 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Continual Domain Adaptation after Sim2Real Transfer of Reinforcement Learning Policies in Robotics
Mar 13, 2025Domain randomization has emerged as a fundamental technique in reinforcement learning (RL) to facilitate the transfer of policies from simulation to real-world robotic applications. Many existing domain randomization approaches have been proposed to improve robustness and sim2real transfer. These approaches rely on wide randomization ranges to compensate for the unknown actual system parameters, leading to robust but inefficient real-world policies. In addition, the policies pretrained in the domain-randomized simulation are fixed after deployment due to the inherent instability of the optimization processes based on RL and the necessity of sampling exploitative but potentially unsafe actions on the real system. This limits the adaptability of the deployed policy to the inevitably changing system parameters or environment dynamics over time. We leverage safe RL and continual learning under domain-randomized simulation to address these limitations and enable safe deployment-time policy adaptation in real-world robot control. The experiments show that our method enables the policy to adapt and fit to the current domain distribution and environment dynamics of the real system while minimizing safety risks and avoiding issues like catastrophic forgetting of the general policy found in randomized simulation during the pretraining phase. Videos and supplementary material are available at https://safe-cda.github.io/.
Continual Domain Randomization
Mar 18, 2024Domain Randomization (DR) is commonly used for sim2real transfer of reinforcement learning (RL) policies in robotics. Most DR approaches require a simulator with a fixed set of tunable parameters from the start of the training, from which the parameters are randomized simultaneously to train a robust model for use in the real world. However, the combined randomization of many parameters increases the task difficulty and might result in sub-optimal policies. To address this problem and to provide a more flexible training process, we propose Continual Domain Randomization (CDR) for RL that combines domain randomization with continual learning to enable sequential training in simulation on a subset of randomization parameters at a time. Starting from a model trained in a non-randomized simulation where the task is easier to solve, the model is trained on a sequence of randomizations, and continual learning is employed to remember the effects of previous randomizations. Our robotic reaching and grasping tasks experiments show that the model trained in this fashion learns effectively in simulation and performs robustly on the real robot while matching or outperforming baselines that employ combined randomization or sequential randomization without continual learning. Our code and videos are available at https://continual-dr.github.io/.
Representation Abstractions as Incentives for Reinforcement Learning Agents: A Robotic Grasping Case Study
Sep 22, 2023



Choosing an appropriate representation of the environment for the underlying decision-making process of the RL agent is not always straightforward. The state representation should be inclusive enough to allow the agent to informatively decide on its actions and compact enough to increase sample efficiency for policy training. Given this outlook, this work examines the effect of various state representations in incentivizing the agent to solve a specific robotic task: antipodal and planar object grasping. A continuum of state representation abstractions is defined, starting from a model-based approach with complete system knowledge, through hand-crafted numerical, to image-based representations with decreasing level of induced task-specific knowledge. We examine the effects of each representation in the ability of the agent to solve the task in simulation and the transferability of the learned policy to the real robot. The results show that RL agents using numerical states can perform on par with non-learning baselines. Furthermore, we find that agents using image-based representations from pre-trained environment embedding vectors perform better than end-to-end trained agents, and hypothesize that task-specific knowledge is necessary for achieving convergence and high success rates in robot control.
DiAReL: Reinforcement Learning with Disturbance Awareness for Robust Sim2Real Policy Transfer in Robot Control
Jun 15, 2023Delayed Markov decision processes fulfill the Markov property by augmenting the state space of agents with a finite time window of recently committed actions. In reliance with these state augmentations, delay-resolved reinforcement learning algorithms train policies to learn optimal interactions with environments featured with observation or action delays. Although such methods can directly be trained on the real robots, due to sample inefficiency, limited resources or safety constraints, a common approach is to transfer models trained in simulation to the physical robot. However, robotic simulations rely on approximated models of the physical systems, which hinders the sim2real transfer. In this work, we consider various uncertainties in the modelling of the robot's dynamics as unknown intrinsic disturbances applied on the system input. We introduce a disturbance-augmented Markov decision process in delayed settings as a novel representation to incorporate disturbance estimation in training on-policy reinforcement learning algorithms. The proposed method is validated across several metrics on learning a robotic reaching task and compared with disturbance-unaware baselines. The results show that the disturbance-augmented models can achieve higher stabilization and robustness in the control response, which in turn improves the prospects of successful sim2real transfer.
