 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks for Multimodal AutoML with Image, Text, and Tabular Data
Dec 19, 2024



This paper studies the best practices for automatic machine learning (AutoML). While previous AutoML efforts have predominantly focused on unimodal data, the multimodal aspect remains under-explored. Our study delves into classification and regression problems involving flexible combinations of image, text, and tabular data. We curate a benchmark comprising 22 multimodal datasets from diverse real-world applications, encompassing all 4 combinations of the 3 modalities. Across this benchmark, we scrutinize design choices related to multimodal fusion strategies, multimodal data augmentation, converting tabular data into text, cross-modal alignment, and handling missing modalities. Through extensive experimentation and analysis, we distill a collection of effective strategies and consolidate them into a unified pipeline, achieving robust performance on diverse datasets.
PPLqa: An Unsupervised Information-Theoretic Quality Metric for Comparing Generative Large Language Models
Nov 22, 2024We propose PPLqa, an easy to compute, language independent, information-theoretic metric to measure the quality of responses of generative Large Language Models (LLMs) in an unsupervised way, without requiring ground truth annotations or human supervision. The method and metric enables users to rank generative language models for quality of responses, so as to make a selection of the best model for a given task. Our single metric assesses LLMs with an approach that subsumes, but is not explicitly based on, coherence and fluency (quality of writing) and relevance and consistency (appropriateness of response) to the query. PPLqa performs as well as other related metrics, and works better with long-form Q\&A. Thus, PPLqa enables bypassing the lengthy annotation process required for ground truth evaluations, and it also correlates well with human and LLM rankings.
Enhancing GAN-Based Vocoders with Contrastive Learning Under Data-limited Condition
Sep 16, 2023



Vocoder models have recently achieved substantial progress in generating authentic audio comparable to human quality while significantly reducing memory requirement and inference time. However, these data-hungry generative models require large-scale audio data for learning good representations. In this paper, we apply contrastive learning methods in training the vocoder to improve the perceptual quality of the vocoder without modifying its architecture or adding more data. We design an auxiliary task with mel-spectrogram contrastive learning to enhance the utterance-level quality of the vocoder model under data-limited conditions. We also extend the task to include waveforms to improve the multi-modality comprehension of the model and address the discriminator overfitting problem. We optimize the additional task simultaneously with GAN training objectives. Our result shows that the tasks improve model performance substantially in data-limited settings. Our analysis based on the result indicates that the proposed design successfully alleviates discriminator overfitting and produces audio of higher fidelity.
Detecting COVID-19 Conspiracy Theories with Transformers and TF-IDF
May 01, 2022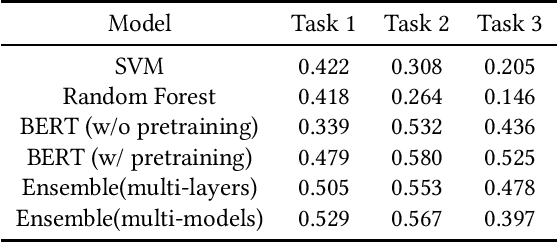
The sharing of fake news and conspiracy theories on social media has wide-spread negative effects. By designing and applying different machine learning models, researchers have made progress in detecting fake news from text. However, existing research places a heavy emphasis on general, common-sense fake news, while in reality fake news often involves rapidly changing topics and domain-specific vocabulary. In this paper, we present our methods and results for three fake news detection tasks at MediaEval benchmark 2021 that specifically involve COVID-19 related topics. We experiment with a group of text-based models including Support Vector Machines, Random Forest, BERT, and RoBERTa. We find that a pre-trained transformer yields the best validation results, but a randomly initialized transformer with smart design can also be trained to reach accuracies close to that of the pre-trained transformer.
