 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Gradient for Preference Learning
Jan 29, 2026The knowledge gradient is a popular acquisition function in Bayesian optimization (BO) for optimizing black-box objectives with noisy function evaluations. Many practical settings, however, allow only pairwise comparison queries, yielding a preferential BO problem where direct function evaluations are unavailable. Extending the knowledge gradient to preferential BO is hindered by its computational challenge. At its core, the look-ahead step in the preferential setting requires computing a non-Gaussian posterior, which was previously considered intractable. In this paper, we address this challenge by deriving an exact and analytical knowledge gradient for preferential BO. We show that the exact knowledge gradient performs strongly on a suite of benchmark problems, often outperforming existing acquisition functions. In addition, we also present a case study illustrating the limitation of the knowledge gradient in certain scenarios.
Purely Agentic Black-Box Optimization for Biological Design
Jan 29, 2026Many key challenges in biological design-such as small-molecule drug discovery, antimicrobial peptide development, and protein engineering-can be framed as black-box optimization over vast, complex structured spaces. Existing methods rely mainly on raw structural data and struggle to exploit the rich scientific literature. While large language models (LLMs) have been added to these pipelines, they have been confined to narrow roles within structure-centered optimizers. We instead cast biological black-box optimization as a fully agentic, language-based reasoning process. We introduce Purely Agentic BLack-box Optimization (PABLO), a hierarchical agentic system that uses scientific LLMs pretrained on chemistry and biology literature to generate and iteratively refine biological candidates. On both the standard GuacaMol molecular design and antimicrobial peptide optimization tasks, PABLO achieves state-of-the-art performance, substantially improving sample efficiency and final objective values over established baselines. Compared to prior optimization methods that incorporate LLMs, PABLO achieves competitive token usage per run despite relying on LLMs throughout the optimization loop. Beyond raw performance, the agentic formulation offers key advantages for realistic design: it naturally incorporates semantic task descriptions, retrieval-augmented domain knowledge, and complex constraints. In follow-up in vitro validation, PABLO-optimized peptides showed strong activity against drug-resistant pathogens, underscoring the practical potential of PABLO for therapeutic discovery.
A Dataset for Distilling Knowledge Priors from Literature for Therapeutic Design
Aug 14, 2025AI-driven discovery can greatly reduce design time and enhance new therapeutics' effectiveness. Models using simulators explore broad design spaces but risk violating implicit constraints due to a lack of experimental priors. For example, in a new analysis we performed on a diverse set of models on the GuacaMol benchmark using supervised classifiers, over 60\% of molecules proposed had high probability of being mutagenic. In this work, we introduce \ourdataset, a dataset of priors for design problems extracted from literature describing compounds used in lab settings. It is constructed with LLM pipelines for discovering therapeutic entities in relevant paragraphs and summarizing information in concise fair-use facts. \ourdataset~ consists of 32.3 million pairs of natural language facts, and appropriate entity representations (i.e. SMILES or refseq IDs). To demonstrate the potential of the data, we train LLM, CLIP, and LLava architectures to reason jointly about text and design targets and evaluate on tasks from the Therapeutic Data Commons (TDC). \ourdataset~is highly effective for creating models with strong priors: in supervised prediction problems that use our data as pretraining, our best models with 15M learnable parameters outperform larger 2B TxGemma on both regression and classification TDC tasks, and perform comparably to 9B models on average. Models built with \ourdataset~can be used as constraints while optimizing for novel molecules in GuacaMol, resulting in proposals that are safer and nearly as effective. We release our dataset at \href{https://huggingface.co/datasets/medexanon/Medex}{huggingface.co/datasets/medexanon/Medex}, and will provide expanded versions as available literature grows.
