 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealth+: Empowering Individuals via Unifying Health Data
Feb 22, 2026Managing personal health data is a challenge in today's fragmented and institution-centric healthcare ecosystem. Individuals often lack meaningful control over their medical records, which are scattered across incompatible systems and formats. This vision paper presents Health+, a user-centric, multimodal health data management system that empowers individuals (including those with limited technical expertise) to upload, query, and share their data across modalities (e.g., text, images, reports). Rather than aiming for institutional overhaul, Health+ emphasizes individual agency by providing intuitive interfaces and intelligent recommendations for data access and sharing. At the system level, it tackles the complexity of storing, integrating, and securing heterogeneous health records, ensuring both efficiency and privacy. By unifying multimodal data and prioritizing patients, Health+ lays the foundation for a more connected, interpretable, and user-controlled health information ecosystem.
A Study on the Refining Handwritten Font by Mixing Font Styles
May 19, 2025Handwritten fonts have a distinct expressive character, but they are often difficult to read due to unclear or inconsistent handwriting. FontFusionGAN (FFGAN) is a novel method for improving handwritten fonts by combining them with printed fonts. Our method implements generative adversarial network (GAN) to generate font that mix the desirable features of handwritten and printed fonts. By training the GAN on a dataset of handwritten and printed fonts, it can generate legible and visually appealing font images. We apply our method to a dataset of handwritten fonts and demonstrate that it significantly enhances the readability of the original fonts while preserving their unique aesthetic. Our method has the potential to improve the readability of handwritten fonts, which would be helpful for a variety of applications including document creation, letter writing, and assisting individuals with reading and writing difficulties. In addition to addressing the difficulties of font creation for languages with complex character sets, our method is applicable to other text-image-related tasks, such as font attribute control and multilingual font style transfer.
Text-Conditioned Diffusion Model for High-Fidelity Korean Font Generation
Apr 30, 2025Automatic font generation (AFG) is the process of creating a new font using only a few examples of the style images. Generating fonts for complex languages like Korean and Chinese, particularly in handwritten styles, presents significant challenges. Traditional AFGs, like Generative adversarial networks (GANs) and Variational Auto-Encoders (VAEs), are usually unstable during training and often face mode collapse problems. They also struggle to capture fine details within font images. To address these problems, we present a diffusion-based AFG method which generates high-quality, diverse Korean font images using only a single reference image, focusing on handwritten and printed styles. Our approach refines noisy images incrementally, ensuring stable training and visually appealing results. A key innovation is our text encoder, which processes phonetic representations to generate accurate and contextually correct characters, even for unseen characters. We used a pre-trained style encoder from DG FONT to effectively and accurately encode the style images. To further enhance the generation quality, we used perceptual loss that guides the model to focus on the global style of generated images. Experimental results on over 2000 Korean characters demonstrate that our model consistently generates accurate and detailed font images and outperforms benchmark methods, making it a reliable tool for generating authentic Korean fonts across different styles.
HELIOS: Adaptive Model And Early-Exit Selection for Efficient LLM Inference Serving
Apr 14, 2025