Multi-modal Ensemble Models for Predicting Video Memorability
Feb 01, 2021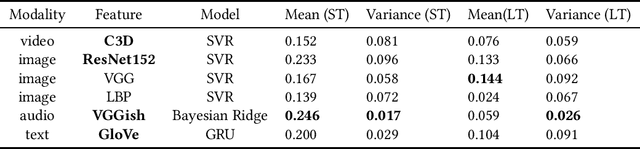
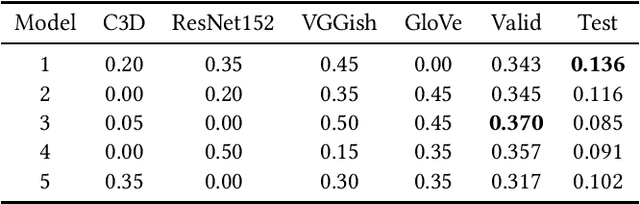
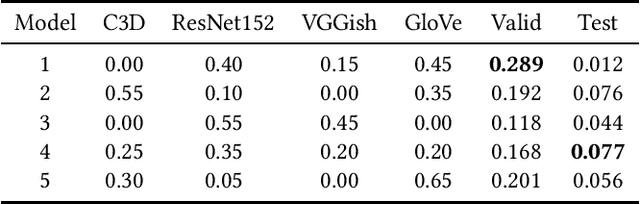
Modeling media memorability has been a consistent challenge in the field of machine learning. The Predicting Media Memorability task in MediaEval2020 is the latest benchmark among similar challenges addressing this topic. Building upon techniques developed in previous iterations of the challenge, we developed ensemble methods with the use of extracted video, image, text, and audio features. Critically, in this work we introduce and demonstrate the efficacy and high generalizability of extracted audio embeddings as a feature for the task of predicting media memorability.
OrigamiSet1.0: Two New Datasets for Origami Classification and Difficulty Estimation
Jan 14, 2021
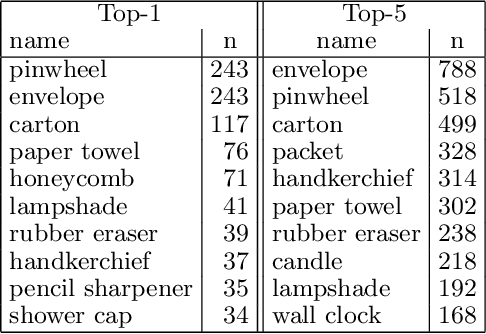


Origami is becoming more and more relevant to research. However, there is no public dataset yet available and there hasn't been any research on this topic in machine learning. We constructed an origami dataset using images from the multimedia commons and other databases. It consists of two subsets: one for classification of origami images and the other for difficulty estimation. We obtained 16000 images for classification (half origami, half other objects) and 1509 for difficulty estimation with $3$ different categories (easy: 764, intermediate: 427, complex: 318). The data can be downloaded at: https://github.com/multimedia-berkeley/OriSet. Finally, we provide machine learning baselines.
From Tinkering to Engineering: Measurements in Tensorflow Playground
Jan 11, 2021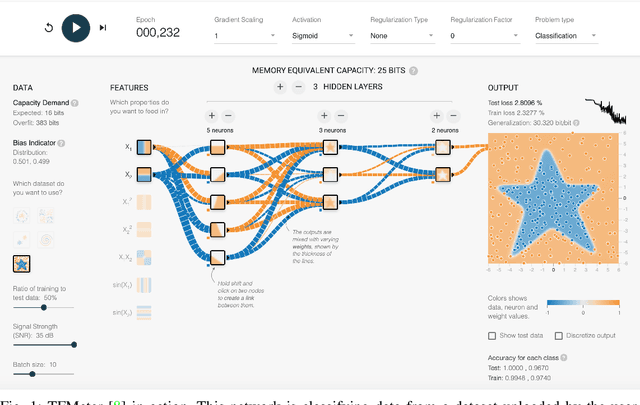
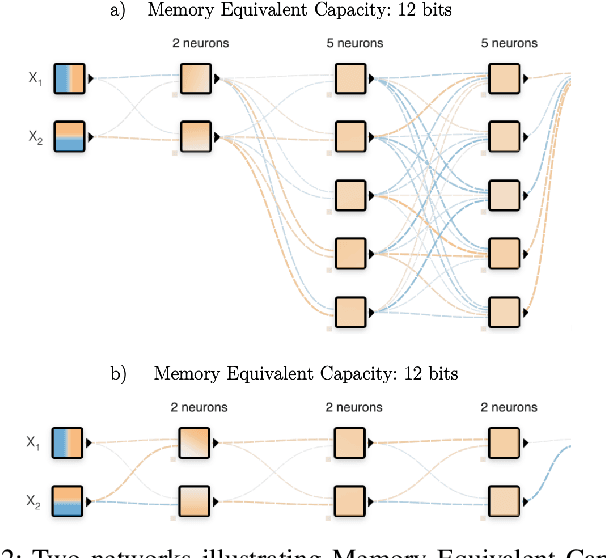
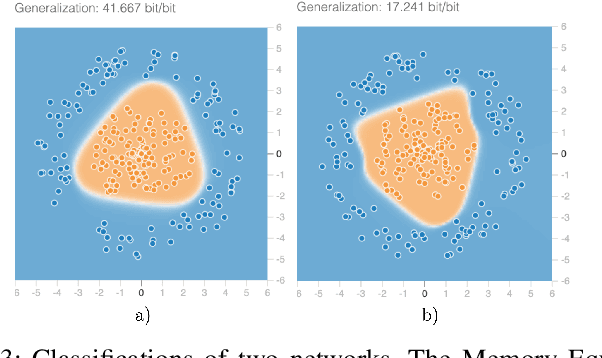
