 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUntied Ulysses: Memory-Efficient Context Parallelism via Headwise Chunking
Feb 24, 2026Efficiently processing long sequences with Transformer models usually requires splitting the computations across accelerators via context parallelism. The dominant approaches in this family of methods, such as Ring Attention or DeepSpeed Ulysses, enable scaling over the context dimension but do not focus on memory efficiency, which limits the sequence lengths they can support. More advanced techniques, such as Fully Pipelined Distributed Transformer or activation offloading, can further extend the possible context length at the cost of training throughput. In this paper, we present UPipe, a simple yet effective context parallelism technique that performs fine-grained chunking at the attention head level. This technique significantly reduces the activation memory usage of self-attention, breaking the activation memory barrier and unlocking much longer context lengths. Our approach reduces intermediate tensor memory usage in the attention layer by as much as 87.5$\%$ for 32B Transformers, while matching previous context parallelism techniques in terms of training speed. UPipe can support the context length of 5M tokens when training Llama3-8B on a single 8$\times$H100 node, improving upon prior methods by over 25$\%$.
Dialogue Without Limits: Constant-Sized KV Caches for Extended Responses in LLMs
Mar 02, 2025Autoregressive Transformers rely on Key-Value (KV) caching to accelerate inference. However, the linear growth of the KV cache with context length leads to excessive memory consumption and bandwidth constraints. This bottleneck is particularly problematic in real-time applications -- such as chatbots and interactive assistants -- where low latency and high memory efficiency are critical. Existing methods drop distant tokens or compress states in a lossy manner, sacrificing accuracy by discarding vital context or introducing bias. We propose MorphKV, an inference-time technique that maintains a constant-sized KV cache while preserving accuracy. MorphKV balances long-range dependencies and local coherence during text generation. It eliminates early-token bias while retaining high-fidelity context by adaptively ranking tokens through correlation-aware selection. Unlike heuristic retention or lossy compression, MorphKV iteratively refines the KV cache via lightweight updates guided by attention patterns of recent tokens. This approach captures inter-token correlation with greater accuracy, crucial for tasks like content creation and code generation. Our studies on long-response tasks show 52.9$\%$ memory savings and 18.2$\%$ higher accuracy on average compared to state-of-the-art prior works, enabling efficient real-world deployment.
CORAL: Contextual Response Retrievability Loss Function for Training Dialog Generation Models
May 21, 2022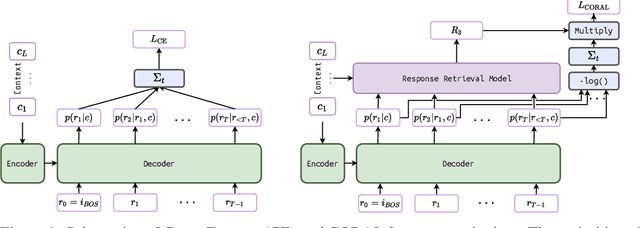

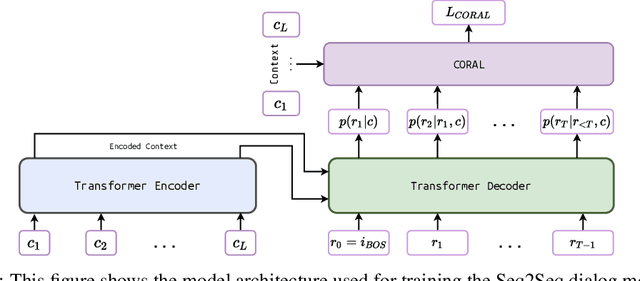
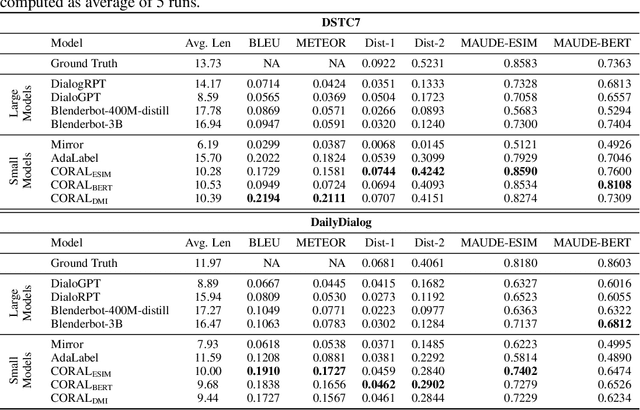
Natural Language Generation (NLG) represents a large collection of tasks in the field of NLP. While many of these tasks have been tackled well by the cross-entropy (CE) loss, the task of dialog generation poses a few unique challenges for this loss function. First, CE loss assumes that for any given input, the only possible output is the one available as the ground truth in the training dataset. In general, this is not true for any task, as there can be multiple semantically equivalent sentences, each with a different surface form. This problem gets exaggerated further for the dialog generation task, as there can be multiple valid responses (for a given context) that not only have different surface forms but are also not semantically equivalent. Second, CE loss does not take the context into consideration while processing the response and, hence, it treats all ground truths with equal importance irrespective of the context. But, we may want our final agent to avoid certain classes of responses (e.g. bland, non-informative or biased responses) and give relatively higher weightage for more context-specific responses. To circumvent these shortcomings of the CE loss, in this paper, we propose a novel loss function, CORAL, that directly optimizes recently proposed estimates of human preference for generated responses. Using CORAL, we can train dialog generation models without assuming non-existence of response other than the ground-truth. Also, the CORAL loss is computed based on both the context and the response. Extensive comparisons on two benchmark datasets show that the proposed methods outperform strong state-of-the-art baseline models of different sizes.