 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Bit Matters: Understanding Adversarial Examples as the Abuse of Redundancy
Paper and Code
Oct 23, 2018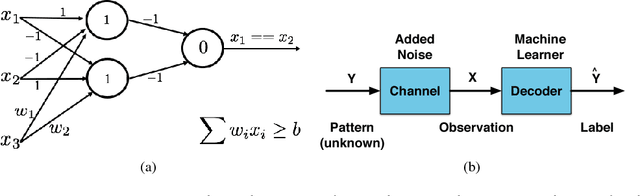


Despite the great success achieved in machine learning (ML), adversarial examples have caused concerns with regards to its trustworthiness: A small perturbation of an input results in an arbitrary failure of an otherwise seemingly well-trained ML model. While studies are being conducted to discover the intrinsic properties of adversarial examples, such as their transferability and universality, there is insufficient theoretic analysis to help understand the phenomenon in a way that can influence the design process of ML experiments. In this paper, we deduce an information-theoretic model which explains adversarial attacks as the abuse of feature redundancies in ML algorithms. We prove that feature redundancy is a necessary condition for the existence of adversarial examples. Our model helps to explain some major questions raised in many anecdotal studies on adversarial examples. Our theory is backed up by empirical measurements of the information content of benign and adversarial examples on both image and text datasets. Our measurements show that typical adversarial examples introduce just enough redundancy to overflow the decision making of an ML model trained on corresponding benign examples. We conclude with actionable recommendations to improve the robustness of machine learners against adversarial examples.