In this article, we present an extension of the Tensorflow Playground, called Tensorflow Meter (short TFMeter). TFMeter is an interactive neural network architecting tool that allows the visual creation of different architectures of neural networks. In addition to its ancestor, the playground, our tool shows information-theoretic measurements while constructing, training, and testing the network. As a result, each change results in a change in at least one of the measurements, providing for a better engineering intuition of what different architectures are able to learn. The measurements are derived from various places in the literature. In this demo, we describe our web application that is available online at http://tfmeter.icsi.berkeley.edu/ and argue that in the same way that the original Playground is meant to build an intuition about neural networks, our extension educates users on available measurements, which we hope will ultimately improve experimental design and reproducibility in the field.
* 3 pages, 3 figures, ICPR 2020
DIME: An Online Tool for the Visual Comparison of Cross-Modal Retrieval Models
Oct 19, 2020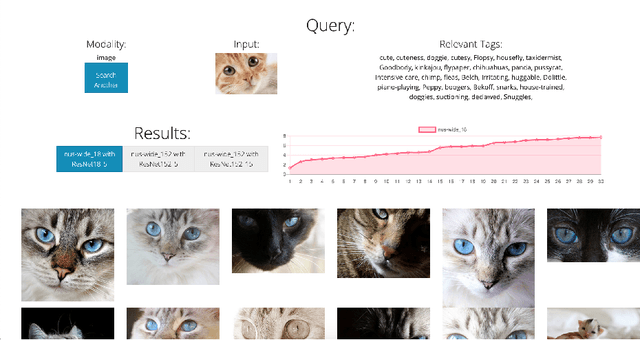
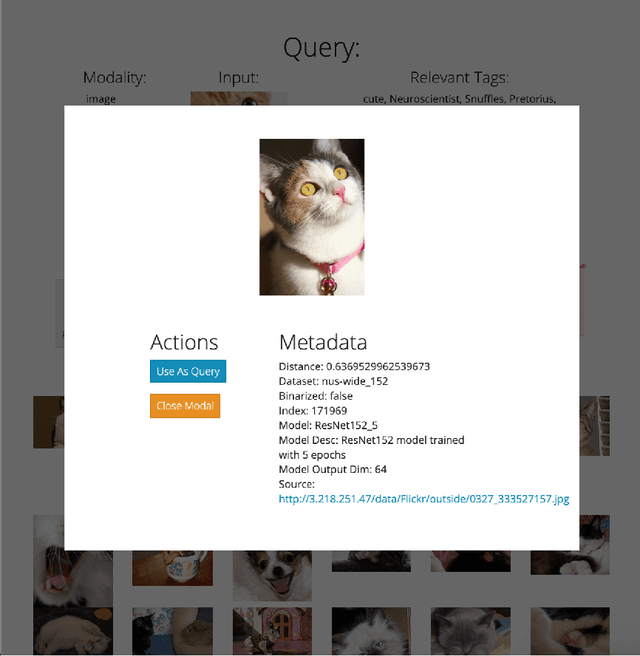
Cross-modal retrieval relies on accurate models to retrieve relevant results for queries across modalities such as image, text, and video. In this paper, we build upon previous work by tackling the difficulty of evaluating models both quantitatively and qualitatively quickly. We present DIME (Dataset, Index, Model, Embedding), a modality-agnostic tool that handles multimodal datasets, trained models, and data preprocessors to support straightforward model comparison with a web browser graphical user interface. DIME inherently supports building modality-agnostic queryable indexes and extraction of relevant feature embeddings, and thus effectively doubles as an efficient cross-modal tool to explore and search through datasets.
