 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Query Synthesis via Bayesian Optimization
Mar 02, 2026Benchmark workloads are extremely important to the database management research community, especially as more machine learning components are integrated into database systems. Here, we propose a Bayesian optimization technique to automatically search for difficult benchmark queries, significantly reducing the amount of manual effort usually required. In preliminary experiments, we show that our approach can generate queries with more than double the optimization headroom compared to existing benchmarks.
Piece of CAKE: Adaptive Execution Engines via Microsecond-Scale Learning
Feb 04, 2026Low-level database operators often admit multiple physical implementations ("kernels") that are semantically equivalent but have vastly different performance characteristics depending on the input data distribution. Existing database systems typically rely on static heuristics or worst-case optimal defaults to select these kernels, often missing significant performance opportunities. In this work, we propose CAKE (Counterfactual Adaptive Kernel Execution), a system that learns to select the optimal kernel for each data "morsel" using a microsecond-scale contextual multi-armed bandit. CAKE circumvents the high latency of traditional reinforcement learning by exploiting the cheapness of counterfactuals -- selectively running multiple kernels to obtain full feedback -- and compiling policies into low-latency regret trees. Experimentally, we show that CAKE can reduce end-to-end workload latency by up to 2x compared to state-of-the-art static heuristics.
Low Rank Learning for Offline Query Optimization
Apr 08, 2025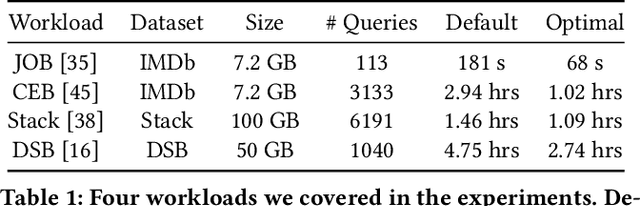
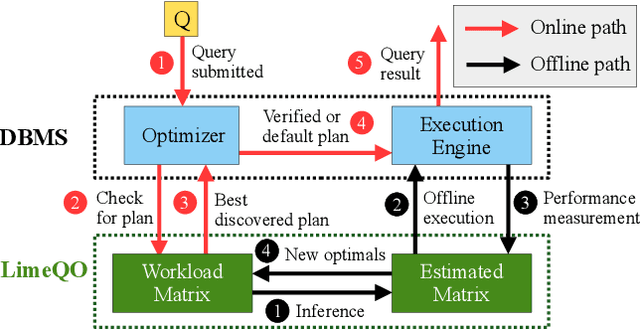
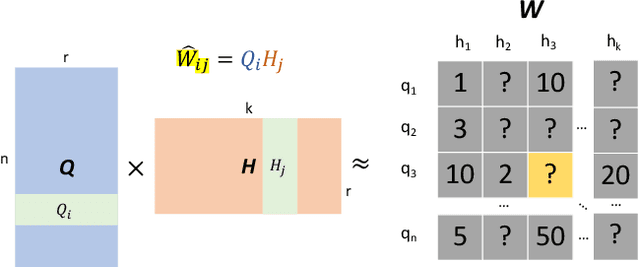
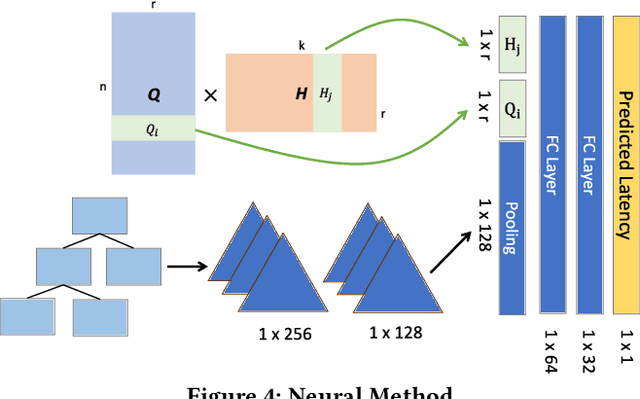
Recent deployments of learned query optimizers use expensive neural networks and ad-hoc search policies. To address these issues, we introduce \textsc{LimeQO}, a framework for offline query optimization leveraging low-rank learning to efficiently explore alternative query plans with minimal resource usage. By modeling the workload as a partially observed, low-rank matrix, we predict unobserved query plan latencies using purely linear methods, significantly reducing computational overhead compared to neural networks. We formalize offline exploration as an active learning problem, and present simple heuristics that reduces a 3-hour workload to 1.5 hours after just 1.5 hours of exploration. Additionally, we propose a transductive Tree Convolutional Neural Network (TCNN) that, despite higher computational costs, achieves the same workload reduction with only 0.5 hours of exploration. Unlike previous approaches that place expensive neural networks directly in the query processing ``hot'' path, our approach offers a low-overhead solution and a no-regressions guarantee, all without making assumptions about the underlying DBMS. The code is available in \href{https://github.com/zixy17/LimeQO}{https://github.com/zixy17/LimeQO}.
