 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccidentBench: Benchmarking Multimodal Understanding and Reasoning in Vehicle Accidents and Beyond
Sep 30, 2025Rapid advances in multimodal models demand benchmarks that rigorously evaluate understanding and reasoning in safety-critical, dynamic real-world settings. We present AccidentBench, a large-scale benchmark that combines vehicle accident scenarios with Beyond domains, safety-critical settings in air and water that emphasize spatial and temporal reasoning (e.g., navigation, orientation, multi-vehicle motion). The benchmark contains approximately 2000 videos and over 19000 human-annotated question--answer pairs spanning multiple video lengths (short/medium/long) and difficulty levels (easy/medium/hard). Tasks systematically probe core capabilities: temporal, spatial, and intent understanding and reasoning. By unifying accident-centric traffic scenes with broader safety-critical scenarios in air and water, AccidentBench offers a comprehensive, physically grounded testbed for evaluating models under real-world variability. Evaluations of state-of-the-art models (e.g., Gemini-2.5 Pro and GPT-5) show that even the strongest models achieve only about 18% accuracy on the hardest tasks and longest videos, revealing substantial gaps in real-world temporal, spatial, and intent reasoning. AccidentBench is designed to expose these critical gaps and drive the development of multimodal models that are safer, more robust, and better aligned with real-world safety-critical challenges. The code and dataset are available at: https://github.com/SafeRL-Lab/AccidentBench
Few-Shot Test-Time Optimization Without Retraining for Semiconductor Recipe Generation and Beyond
May 21, 2025


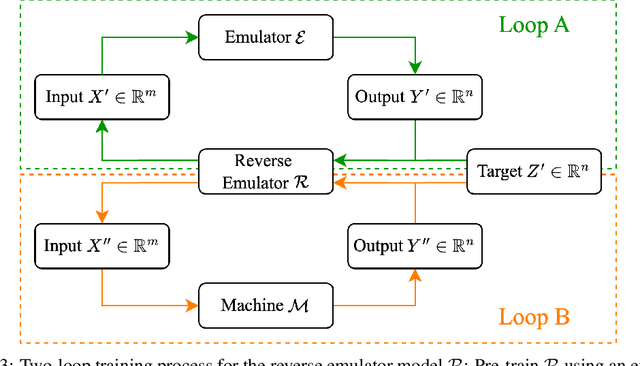
We introduce Model Feedback Learning (MFL), a novel test-time optimization framework for optimizing inputs to pre-trained AI models or deployed hardware systems without requiring any retraining of the models or modifications to the hardware. In contrast to existing methods that rely on adjusting model parameters, MFL leverages a lightweight reverse model to iteratively search for optimal inputs, enabling efficient adaptation to new objectives under deployment constraints. This framework is particularly advantageous in real-world settings, such as semiconductor manufacturing recipe generation, where modifying deployed systems is often infeasible or cost-prohibitive. We validate MFL on semiconductor plasma etching tasks, where it achieves target recipe generation in just five iterations, significantly outperforming both Bayesian optimization and human experts. Beyond semiconductor applications, MFL also demonstrates strong performance in chemical processes (e.g., chemical vapor deposition) and electronic systems (e.g., wire bonding), highlighting its broad applicability. Additionally, MFL incorporates stability-aware optimization, enhancing robustness to process variations and surpassing conventional supervised learning and random search methods in high-dimensional control settings. By enabling few-shot adaptation, MFL provides a scalable and efficient paradigm for deploying intelligent control in real-world environments.
Safe Continual Domain Adaptation after Sim2Real Transfer of Reinforcement Learning Policies in Robotics
Mar 13, 2025Domain randomization has emerged as a fundamental technique in reinforcement learning (RL) to facilitate the transfer of policies from simulation to real-world robotic applications. Many existing domain randomization approaches have been proposed to improve robustness and sim2real transfer. These approaches rely on wide randomization ranges to compensate for the unknown actual system parameters, leading to robust but inefficient real-world policies. In addition, the policies pretrained in the domain-randomized simulation are fixed after deployment due to the inherent instability of the optimization processes based on RL and the necessity of sampling exploitative but potentially unsafe actions on the real system. This limits the adaptability of the deployed policy to the inevitably changing system parameters or environment dynamics over time. We leverage safe RL and continual learning under domain-randomized simulation to address these limitations and enable safe deployment-time policy adaptation in real-world robot control. The experiments show that our method enables the policy to adapt and fit to the current domain distribution and environment dynamics of the real system while minimizing safety risks and avoiding issues like catastrophic forgetting of the general policy found in randomized simulation during the pretraining phase. Videos and supplementary material are available at https://safe-cda.github.io/.
