we provide theoretical insights into their VJP-free approximation and substantially extend their empirical evaluation to large-scale image and video editing benchmarks. Our results demonstrate that test-time guidance alone can achieve performance comparable to, and in some cases surpass, training-based methods.
Efficient Zero-Shot Inpainting with Decoupled Diffusion Guidance
Dec 20, 2025Diffusion models have emerged as powerful priors for image editing tasks such as inpainting and local modification, where the objective is to generate realistic content that remains consistent with observed regions. In particular, zero-shot approaches that leverage a pretrained diffusion model, without any retraining, have been shown to achieve highly effective reconstructions. However, state-of-the-art zero-shot methods typically rely on a sequence of surrogate likelihood functions, whose scores are used as proxies for the ideal score. This procedure however requires vector-Jacobian products through the denoiser at every reverse step, introducing significant memory and runtime overhead. To address this issue, we propose a new likelihood surrogate that yields simple and efficient to sample Gaussian posterior transitions, sidestepping the backpropagation through the denoiser network. Our extensive experiments show that our method achieves strong observation consistency compared with fine-tuned baselines and produces coherent, high-quality reconstructions, all while significantly reducing inference cost. Code is available at https://github.com/YazidJanati/ding.
Learned Reference-based Diffusion Sampling for multi-modal distributions
Oct 25, 2024



Over the past few years, several approaches utilizing score-based diffusion have been proposed to sample from probability distributions, that is without having access to exact samples and relying solely on evaluations of unnormalized densities. The resulting samplers approximate the time-reversal of a noising diffusion process, bridging the target distribution to an easy-to-sample base distribution. In practice, the performance of these methods heavily depends on key hyperparameters that require ground truth samples to be accurately tuned. Our work aims to highlight and address this fundamental issue, focusing in particular on multi-modal distributions, which pose significant challenges for existing sampling methods. Building on existing approaches, we introduce Learned Reference-based Diffusion Sampler (LRDS), a methodology specifically designed to leverage prior knowledge on the location of the target modes in order to bypass the obstacle of hyperparameter tuning. LRDS proceeds in two steps by (i) learning a reference diffusion model on samples located in high-density space regions and tailored for multimodality, and (ii) using this reference model to foster the training of a diffusion-based sampler. We experimentally demonstrate that LRDS best exploits prior knowledge on the target distribution compared to competing algorithms on a variety of challenging distributions.
Stochastic Approximation with Biased MCMC for Expectation Maximization
Feb 27, 2024
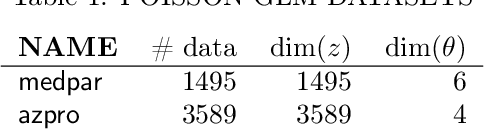


The expectation maximization (EM) algorithm is a widespread method for empirical Bayesian inference, but its expectation step (E-step) is often intractable. Employing a stochastic approximation scheme with Markov chain Monte Carlo (MCMC) can circumvent this issue, resulting in an algorithm known as MCMC-SAEM. While theoretical guarantees for MCMC-SAEM have previously been established, these results are restricted to the case where asymptotically unbiased MCMC algorithms are used. In practice, MCMC-SAEM is often run with asymptotically biased MCMC, for which the consequences are theoretically less understood. In this work, we fill this gap by analyzing the asymptotics and non-asymptotics of SAEM with biased MCMC steps, particularly the effect of bias. We also provide numerical experiments comparing the Metropolis-adjusted Langevin algorithm (MALA), which is asymptotically unbiased, and the unadjusted Langevin algorithm (ULA), which is asymptotically biased, on synthetic and real datasets. Experimental results show that ULA is more stable with respect to the choice of Langevin stepsize and can sometimes result in faster convergence.
Stochastic Localization via Iterative Posterior Sampling
Feb 16, 2024Building upon score-based learning, new interest in stochastic localization techniques has recently emerged. In these models, one seeks to noise a sample from the data distribution through a stochastic process, called observation process, and progressively learns a denoiser associated to this dynamics. Apart from specific applications, the use of stochastic localization for the problem of sampling from an unnormalized target density has not been explored extensively. This work contributes to fill this gap. We consider a general stochastic localization framework and introduce an explicit class of observation processes, associated with flexible denoising schedules. We provide a complete methodology, $\textit{Stochastic Localization via Iterative Posterior Sampling}$ (SLIPS), to obtain approximate samples of this dynamics, and as a by-product, samples from the target distribution. Our scheme is based on a Markov chain Monte Carlo estimation of the denoiser and comes with detailed practical guidelines. We illustrate the benefits and applicability of SLIPS on several benchmarks, including Gaussian mixtures in increasing dimensions, Bayesian logistic regression and a high-dimensional field system from statistical-mechanics.