 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Without Limits: Constant-Sized KV Caches for Extended Responses in LLMs
Mar 02, 2025Autoregressive Transformers rely on Key-Value (KV) caching to accelerate inference. However, the linear growth of the KV cache with context length leads to excessive memory consumption and bandwidth constraints. This bottleneck is particularly problematic in real-time applications -- such as chatbots and interactive assistants -- where low latency and high memory efficiency are critical. Existing methods drop distant tokens or compress states in a lossy manner, sacrificing accuracy by discarding vital context or introducing bias. We propose MorphKV, an inference-time technique that maintains a constant-sized KV cache while preserving accuracy. MorphKV balances long-range dependencies and local coherence during text generation. It eliminates early-token bias while retaining high-fidelity context by adaptively ranking tokens through correlation-aware selection. Unlike heuristic retention or lossy compression, MorphKV iteratively refines the KV cache via lightweight updates guided by attention patterns of recent tokens. This approach captures inter-token correlation with greater accuracy, crucial for tasks like content creation and code generation. Our studies on long-response tasks show 52.9$\%$ memory savings and 18.2$\%$ higher accuracy on average compared to state-of-the-art prior works, enabling efficient real-world deployment.
Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
Mar 14, 2024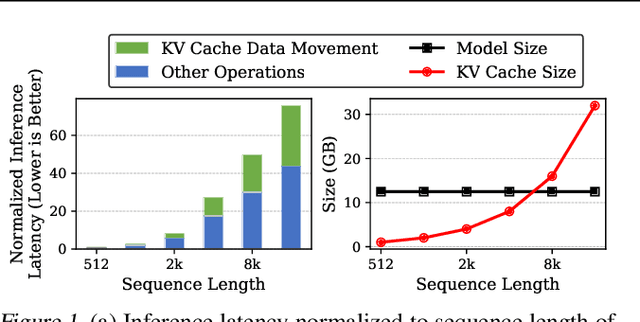

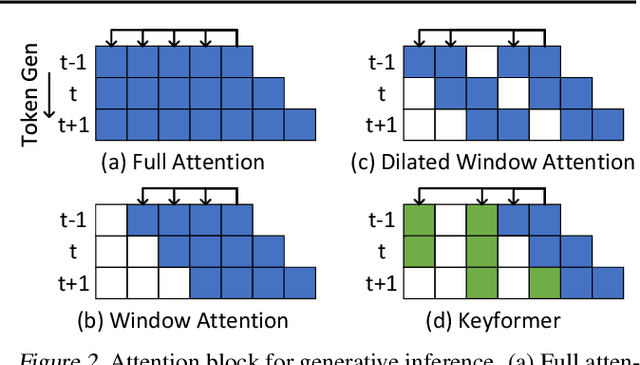
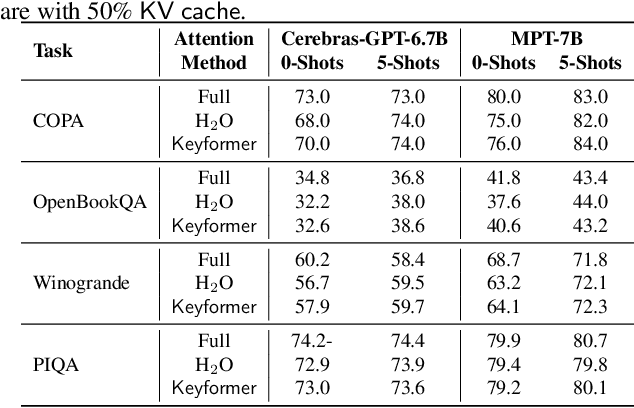
Transformers have emerged as the underpinning architecture for Large Language Models (LLMs). In generative language models, the inference process involves two primary phases: prompt processing and token generation. Token generation, which constitutes the majority of the computational workload, primarily entails vector-matrix multiplications and interactions with the Key-Value (KV) Cache. This phase is constrained by memory bandwidth due to the overhead of transferring weights and KV cache values from the memory system to the computing units. This memory bottleneck becomes particularly pronounced in applications that require long-context and extensive text generation, both of which are increasingly crucial for LLMs. This paper introduces "Keyformer", an innovative inference-time approach, to mitigate the challenges associated with KV cache size and memory bandwidth utilization. Keyformer leverages the observation that approximately 90% of the attention weight in generative inference focuses on a specific subset of tokens, referred to as "key" tokens. Keyformer retains only the key tokens in the KV cache by identifying these crucial tokens using a novel score function. This approach effectively reduces both the KV cache size and memory bandwidth usage without compromising model accuracy. We evaluate Keyformer's performance across three foundational models: GPT-J, Cerebras-GPT, and MPT, which employ various positional embedding algorithms. Our assessment encompasses a variety of tasks, with a particular emphasis on summarization and conversation tasks involving extended contexts. Keyformer's reduction of KV cache reduces inference latency by 2.1x and improves token generation throughput by 2.4x, while preserving the model's accuracy.
* A collaborative effort by d-matrix and the University of British Columbia
Kepler: Robust Learning for Faster Parametric Query Optimization
Jun 11, 2023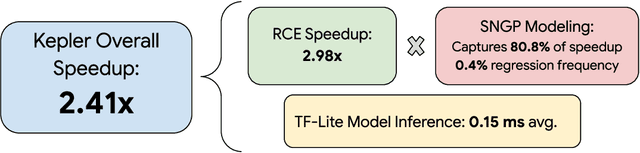