Nearly Dimension-Independent Convergence of Mean-Field Black-Box Variational Inference
May 27, 2025We prove that, given a mean-field location-scale variational family, black-box variational inference (BBVI) with the reparametrization gradient converges at an almost dimension-independent rate. Specifically, for strongly log-concave and log-smooth targets, the number of iterations for BBVI with a sub-Gaussian family to achieve an objective $\epsilon$-close to the global optimum is $\mathrm{O}(\log d)$, which improves over the $\mathrm{O}(d)$ dependence of full-rank location-scale families. For heavy-tailed families, we provide a weaker $\mathrm{O}(d^{2/k})$ dimension dependence, where $k$ is the number of finite moments. Additionally, if the Hessian of the target log-density is constant, the complexity is free of any explicit dimension dependence. We also prove that our bound on the gradient variance, which is key to our result, cannot be improved using only spectral bounds on the Hessian of the target log-density.
Tuning Sequential Monte Carlo Samplers via Greedy Incremental Divergence Minimization
Mar 19, 2025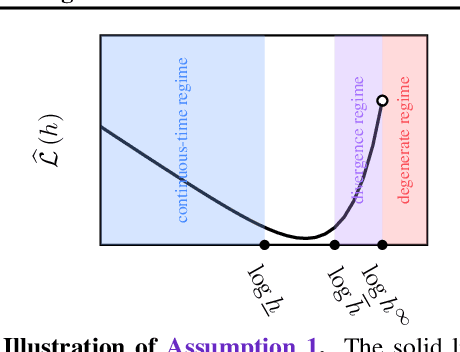

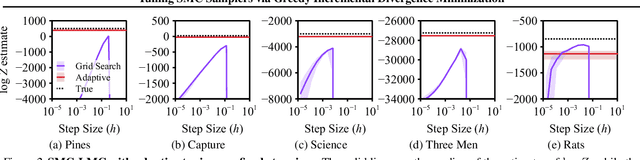
The performance of sequential Monte Carlo (SMC) samplers heavily depends on the tuning of the Markov kernels used in the path proposal. For SMC samplers with unadjusted Markov kernels, standard tuning objectives, such as the Metropolis-Hastings acceptance rate or the expected-squared jump distance, are no longer applicable. While stochastic gradient-based end-to-end optimization has been explored for tuning SMC samplers, they often incur excessive training costs, even for tuning just the kernel step sizes. In this work, we propose a general adaptation framework for tuning the Markov kernels in SMC samplers by minimizing the incremental Kullback-Leibler (KL) divergence between the proposal and target paths. For step size tuning, we provide a gradient- and tuning-free algorithm that is generally applicable for kernels such as Langevin Monte Carlo (LMC). We further demonstrate the utility of our approach by providing a tailored scheme for tuning \textit{kinetic} LMC used in SMC samplers. Our implementations are able to obtain a full \textit{schedule} of tuned parameters at the cost of a few vanilla SMC runs, which is a fraction of gradient-based approaches.
Large Scale Multi-Task Bayesian Optimization with Large Language Models
Mar 11, 2025



In multi-task Bayesian optimization, the goal is to leverage experience from optimizing existing tasks to improve the efficiency of optimizing new ones. While approaches using multi-task Gaussian processes or deep kernel transfer exist, the performance improvement is marginal when scaling to more than a moderate number of tasks. We introduce a novel approach leveraging large language models (LLMs) to learn from, and improve upon, previous optimization trajectories, scaling to approximately 2000 distinct tasks. Specifically, we propose an iterative framework in which an LLM is fine-tuned using the high quality solutions produced by BayesOpt to generate improved initializations that accelerate convergence for future optimization tasks based on previous search trajectories. We evaluate our method on two distinct domains: database query optimization and antimicrobial peptide design. Results demonstrate that our approach creates a positive feedback loop, where the LLM's generated initializations gradually improve, leading to better optimization performance. As this feedback loop continues, we find that the LLM is eventually able to generate solutions to new tasks in just a few shots that are better than the solutions produced by "from scratch" by Bayesian optimization while simultaneously requiring significantly fewer oracle calls.