Deploying large language models (LLMs) presents critical challenges due to the inherent trade-offs associated with key performance metrics, such as latency, accuracy, and throughput. Typically, gains in one metric is accompanied with degradation in others. Early-Exit LLMs (EE-LLMs) efficiently navigate this trade-off space by skipping some of the later model layers when it confidently finds an output token early, thus reducing latency without impacting accuracy. However, as the early exits taken depend on the task and are unknown apriori to request processing, EE-LLMs conservatively load the entire model, limiting resource savings and throughput. Also, current frameworks statically select a model for a user task, limiting our ability to adapt to changing nature of the input queries. We propose HELIOS to address these challenges. First, HELIOS shortlists a set of candidate LLMs, evaluates them using a subset of prompts, gathering telemetry data in real-time. Second, HELIOS uses the early exit data from these evaluations to greedily load the selected model only up to a limited number of layers. This approach yields memory savings which enables us to process more requests at the same time, thereby improving throughput. Third, HELIOS monitors and periodically reassesses the performance of the candidate LLMs and if needed, switches to another model that can service incoming queries more efficiently (such as using fewer layers without lowering accuracy). Our evaluations show that HELIOS achieves 1.48$\times$ throughput, 1.10$\times$ energy-efficiency, 1.39$\times$ lower response time, and 3.7$\times$ improvements in inference batch sizes compared to the baseline, when optimizing for the respective service level objectives.
Dialogue Without Limits: Constant-Sized KV Caches for Extended Responses in LLMs
Mar 02, 2025Autoregressive Transformers rely on Key-Value (KV) caching to accelerate inference. However, the linear growth of the KV cache with context length leads to excessive memory consumption and bandwidth constraints. This bottleneck is particularly problematic in real-time applications -- such as chatbots and interactive assistants -- where low latency and high memory efficiency are critical. Existing methods drop distant tokens or compress states in a lossy manner, sacrificing accuracy by discarding vital context or introducing bias. We propose MorphKV, an inference-time technique that maintains a constant-sized KV cache while preserving accuracy. MorphKV balances long-range dependencies and local coherence during text generation. It eliminates early-token bias while retaining high-fidelity context by adaptively ranking tokens through correlation-aware selection. Unlike heuristic retention or lossy compression, MorphKV iteratively refines the KV cache via lightweight updates guided by attention patterns of recent tokens. This approach captures inter-token correlation with greater accuracy, crucial for tasks like content creation and code generation. Our studies on long-response tasks show 52.9$\%$ memory savings and 18.2$\%$ higher accuracy on average compared to state-of-the-art prior works, enabling efficient real-world deployment.
READ: Reinforcement-based Adversarial Learning for Text Classification with Limited Labeled Data
Jan 14, 2025Pre-trained transformer models such as BERT have shown massive gains across many text classification tasks. However, these models usually need enormous labeled data to achieve impressive performances. Obtaining labeled data is often expensive and time-consuming, whereas collecting unlabeled data using some heuristics is relatively much cheaper for any task. Therefore, this paper proposes a method that encapsulates reinforcement learning-based text generation and semi-supervised adversarial learning approaches in a novel way to improve the model's performance. Our method READ, Reinforcement-based Adversarial learning, utilizes an unlabeled dataset to generate diverse synthetic text through reinforcement learning, improving the model's generalization capability using adversarial learning. Our experimental results show that READ outperforms the existing state-of-art methods on multiple datasets.
Systematic design space exploration by learning the explored space using Machine Learning
Mar 14, 2023Current practice in parameter space exploration in euclidean space is dominated by randomized sampling or design of experiment methods. The biggest issue with these methods is not keeping track of what part of parameter space has been explored and what has not. In this context, we utilize the geometric learning of explored data space using modern machine learning methods to keep track of already explored regions and samples from the regions that are unexplored. For this purpose, we use a modified version of a robust random-cut forest along with other heuristic-based approaches. We demonstrate our method and its progression in two-dimensional Euclidean space but it can be extended to any dimension since the underlying method is generic.
Enhanced Fast Iterative Shrinkage Thresholding Algorithm For Linear Inverse Problem
Nov 28, 2022



The linear inverse problem emerges from various real-world applications such as Image deblurring, inpainting, etc., which are still thrust research areas for image quality improvement. In this paper, we have introduced a new algorithm called the Enhanced fast iterative shrinkage thresholding algorithm (EFISTA) for linear inverse problems. This algorithm uses a weighted least square term and a scaled version of the regularization parameter to accelerate the objective function minimization. The image deblurring simulation results show that EFISTA has a superior execution speed, with an improved performance than its predecessors in terms of peak-signal-to-noise ratio (PSNR), particularly at a high noise level. With these motivating results, we can say that the proposed EFISTA can also be helpful for other linear inverse problems to improve the reconstruction speed and handle noise effectively.
Residual Reinforcement Learning for Robot Control
Dec 18, 2018

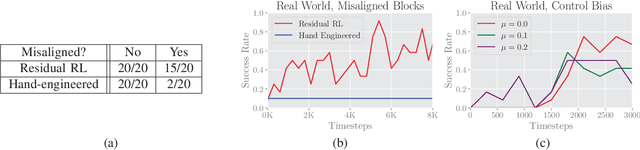

Conventional feedback control methods can solve various types of robot control problems very efficiently by capturing the structure with explicit models, such as rigid body equations of motion. However, many control problems in modern manufacturing deal with contacts and friction, which are difficult to capture with first-order physical modeling. Hence, applying control design methodologies to these kinds of problems often results in brittle and inaccurate controllers, which have to be manually tuned for deployment. Reinforcement learning (RL) methods have been demonstrated to be capable of learning continuous robot controllers from interactions with the environment, even for problems that include friction and contacts. In this paper, we study how we can solve difficult control problems in the real world by decomposing them into a part that is solved efficiently by conventional feedback control methods, and the residual which is solved with RL. The final control policy is a superposition of both control signals. We demonstrate our approach by training an agent to successfully perform a real-world block assembly task involving contacts and unstable objects.