 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid GCN-GRU Model for Anomaly Detection in Cryptocurrency Transactions
Sep 09, 2025Blockchain transaction networks are complex, with evolving temporal patterns and inter-node relationships. To detect illicit activities, we propose a hybrid GCN-GRU model that captures both structural and sequential features. Using real Bitcoin transaction data (2020-2024), our model achieved 0.9470 Accuracy and 0.9807 AUC-ROC, outperforming all baselines.
A Study on the Refining Handwritten Font by Mixing Font Styles
May 19, 2025Handwritten fonts have a distinct expressive character, but they are often difficult to read due to unclear or inconsistent handwriting. FontFusionGAN (FFGAN) is a novel method for improving handwritten fonts by combining them with printed fonts. Our method implements generative adversarial network (GAN) to generate font that mix the desirable features of handwritten and printed fonts. By training the GAN on a dataset of handwritten and printed fonts, it can generate legible and visually appealing font images. We apply our method to a dataset of handwritten fonts and demonstrate that it significantly enhances the readability of the original fonts while preserving their unique aesthetic. Our method has the potential to improve the readability of handwritten fonts, which would be helpful for a variety of applications including document creation, letter writing, and assisting individuals with reading and writing difficulties. In addition to addressing the difficulties of font creation for languages with complex character sets, our method is applicable to other text-image-related tasks, such as font attribute control and multilingual font style transfer.
Text-Conditioned Diffusion Model for High-Fidelity Korean Font Generation
Apr 30, 2025Automatic font generation (AFG) is the process of creating a new font using only a few examples of the style images. Generating fonts for complex languages like Korean and Chinese, particularly in handwritten styles, presents significant challenges. Traditional AFGs, like Generative adversarial networks (GANs) and Variational Auto-Encoders (VAEs), are usually unstable during training and often face mode collapse problems. They also struggle to capture fine details within font images. To address these problems, we present a diffusion-based AFG method which generates high-quality, diverse Korean font images using only a single reference image, focusing on handwritten and printed styles. Our approach refines noisy images incrementally, ensuring stable