Efficient Saliency Maps for Explainable AI
Nov 26, 2019
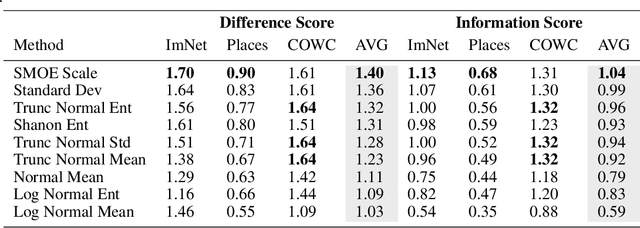

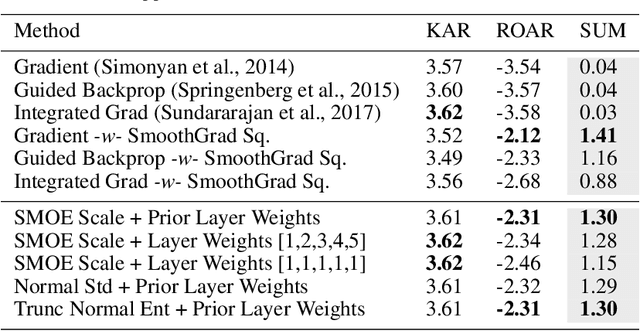
We describe an explainable AI saliency map method for use with deep convolutional neural networks (CNN) that is much more efficient than popular gradient methods. It is also quantitatively similar and better in accuracy. Our technique works by measuring information at the end of each network scale which is then combined into a single saliency map. We describe how saliency measures can be made more efficient by exploiting Saliency Map Order Equivalence. Finally, we visualize individual scale/layer contributions by using a Layer Ordered Visualization of Information. This provides an interesting comparison of scale information contributions within the network not provided by other saliency map methods. Since our method only requires a single forward pass through a few of the layers in a network, it is at least 97x faster than Guided Backprop and much more accurate. Using our method instead of Guided Backprop, class activation methods such as Grad-CAM, Grad-CAM++ and Smooth Grad-CAM++ will run several orders of magnitude faster, have a significantly smaller memory footprint and be more accurate. This will make such methods feasible on resource limited platforms such as robots, cell phones and low cost industrial devices. This will also significantly help them work in extremely data intensive applications such as satellite image processing. All without sacrificing accuracy. Our method is generally straight forward and should be applicable to the most commonly used CNNs. We also show examples of our method used to enhance Grad-CAM++.
One Bit Matters: Understanding Adversarial Examples as the Abuse of Redundancy
Oct 23, 2018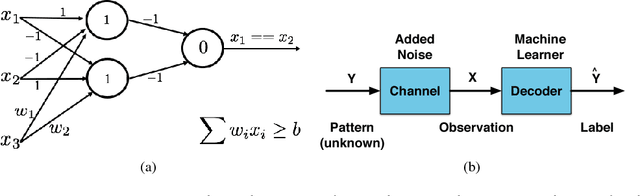


Despite the great success achieved in machine learning (ML), adversarial examples have caused concerns with regards to its trustworthiness: A small perturbation of an input results in an arbitrary failure of an otherwise seemingly well-trained ML model. While studies are being conducted to discover the intrinsic properties of adversarial examples, such as their transferability and universality, there is insufficient theoretic analysis to help understand the phenomenon in a way that can influence the design process of ML experiments. In this paper, we deduce an information-theoretic model which explains adversarial attacks as the abuse of feature redundancies in ML algorithms. We prove that feature redundancy is a necessary condition for the existence of adversarial examples. Our model helps to explain some major questions raised in many anecdotal studies on adversarial examples. Our theory is backed up by empirical measurements of the information content of benign and adversarial examples on both image and text datasets. Our measurements show that typical adversarial examples introduce just enough redundancy to overflow the decision making of an ML model trained on corresponding benign examples. We conclude with actionable recommendations to improve the robustness of machine learners against adversarial examples.