Robust Gymnasium: A Unified Modular Benchmark for Robust Reinforcement Learning
Feb 27, 2025



Driven by inherent uncertainty and the sim-to-real gap, robust reinforcement learning (RL) seeks to improve resilience against the complexity and variability in agent-environment sequential interactions. Despite the existence of a large number of RL benchmarks, there is a lack of standardized benchmarks for robust RL. Current robust RL policies often focus on a specific type of uncertainty and are evaluated in distinct, one-off environments. In this work, we introduce Robust-Gymnasium, a unified modular benchmark designed for robust RL that supports a wide variety of disruptions across all key RL components-agents' observed state and reward, agents' actions, and the environment. Offering over sixty diverse task environments spanning control and robotics, safe RL, and multi-agent RL, it provides an open-source and user-friendly tool for the community to assess current methods and foster the development of robust RL algorithms. In addition, we benchmark existing standard and robust RL algorithms within this framework, uncovering significant deficiencies in each and offering new insights.
Reward-Safety Balance in Offline Safe RL via Diffusion Regularization
Feb 18, 2025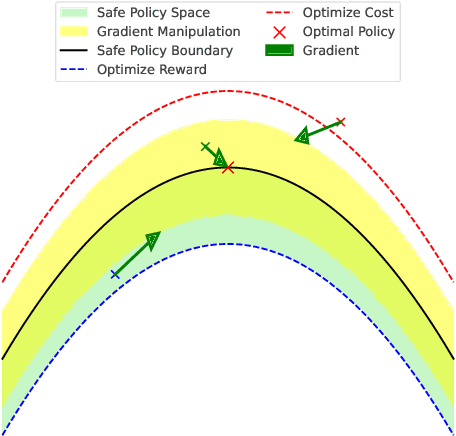

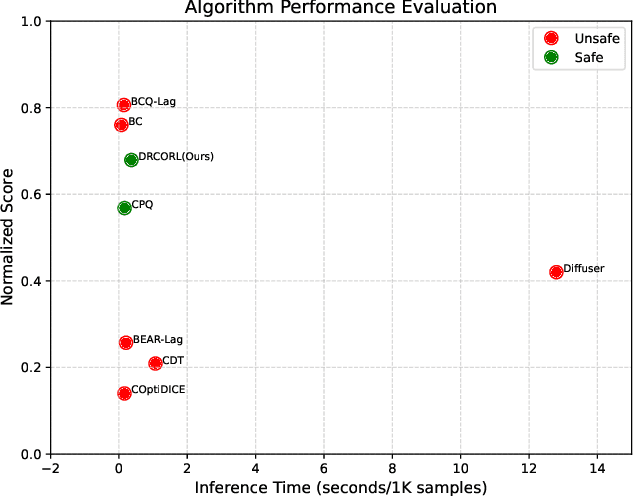
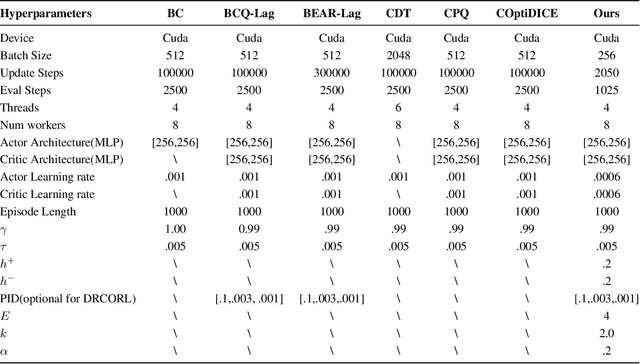
Constrained reinforcement learning (RL) seeks high-performance policies under safety constraints. We focus on an offline setting where the agent has only a fixed dataset -- common in realistic tasks to prevent unsafe exploration. To address this, we propose Diffusion-Regularized Constrained Offline Reinforcement Learning (DRCORL), which first uses a diffusion model to capture the behavioral policy from offline data and then extracts a simplified policy to enable efficient inference. We further apply gradient manipulation for safety adaptation, balancing the reward objective and constraint satisfaction. This approach leverages high-quality offline data while incorporating safety requirements. Empirical results show that DRCORL achieves reliable safety performance, fast inference, and strong reward outcomes across robot learning tasks. Compared to existing safe offline RL methods, it consistently meets cost limits and performs well with the same hyperparameters, indicating practical applicability in real-world scenarios.