Large Scale Multi-Task Bayesian Optimization with Large Language Models
Mar 11, 2025



In multi-task Bayesian optimization, the goal is to leverage experience from optimizing existing tasks to improve the efficiency of optimizing new ones. While approaches using multi-task Gaussian processes or deep kernel transfer exist, the performance improvement is marginal when scaling to more than a moderate number of tasks. We introduce a novel approach leveraging large language models (LLMs) to learn from, and improve upon, previous optimization trajectories, scaling to approximately 2000 distinct tasks. Specifically, we propose an iterative framework in which an LLM is fine-tuned using the high quality solutions produced by BayesOpt to generate improved initializations that accelerate convergence for future optimization tasks based on previous search trajectories. We evaluate our method on two distinct domains: database query optimization and antimicrobial peptide design. Results demonstrate that our approach creates a positive feedback loop, where the LLM's generated initializations gradually improve, leading to better optimization performance. As this feedback loop continues, we find that the LLM is eventually able to generate solutions to new tasks in just a few shots that are better than the solutions produced by "from scratch" by Bayesian optimization while simultaneously requiring significantly fewer oracle calls.
The Unreasonable Effectiveness of LLMs for Query Optimization
Nov 05, 2024
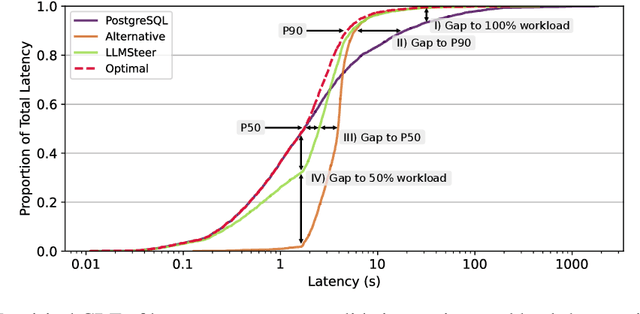
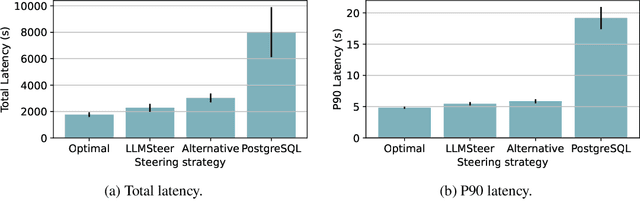
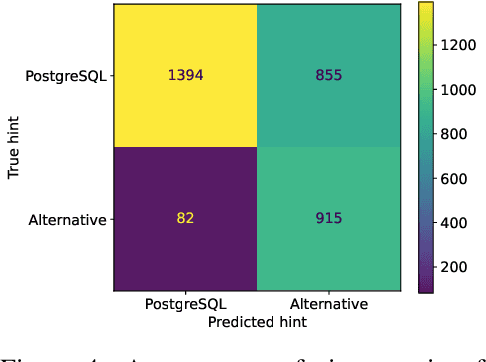
Recent work in database query optimization has used complex machine learning strategies, such as customized reinforcement learning schemes. Surprisingly, we show that LLM embeddings of query text contain useful semantic information for query optimization. Specifically, we show that a simple binary classifier deciding between alternative query plans, trained only on a small number of labeled embedded query vectors, can outperform existing heuristic systems. Although we only present some preliminary results, an LLM-powered query optimizer could provide significant benefits, both in terms of performance and simplicity.