Analysis of Randomization Effects on Sim2Real Transfer in Reinforcement Learning for Robotic Manipulation Tasks
Jun 13, 2022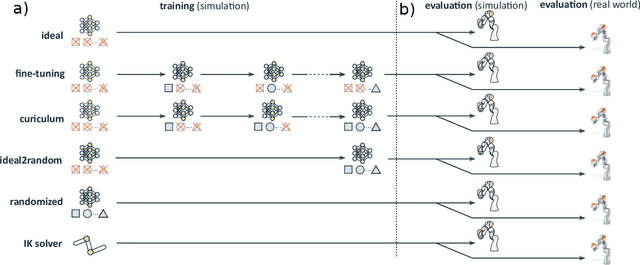
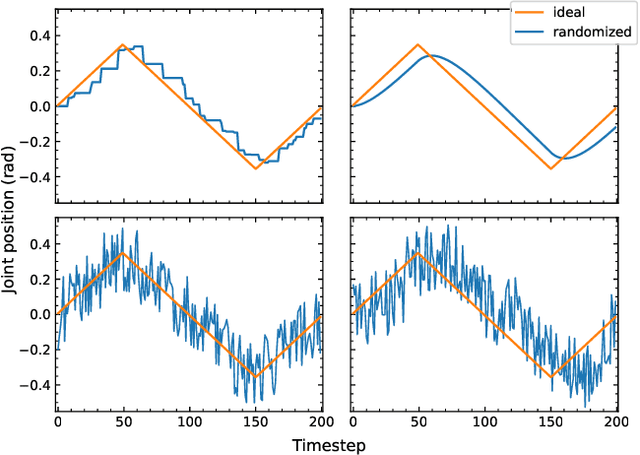

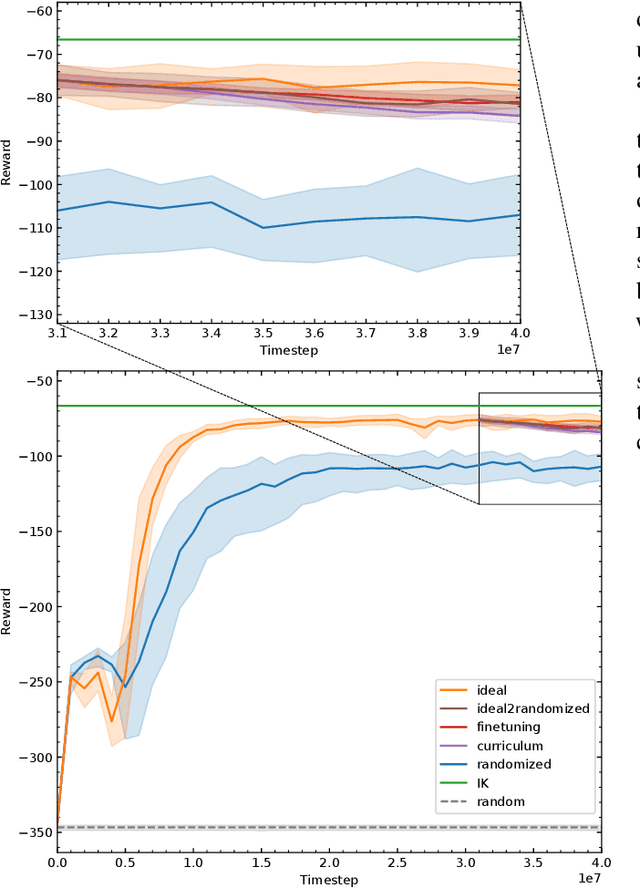
Randomization is currently a widely used approach in Sim2Real transfer for data-driven learning algorithms in robotics. Still, most Sim2Real studies report results for a specific randomization technique and often on a highly customized robotic system, making it difficult to evaluate different randomization approaches systematically. To address this problem, we define an easy-to-reproduce experimental setup for a robotic reach-and-balance manipulator task, which can serve as a benchmark for comparison. We compare four randomization strategies with three randomized parameters both in simulation and on a real robot. Our results show that more randomization helps in Sim2Real transfer, yet it can also harm the ability of the algorithm to find a good policy in simulation. Fully randomized simulations and fine-tuning show differentiated results and translate better to the real robot than the other approaches tested.
Visuo-Haptic Object Perception for Robots: An Overview
Mar 22, 2022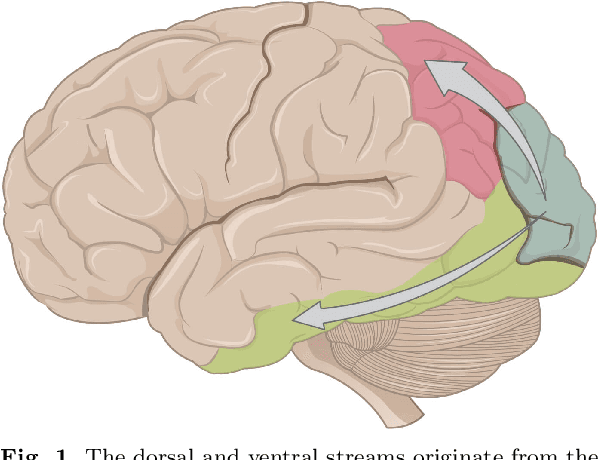
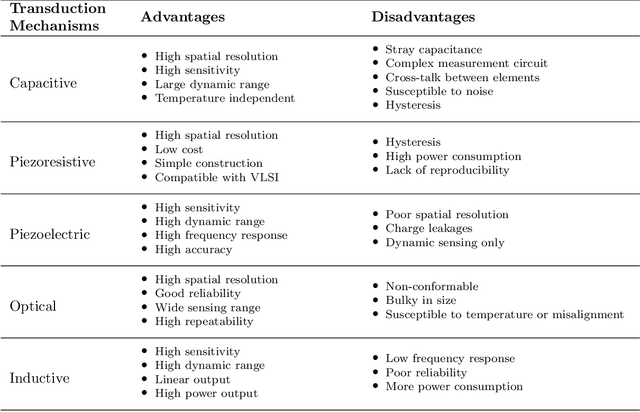


This article summarizes the current state of multimodal object perception for robotic applications. It covers aspects of biological inspiration, sensor technologies, data sets, and sensory data processing for object recognition and grasping. Firstly, the biological basis of multimodal object perception is outlined. Then the sensing technologies and data collection strategies are discussed. Next, an introduction to the main computational aspects is presented, highlighting a few representative articles for each main application area, including object recognition, object manipulation and grasping, texture recognition, and transfer learning. Finally, informed by the current advancements in each area, this article outlines promising new research directions.