Enhancing Efficiency of Safe Reinforcement Learning via Sample Manipulation
May 31, 2024



Safe reinforcement learning (RL) is crucial for deploying RL agents in real-world applications, as it aims to maximize long-term rewards while satisfying safety constraints. However, safe RL often suffers from sample inefficiency, requiring extensive interactions with the environment to learn a safe policy. We propose Efficient Safe Policy Optimization (ESPO), a novel approach that enhances the efficiency of safe RL through sample manipulation. ESPO employs an optimization framework with three modes: maximizing rewards, minimizing costs, and balancing the trade-off between the two. By dynamically adjusting the sampling process based on the observed conflict between reward and safety gradients, ESPO theoretically guarantees convergence, optimization stability, and improved sample complexity bounds. Experiments on the Safety-MuJoCo and Omnisafe benchmarks demonstrate that ESPO significantly outperforms existing primal-based and primal-dual-based baselines in terms of reward maximization and constraint satisfaction. Moreover, ESPO achieves substantial gains in sample efficiency, requiring 25--29% fewer samples than baselines, and reduces training time by 21--38%.
Active Reinforcement Learning for Robust Building Control
Dec 16, 2023
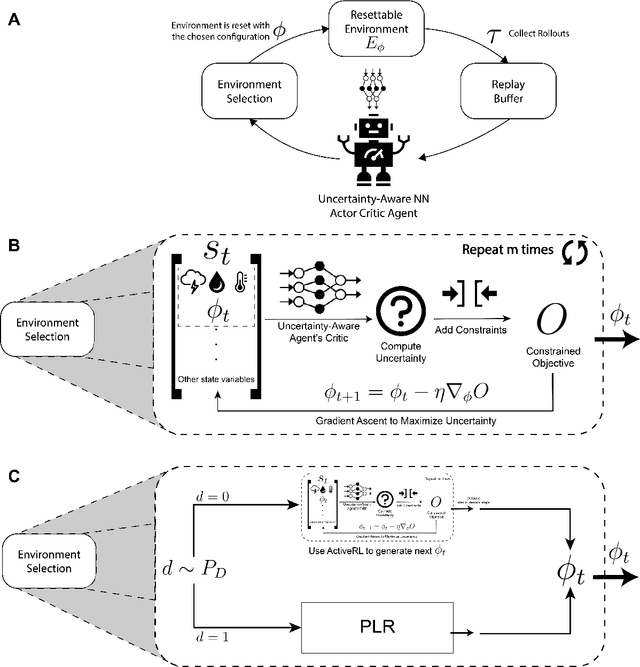
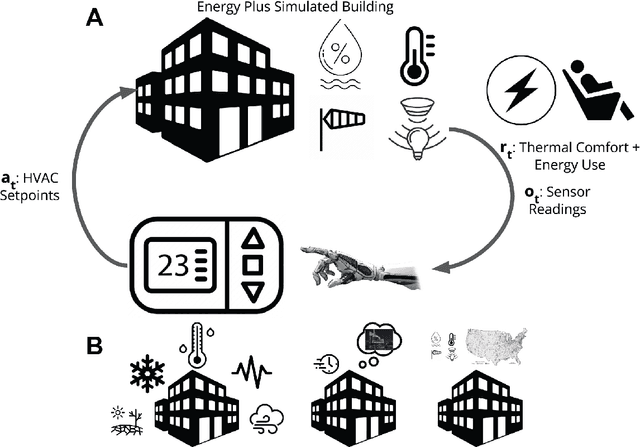
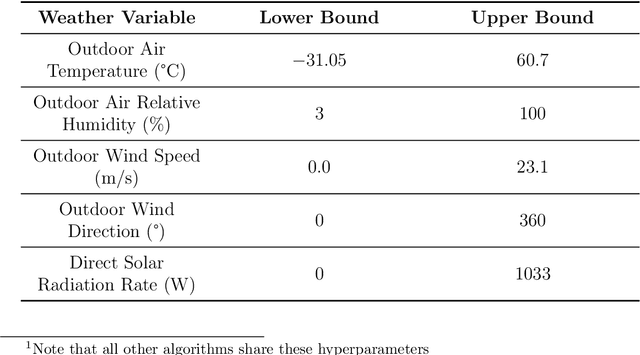
Reinforcement learning (RL) is a powerful tool for optimal control that has found great success in Atari games, the game of Go, robotic control, and building optimization. RL is also very brittle; agents often overfit to their training environment and fail to generalize to new settings. Unsupervised environment design (UED) has been proposed as a solution to this problem, in which the agent trains in environments that have been specially selected to help it learn. Previous UED algorithms focus on trying to train an RL agent that generalizes across a large distribution of environments. This is not necessarily desirable when we wish to prioritize performance in one environment over others. In this work, we will be examining the setting of robust RL building control, where we wish to train an RL agent that prioritizes performing well in normal weather while still being robust to extreme weather conditions. We demonstrate a novel UED algorithm, ActivePLR, that uses uncertainty-aware neural network architectures to generate new training environments at the limit of the RL agent's ability while being able to prioritize performance in a desired base environment. We show that ActivePLR is able to outperform state-of-the-art UED algorithms in minimizing energy usage while maximizing occupant comfort in the setting of building control.