A Practical Theory of Generalization in Selectivity Learning
Sep 11, 2024



Query-driven machine learning models have emerged as a promising estimation technique for query selectivities. Yet, surprisingly little is known about the efficacy of these techniques from a theoretical perspective, as there exist substantial gaps between practical solutions and state-of-the-art (SOTA) theory based on the Probably Approximately Correct (PAC) learning framework. In this paper, we aim to bridge the gaps between theory and practice. First, we demonstrate that selectivity predictors induced by signed measures are learnable, which relaxes the reliance on probability measures in SOTA theory. More importantly, beyond the PAC learning framework (which only allows us to characterize how the model behaves when both training and test workloads are drawn from the same distribution), we establish, under mild assumptions, that selectivity predictors from this class exhibit favorable out-of-distribution (OOD) generalization error bounds. These theoretical advances provide us with a better understanding of both the in-distribution and OOD generalization capabilities of query-driven selectivity learning, and facilitate the design of two general strategies to improve OOD generalization for existing query-driven selectivity models. We empirically verify that our techniques help query-driven selectivity models generalize significantly better to OOD queries both in terms of prediction accuracy and query latency performance, while maintaining their superior in-distribution generalization performance.
Kepler: Robust Learning for Faster Parametric Query Optimization
Jun 11, 2023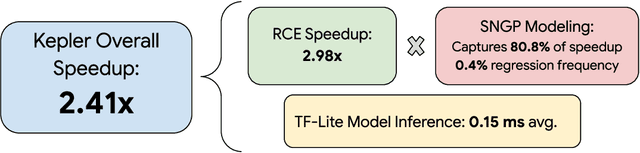

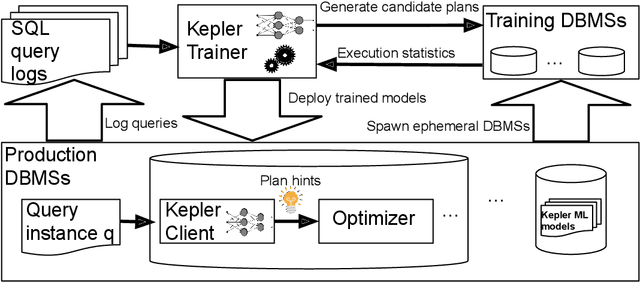
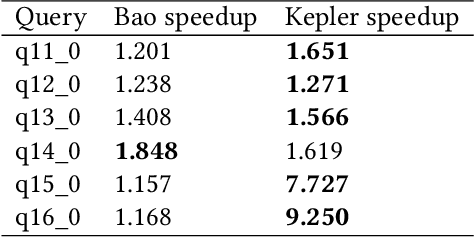
Most existing parametric query optimization (PQO) techniques rely on traditional query optimizer cost models, which are often inaccurate and result in suboptimal query performance. We propose Kepler, an end-to-end learning-based approach to PQO that demonstrates significant speedups in query latency over a traditional query optimizer. Central to our method is Row Count Evolution (RCE), a novel plan generation algorithm based on perturbations in the sub-plan cardinality space. While previous approaches require accurate cost models, we bypass this requirement by evaluating candidate plans via actual execution data and training an ML model to predict the fastest plan given parameter binding values. Our models leverage recent advances in neural network uncertainty in order to robustly predict faster plans while avoiding regressions in query performance. Experimentally, we show that Kepler achieves significant improvements in query runtime on multiple datasets on PostgreSQL.