training and visually appealing results. A key innovation is our text encoder, which processes phonetic representations to generate accurate and contextually correct characters, even for unseen characters. We used a pre-trained style encoder from DG FONT to effectively and accurately encode the style images. To further enhance the generation quality, we used perceptual loss that guides the model to focus on the global style of generated images. Experimental results on over 2000 Korean characters demonstrate that our model consistently generates accurate and detailed font images and outperforms benchmark methods, making it a reliable tool for generating authentic Korean fonts across different styles.
Dynamic RF Beam Codebook Reduction for Cost-Efficient mmWave Full-Duplex Systems
Aug 29, 2022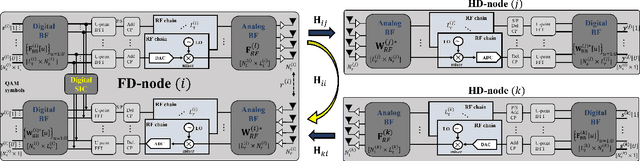

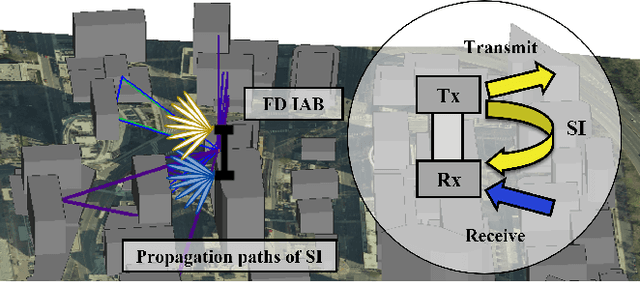
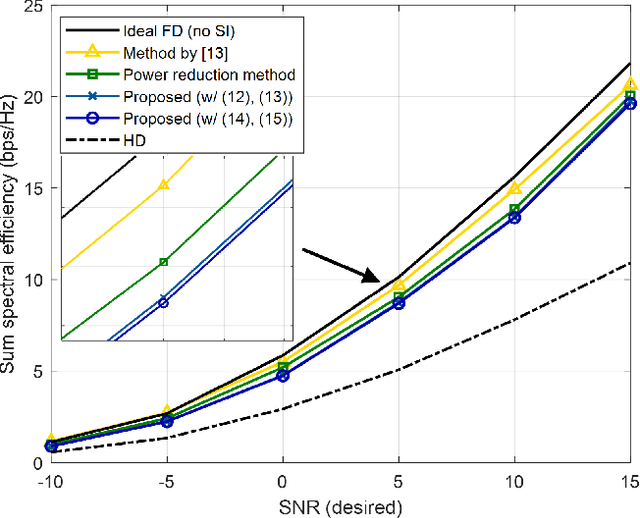
The recent attempts to realize full-duplex (FD) communications in millimeter wave (mmWave) systems have garnered a significant amount of interest for its potential. In this paper, we present a cost-efficient design of mmWave FD systems, where the system dynamically reduces the RF beam codebook in a computationally efficient manner, so that it is comprised of the RF beams that will prevent the Rx receive chain from saturating due to the self-interference (SI). The analog beamformer will suppress the SI to the level that the residual SI can be completely removed with digital SI cancellation, allowing the digital beamformer to concentrate on the desired channel, free of the SI. To reduce the computation required for the proposed method, we propose two sufficient conditions that prevent the Rx side saturations, which are practically tight. Through performance valuations conducted in realistically modeled mmWave FD scenarios, we demonstrate that the proposed design achieves comparable performance with the ideal FD and other benchmarks with significantly lower costs.
FontNet: Closing the gap to font designer performance in font synthesis
May 13, 2022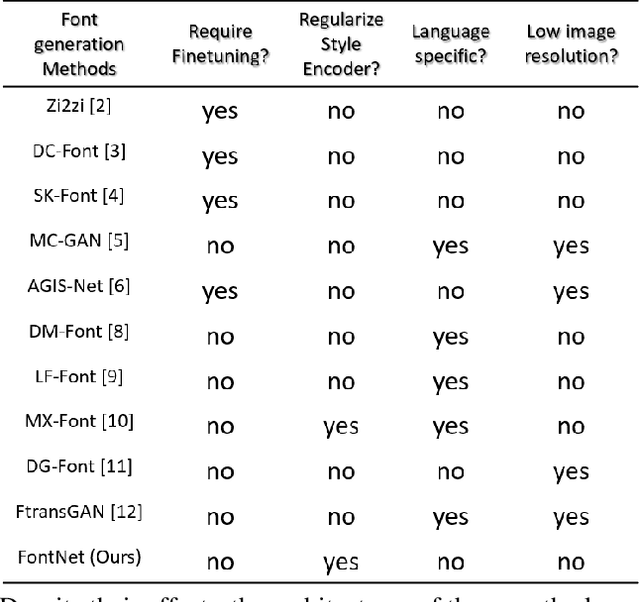
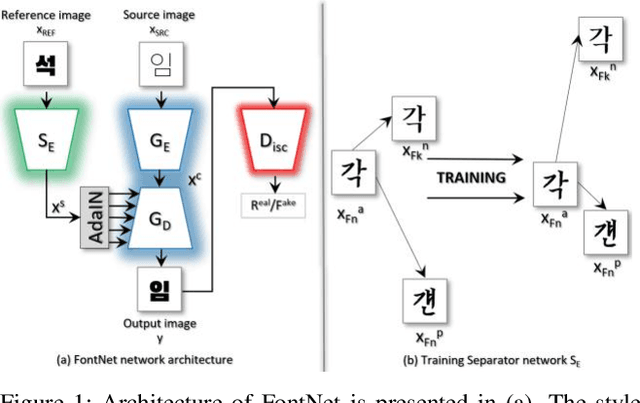
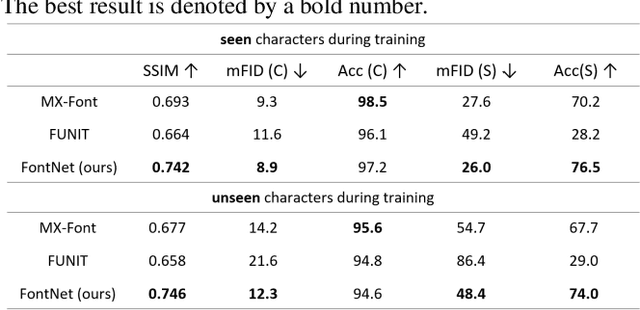