Adapting Surprise Minimizing Reinforcement Learning Techniques for Transactive Control
Nov 11, 2021
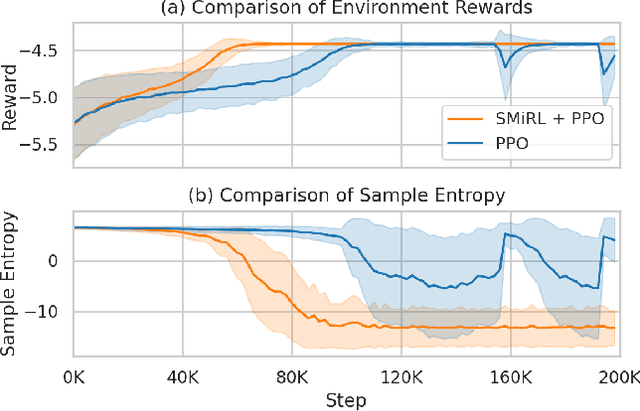
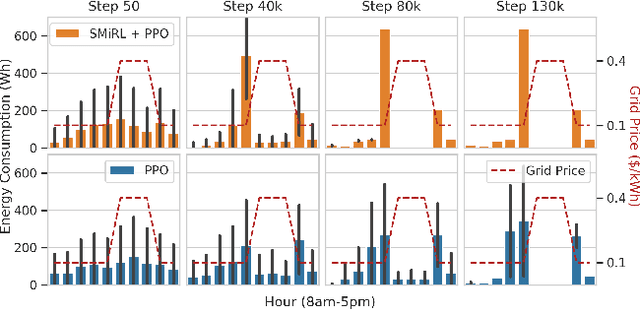
Optimizing prices for energy demand response requires a flexible controller with ability to navigate complex environments. We propose a reinforcement learning controller with surprise minimizing modifications in its architecture. We suggest that surprise minimization can be used to improve learning speed, taking advantage of predictability in peoples' energy usage. Our architecture performs well in a simulation of energy demand response. We propose this modification to improve functionality and save in a large scale experiment.