LSI: A Learned Secondary Index Structure
May 11, 2022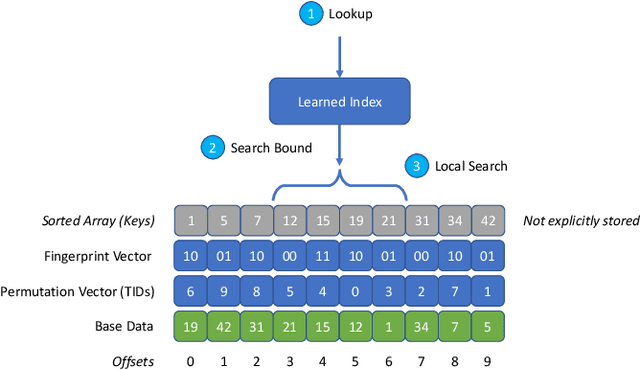
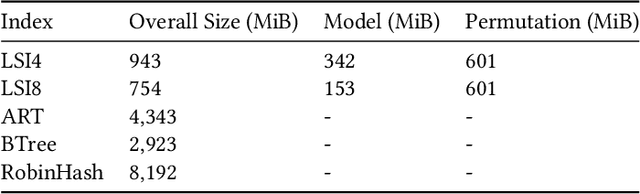
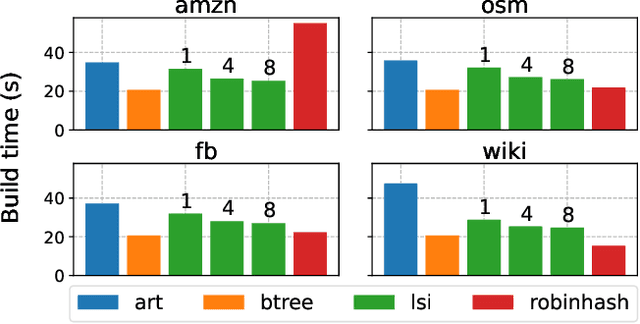
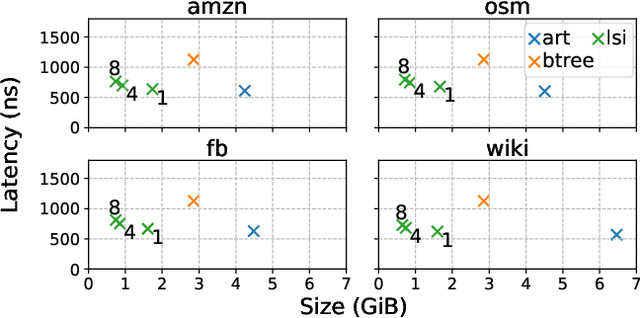
Learned index structures have been shown to achieve favorable lookup performance and space consumption compared to their traditional counterparts such as B-trees. However, most learned index studies have focused on the primary indexing setting, where the base data is sorted. In this work, we investigate whether learned indexes sustain their advantage in the secondary indexing setting. We introduce Learned Secondary Index (LSI), a first attempt to use learned indexes for indexing unsorted data. LSI works by building a learned index over a permutation vector, which allows binary search to performed on the unsorted base data using random access. We additionally augment LSI with a fingerprint vector to accelerate equality lookups. We show that LSI achieves comparable lookup performance to state-of-the-art secondary indexes while being up to 6x more space efficient.
PLEX: Towards Practical Learned Indexing
Aug 11, 2021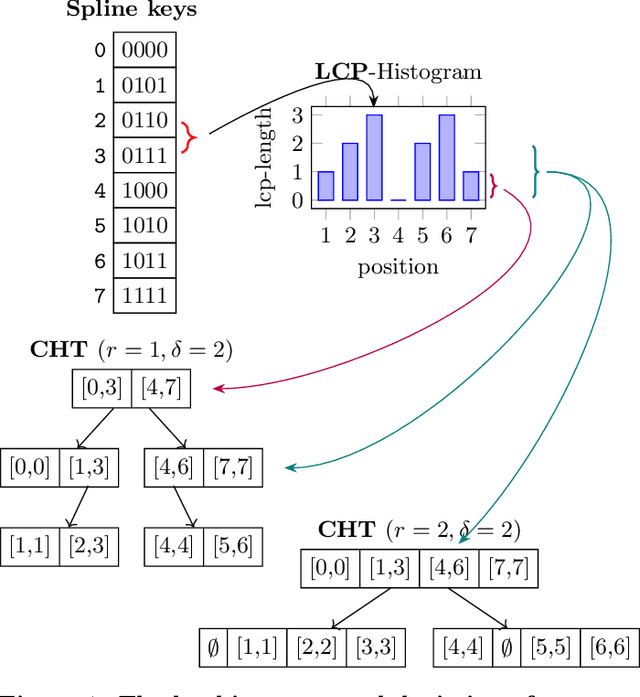
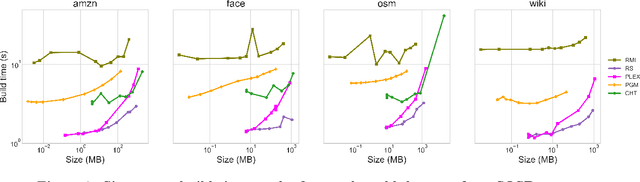
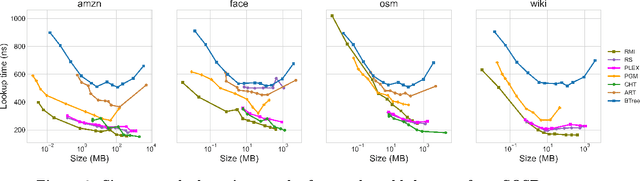
Latest research proposes to replace existing index structures with learned models. However, current learned indexes tend to have many hyperparameters, often do not provide any error guarantees, and are expensive to build. We introduce Practical Learned Index (PLEX). PLEX only