Font synthesis has been a very active topic in recent years because manual font design requires domain expertise and is a labor-intensive and time-consuming job. While remarkably successful, existing methods for font synthesis have major shortcomings; they require finetuning for unobserved font style with large reference images, the recent few-shot font synthesis methods are either designed for specific language systems or they operate on low-resolution images which limits their use. In this paper, we tackle this font synthesis problem by learning the font style in the embedding space. To this end, we propose a model, called FontNet, that simultaneously learns to separate font styles in the embedding space where distances directly correspond to a measure of font similarity, and translates input images into the given observed or unobserved font style. Additionally, we design the network architecture and training procedure that can be adopted for any language system and can produce high-resolution font images. Thanks to this approach, our proposed method outperforms the existing state-of-the-art font generation methods on both qualitative and quantitative experiments.
Sequential Movie Genre Prediction using Average Transition Probability with Clustering
Nov 04, 2021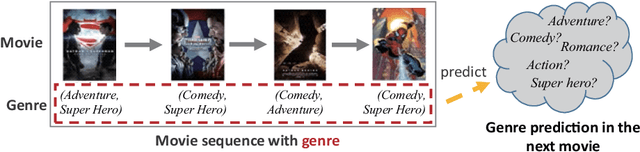
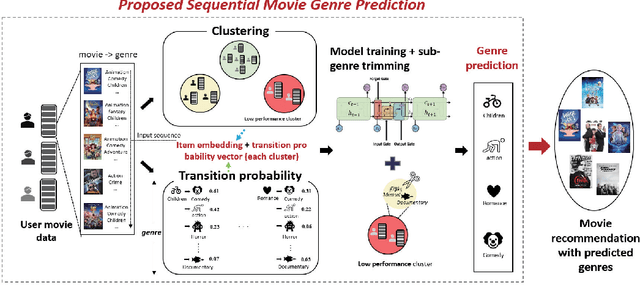
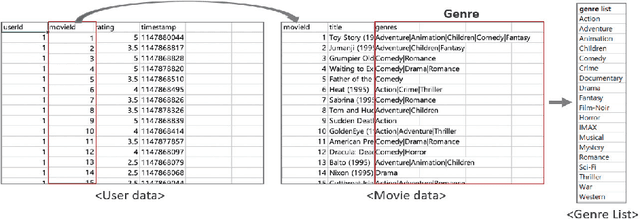
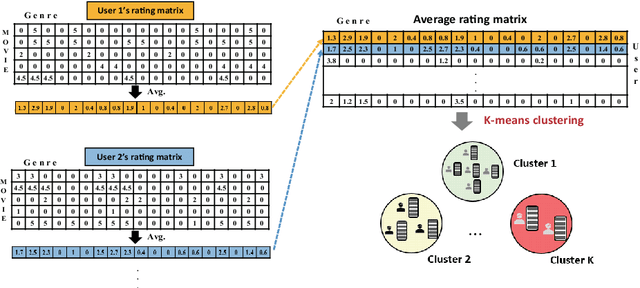
In recent movie recommendations, predicting the user's sequential behavior and suggesting the next movie to watch is one of the most important issues. However, capturing such sequential behavior is not easy because each user's short-term or long-term behavior must be taken into account. For this reason, many research results show that the performance of recommending a specific movie is not very high in a sequential recommendation. In this paper, we propose a cluster-based method for classifying users with similar movie purchase patterns and a movie genre prediction algorithm rather than the movie itself considering their short-term and long-term behaviors. The movie genre prediction does not recommend a specific movie, but it predicts the genre for the next movie to watch in consideration of each user's preference for the movie genre based on the genre included in the movie. Through this, it is possible to provide appropriate guidelines for recommending movies including the genre to users who tend to prefer a specific genre. In particular, in this paper, users with similar genre preferences are organized into clusters to recommend genres, and in clusters that do not have relatively specific tendencies, genre prediction is performed by appropriately trimming genres that are not necessary for recommendation in order to improve performance. We evaluate our method on well-known movie datasets, and qualitatively that it captures personalized dynamics and is able to make meaningful recommendations.
