 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResults of the 2024 CommonRoad Motion Planning Competition for Autonomous Vehicles
Dec 22, 2025


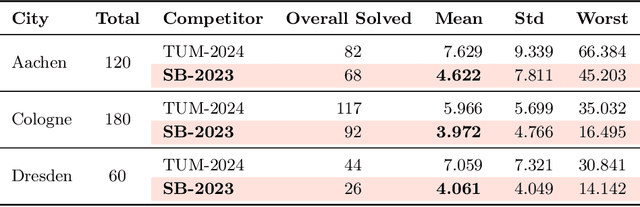
Over the past decade, a wide range of motion planning approaches for autonomous vehicles has been developed to handle increasingly complex traffic scenarios. However, these approaches are rarely compared on standardized benchmarks, limiting the assessment of relative strengths and weaknesses. To address this gap, we present the setup and results of the 4th CommonRoad Motion Planning Competition held in 2024, conducted using the CommonRoad benchmark suite. This annual competition provides an open-source and reproducible framework for benchmarking motion planning algorithms. The benchmark scenarios span highway and urban environments with diverse traffic participants, including passenger cars, buses, and bicycles. Planner performance is evaluated along four dimensions: efficiency, safety, comfort, and compliance with selected traffic rules. This report introduces the competition format and provides a comparison of representative high-performing planners from the 2023 and 2024 editions.
Safe Continual Domain Adaptation after Sim2Real Transfer of Reinforcement Learning Policies in Robotics
Mar 13, 2025Domain randomization has emerged as a fundamental technique in reinforcement learning (RL) to facilitate the transfer of policies from simulation to real-world robotic applications. Many existing domain randomization approaches have been proposed to improve robustness and sim2real transfer. These approaches rely on wide randomization ranges to compensate for the unknown actual system parameters, leading to robust but inefficient real-world policies. In addition, the policies pretrained in the domain-randomized simulation are fixed after deployment due to the inherent instability of the optimization processes based on RL and the necessity of sampling exploitative but potentially unsafe actions on the real system. This limits the adaptability of the deployed policy to the inevitably changing system parameters or environment dynamics over time. We leverage safe RL and continual learning under domain-randomized simulation to address these limitations and enable safe deployment-time policy adaptation in real-world robot control. The experiments show that our method enables the policy to adapt and fit to the current domain distribution and environment dynamics of the real system while minimizing safety risks and avoiding issues like catastrophic forgetting of the general policy found in randomized simulation during the pretraining phase. Videos and supplementary material are available at https://safe-cda.github.io/.