has a single hyperparameter $\epsilon$ (maximum prediction error) and offers a better trade-off between build and lookup time than state-of-the-art approaches. Similar to RadixSpline, PLEX consists of a spline and a (multi-level) radix layer. It first builds a spline satisfying the given $\epsilon$ and then performs an ad-hoc analysis of the distribution of spline points to quickly tune the radix layer.
Class-Weighted Evaluation Metrics for Imbalanced Data Classification
Oct 12, 2020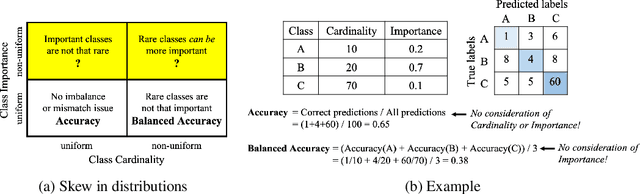
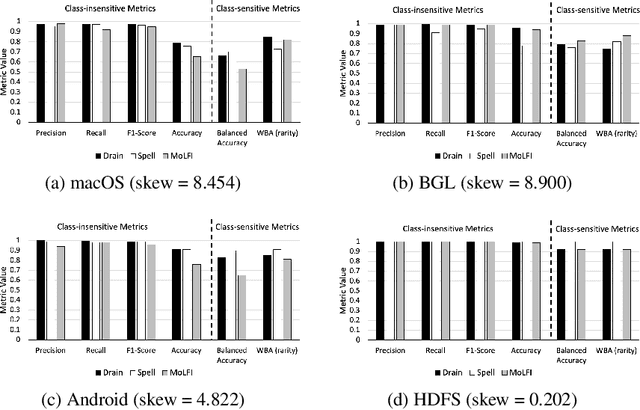
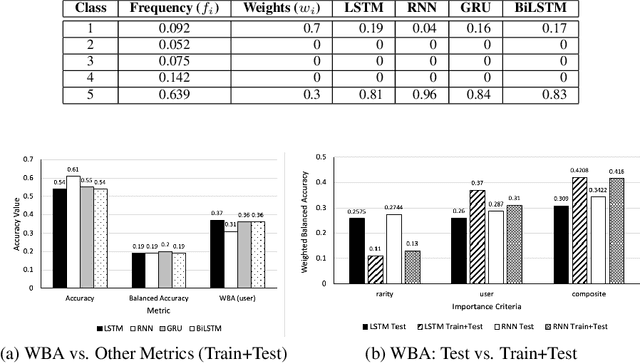
Class distribution skews in imbalanced datasets may lead to models with prediction bias towards majority classes, making fair assessment of classifiers a challenging task. Balanced Accuracy is a popular metric used to evaluate a classifier's prediction performance under such scenarios. However, this metric falls short when classes vary in importance, especially when class importance is skewed differently from class cardinality distributions. In this paper, we propose a simple and general-purpose evaluation framework for imbalanced data classification that is sensitive to arbitrary skews in class cardinalities and importances. Experiments with several state-of-the-art classifiers tested on real-world datasets and benchmarks from two different domains show that our new framework is more effective than Balanced Accuracy -- not only in evaluating and ranking model predictions, but also in training the models themselves.