DIME: An Online Tool for the Visual Comparison of Cross-Modal Retrieval Models
Oct 19, 2020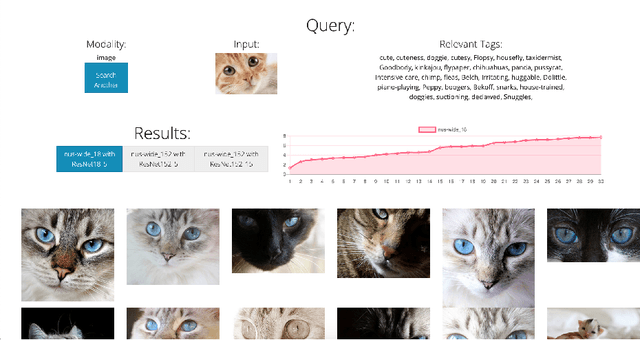
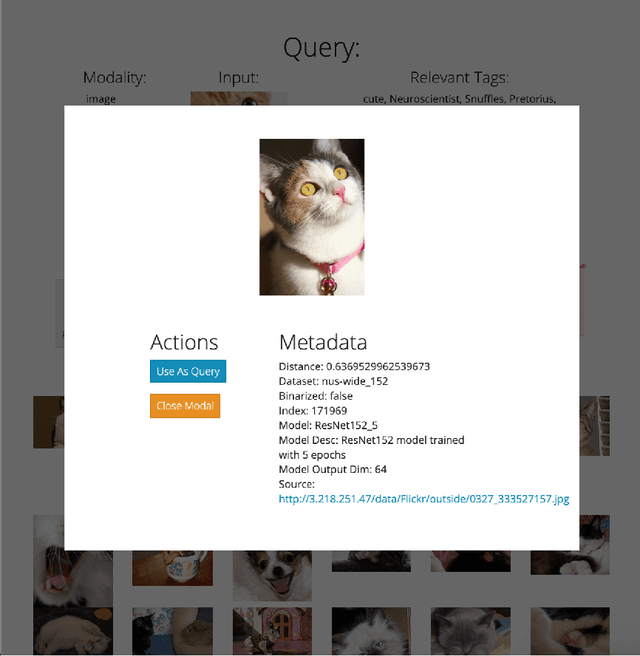
Cross-modal retrieval relies on accurate models to retrieve relevant results for queries across modalities such as image, text, and video. In this paper, we build upon previous work by tackling the difficulty of evaluating models both quantitatively and qualitatively quickly. We present DIME (Dataset, Index, Model, Embedding), a modality-agnostic tool that handles multimodal datasets, trained models, and data preprocessors to support straightforward model comparison with a web browser graphical user interface. DIME inherently supports building modality-agnostic queryable indexes and extraction of relevant feature embeddings, and thus effectively doubles as an efficient cross-modal tool to explore and search through datasets.