Covering Multiple Objectives with a Small Set of Solutions Using Bayesian Optimization
Jan 31, 2025In multi-objective black-box optimization, the goal is typically to find solutions that optimize a set of T black-box objective functions, $f_1$, ..., $f_T$, simultaneously. Traditional approaches often seek a single Pareto-optimal set that balances trade-offs among all objectives. In this work, we introduce a novel problem setting that departs from this paradigm: finding a smaller set of K solutions, where K < T, that collectively "covers" the T objectives. A set of solutions is defined as "covering" if, for each objective $f_1$, ..., $f_T$, there is at least one good solution. A motivating example for this problem setting occurs in drug design. For example, we may have T pathogens and aim to identify a set of K < T antibiotics such that at least one antibiotic can be used to treat each pathogen. To address this problem, we propose Multi-Objective Coverage Bayesian Optimization (MOCOBO), a principled algorithm designed to efficiently find a covering set. We validate our approach through extensive experiments on challenging high-dimensional tasks, including applications in peptide and molecular design. Experiments demonstrate MOCOBO's ability to find high-performing covering sets of solutions. Additionally, we show that the small sets of K < T solutions found by MOCOBO can match or nearly match the performance of T individually optimized solutions for the same objectives. Our results highlight MOCOBO's potential to tackle complex multi-objective problems in domains where finding at least one high-performing solution for each objective is critical.
Computation-Aware Gaussian Processes: Model Selection And Linear-Time Inference
Nov 01, 2024



Model selection in Gaussian processes scales prohibitively with the size of the training dataset, both in time and memory. While many approximations exist, all incur inevitable approximation error. Recent work accounts for this error in the form of computational uncertainty, which enables -- at the cost of quadratic complexity -- an explicit tradeoff between computation and precision. Here we extend this development to model selection, which requires significant enhancements to the existing approach, including linear-time scaling in the size of the dataset. We propose a novel training loss for hyperparameter optimization and demonstrate empirically that the resulting method can outperform SGPR, CGGP and SVGP, state-of-the-art methods for GP model selection, on medium to large-scale datasets. Our experiments show that model selection for computation-aware GPs trained on 1.8 million data points can be done within a few hours on a single GPU. As a result of this work, Gaussian processes can be trained on large-scale datasets without significantly compromising their ability to quantify uncertainty -- a fundamental prerequisite for optimal decision-making.
A Fast, Robust Elliptical Slice Sampling Implementation for Linearly Truncated Multivariate Normal Distributions
Jul 15, 2024Elliptical slice sampling, when adapted to linearly truncated multivariate normal distributions, is a rejection-free Markov chain Monte Carlo method. At its core, it requires analytically constructing an ellipse-polytope intersection. The main novelty of this paper is an algorithm that computes this intersection in $\mathcal{O}(m \log m)$ time, where $m$ is the number of linear inequality constraints representing the polytope. We show that an implementation based on this algorithm enhances numerical stability, speeds up running time, and is easy to parallelize for launching multiple Markov chains.
Approximation-Aware Bayesian Optimization
Jun 06, 2024High-dimensional Bayesian optimization (BO) tasks such as molecular design often require 10,000 function evaluations before obtaining meaningful results. While methods like sparse variational Gaussian processes (SVGPs) reduce computational requirements in these settings, the underlying approximations result in suboptimal data acquisitions that slow the progress of optimization. In this paper we modify SVGPs to better align with the goals of BO: targeting informed data acquisition rather than global posterior fidelity. Using the framework of utility-calibrated variational inference, we unify GP approximation and data acquisition into a joint optimization problem, thereby ensuring optimal decisions under a limited computational budget. Our approach can be used with any decision-theoretic acquisition function and is compatible with trust region methods like TuRBO. We derive efficient joint objectives for the expected improvement and knowledge gradient acquisition functions in both the standard and batch BO settings. Our approach outperforms standard SVGPs on high-dimensional benchmark tasks in control and molecular design.