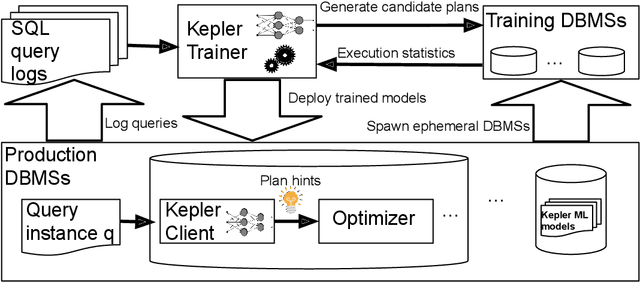
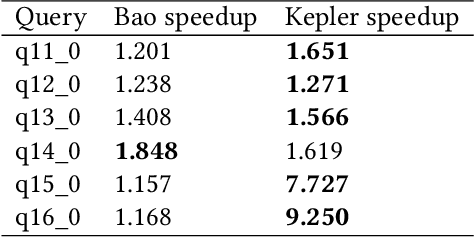
Most existing parametric query optimization (PQO) techniques rely on traditional query optimizer cost models, which are often inaccurate and result in suboptimal query performance. We propose Kepler, an end-to-end learning-based approach to PQO that demonstrates significant speedups in query latency over a traditional query optimizer. Central to our method is Row Count Evolution (RCE), a novel plan generation algorithm based on perturbations in the sub-plan cardinality space. While previous approaches require accurate cost models, we bypass this requirement by evaluating candidate plans via actual execution data and training an ML model to predict the fastest plan given parameter binding values. Our models leverage recent advances in neural network uncertainty in order to robustly predict faster plans while avoiding regressions in query performance. Experimentally, we show that Kepler achieves significant improvements in query runtime on multiple datasets on PostgreSQL.
Cinderella's shoe won't fit Soundarya: An audit of facial processing tools on Indian faces
Dec 17, 2021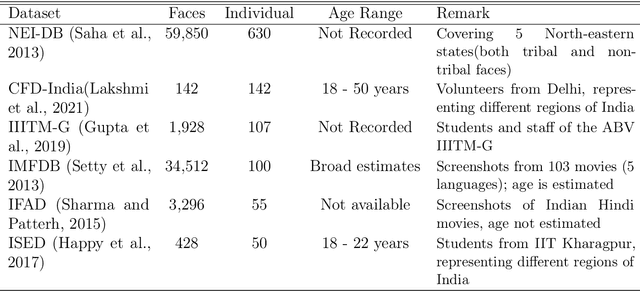

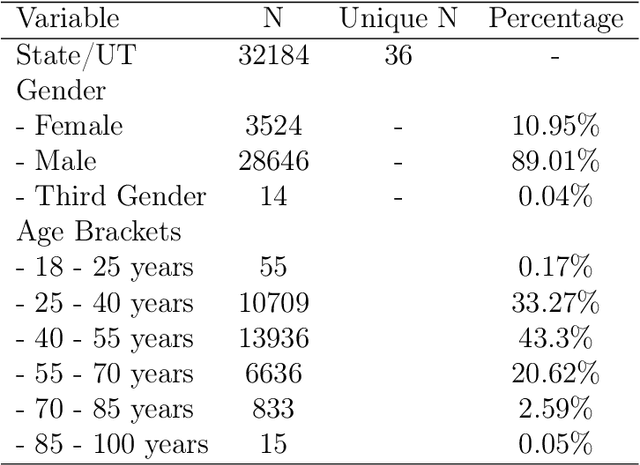

The increasing adoption of facial processing systems in India is fraught with concerns of privacy, transparency, accountability, and missing procedural safeguards. At the same time, we also know very little about how these technologies perform on the diverse features, characteristics, and skin tones of India's 1.34 billion-plus population. In this paper, we test the face detection and facial analysis functions of four commercial facial processing tools on a dataset of Indian faces. The tools display varying error rates in the face detection and gender and age classification functions. The gender classification error rate for Indian female faces is consistently higher compared to that of males -- the highest female error rate being 14.68%. In some cases, this error rate is much higher than that shown by previous studies for females of other nationalities. Age classification errors are also high. Despite taking into account an acceptable error margin of plus or minus 10 years from a person's actual age, age prediction failures are in the range of 14.3% to 42.2%. These findings point to the limited accuracy of facial processing tools, particularly for certain demographic groups, and the need for more critical thinking before adopting such systems.