Offline-Online Reinforcement Learning for Energy Pricing in Office Demand Response: Lowering Energy and Data Costs
Aug 14, 2021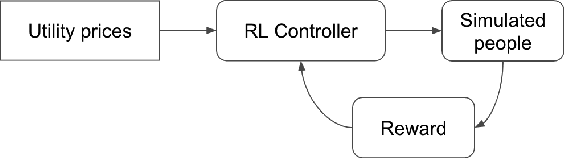

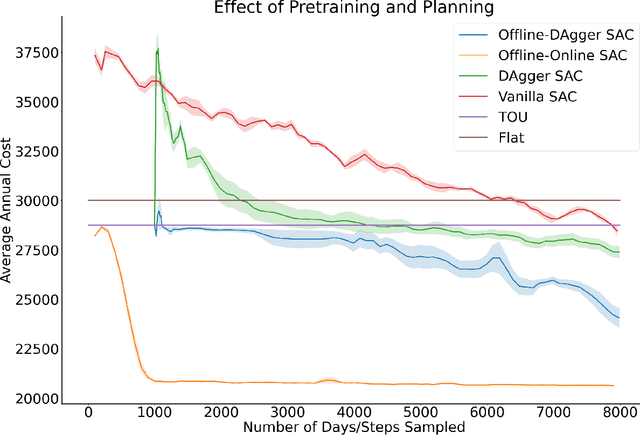
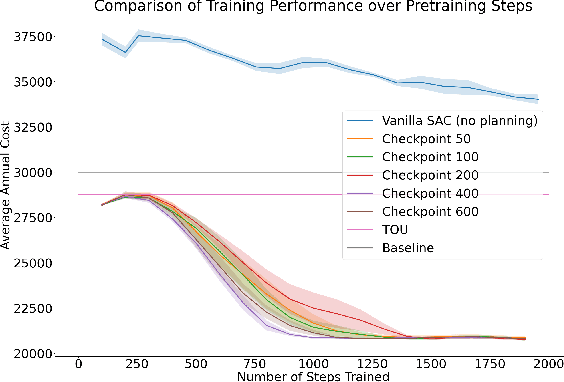
Our team is proposing to run a full-scale energy demand response experiment in an office building. Although this is an exciting endeavor which will provide value to the community, collecting training data for the reinforcement learning agent is costly and will be limited. In this work, we examine how offline training can be leveraged to minimize data costs (accelerate convergence) and program implementation costs. We present two approaches to doing so: pretraining our model to warm start the experiment with simulated tasks, and using a planning model trained to simulate the real world's rewards to the agent. We present results that demonstrate the utility of offline reinforcement learning to efficient price-setting in the energy demand response problem.
Using Meta Reinforcement Learning to Bridge the Gap between Simulation and Experiment in Energy Demand Response
May 17, 2021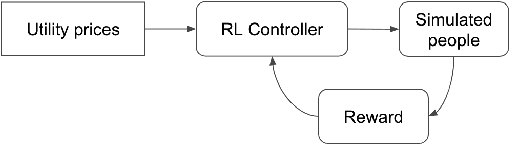
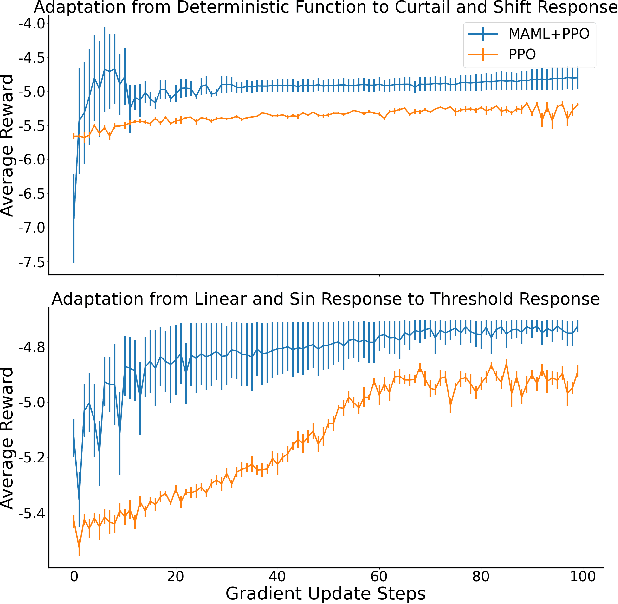
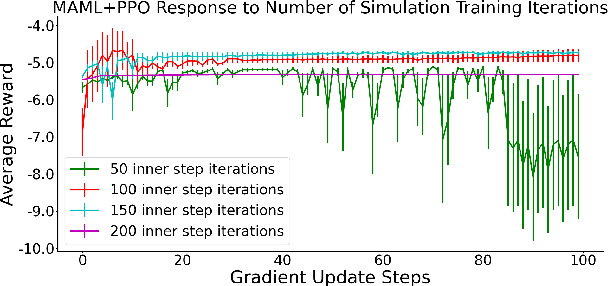
Our team is proposing to run a full-scale energy demand response experiment in an office building. Although this is an exciting endeavor which will provide value to the community, collecting training data for the reinforcement learning agent is costly and will be limited. In this work, we apply a meta-learning architecture to warm start the experiment with simulated tasks, to increase sample efficiency. We present results that demonstrate a similar a step up in complexity still corresponds with better learning.