Graph Neural Networks for Relational Inductive Bias in Vision-based Deep Reinforcement Learning of Robot Control
Mar 11, 2022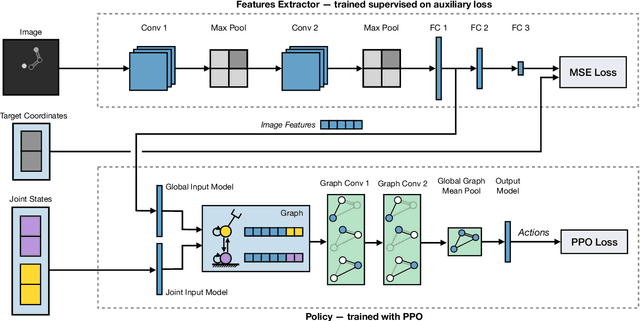
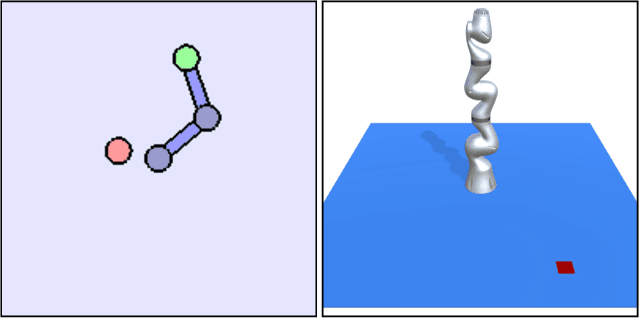
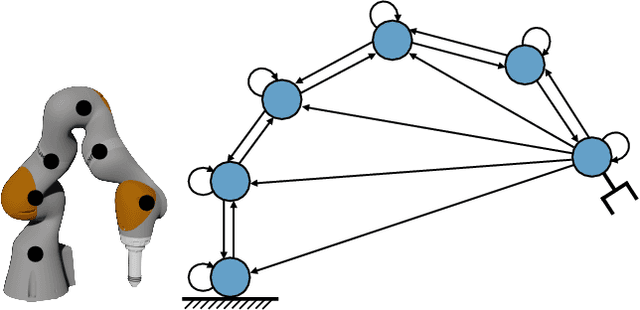
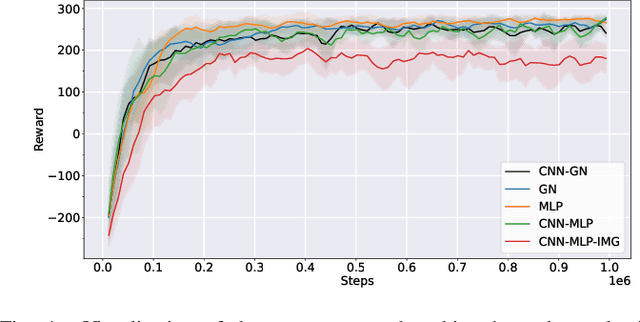
State-of-the-art reinforcement learning algorithms predominantly learn a policy from either a numerical state vector or images. Both approaches generally do not take structural knowledge of the task into account, which is especially prevalent in robotic applications and can benefit learning if exploited. This work introduces a neural network architecture that combines relational inductive bias and visual feedback to learn an efficient position control policy for robotic manipulation. We derive a graph representation that models the physical structure of the manipulator and combines the robot's internal state with a low-dimensional description of the visual scene generated by an image encoding network. On this basis, a graph neural network trained with reinforcement learning predicts joint velocities to control the robot. We further introduce an asymmetric approach of training the image encoder separately from the policy using supervised learning. Experimental results demonstrate that, for a 2-DoF planar robot in a geometrically simplistic 2D environment, a learned representation of the visual scene can replace access to the explicit coordinates of the reaching target without compromising on the quality and sample efficiency of the policy. We further show the ability of the model to improve sample efficiency for a 6-DoF robot arm in a visually realistic 3D environment.