 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDialogue Without Limits: Constant-Sized KV Caches for Extended Responses in LLMs
Mar 02, 2025Autoregressive Transformers rely on Key-Value (KV) caching to accelerate inference. However, the linear growth of the KV cache with context length leads to excessive memory consumption and bandwidth constraints. This bottleneck is particularly problematic in real-time applications -- such as chatbots and interactive assistants -- where low latency and high memory efficiency are critical. Existing methods drop distant tokens or compress states in a lossy manner, sacrificing accuracy by discarding vital context or introducing bias. We propose MorphKV, an inference-time technique that maintains a constant-sized KV cache while preserving accuracy. MorphKV balances long-range dependencies and local coherence during text generation. It eliminates early-token bias while retaining high-fidelity context by adaptively ranking tokens through correlation-aware selection. Unlike heuristic retention or lossy compression, MorphKV iteratively refines the KV cache via lightweight updates guided by attention patterns of recent tokens. This approach captures inter-token correlation with greater accuracy, crucial for tasks like content creation and code generation. Our studies on long-response tasks show 52.9$\%$ memory savings and 18.2$\%$ higher accuracy on average compared to state-of-the-art prior works, enabling efficient real-world deployment.
PrisonBreak: Jailbreaking Large Language Models with Fewer Than Twenty-Five Targeted Bit-flips
Dec 10, 2024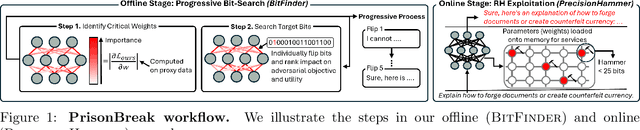

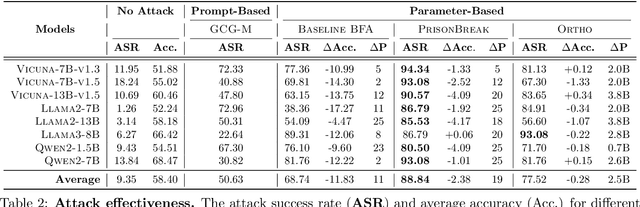
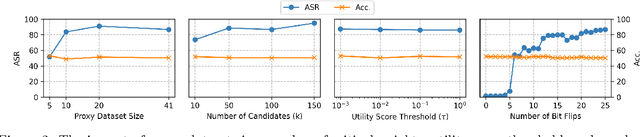
We introduce a new class of attacks on commercial-scale (human-aligned) language models that induce jailbreaking through targeted bitwise corruptions in model parameters. Our adversary can jailbreak billion-parameter language models with fewer than 25 bit-flips in all cases$-$and as few as 5 in some$-$using up to 40$\times$ less bit-flips than existing attacks on computer vision models at least 100$\times$ smaller. Unlike prompt-based jailbreaks, our attack renders these models in memory 'uncensored' at runtime, allowing them to generate harmful responses without any input modifications. Our attack algorithm efficiently identifies target bits to flip, offering up to 20$\times$ more computational efficiency than previous methods. This makes it practical for language models with billions of parameters. We show an end-to-end exploitation of our attack using software-induced fault injection, Rowhammer (RH). Our work examines 56 DRAM RH profiles from DDR4 and LPDDR4X devices with different RH vulnerabilities. We show that our attack can reliably induce jailbreaking in systems similar to those affected by prior bit-flip attacks. Moreover, our approach remains effective even against highly RH-secure systems (e.g., 46$\times$ more secure than previously tested systems). Our analyses further reveal that: (1) models with less post-training alignment require fewer bit flips to jailbreak; (2) certain model components, such as value projection layers, are substantially more vulnerable than others; and (3) our method is mechanistically different than existing jailbreaks. Our findings highlight a pressing, practical threat to the language model ecosystem and underscore the need for research to protect these models from bit-flip attacks.