 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Production Scheduling Framework for Reinforcement Learning Under Real-World Constraints
Jun 16, 2025The classical Job Shop Scheduling Problem (JSSP) focuses on optimizing makespan under deterministic constraints. Real-world production environments introduce additional complexities that cause traditional scheduling approaches to be less effective. Reinforcement learning (RL) holds potential in addressing these challenges, as it allows agents to learn adaptive scheduling strategies. However, there is a lack of a comprehensive, general-purpose frameworks for effectively training and evaluating RL agents under real-world constraints. To address this gap, we propose a modular framework that extends classical JSSP formulations by incorporating key \mbox{real-world} constraints inherent to the shopfloor, including transport logistics, buffer management, machine breakdowns, setup times, and stochastic processing conditions, while also supporting multi-objective optimization. The framework is a customizable solution that offers flexibility in defining problem instances and configuring simulation parameters, enabling adaptation to diverse production scenarios. A standardized interface ensures compatibility with various RL approaches, providing a robust environment for training RL agents and facilitating the standardized comparison of different scheduling methods under dynamic and uncertain conditions. We release JobShopLab as an open-source tool for both research and industrial applications, accessible at: https://github.com/proto-lab-ro/jobshoplab
AI-Driven Multi-Stage Computer Vision System for Defect Detection in Laser-Engraved Industrial Nameplates
Mar 05, 2025Automated defect detection in industrial manufacturing is essential for maintaining product quality and minimizing production errors. In air disc brake manufacturing, ensuring the precision of laser-engraved nameplates is crucial for accurate product identification and quality control. Engraving errors, such as misprints or missing characters, can compromise both aesthetics and functionality, leading to material waste and production delays. This paper presents a proof of concept for an AI-driven computer vision system that inspects and verifies laser-engraved nameplates, detecting defects in logos and alphanumeric strings. The system integrates object detection using YOLOv7, optical character recognition (OCR) with Tesseract, and anomaly detection through a residual variational autoencoder (ResVAE) along with other computer vision methods to enable comprehensive inspections at multiple stages. Experimental results demonstrate the system's effectiveness, achieving 91.33% accuracy and 100% recall, ensuring that defective nameplates are consistently detected and addressed. This solution highlights the potential of AI-driven visual inspection to enhance quality control, reduce manual inspection efforts, and improve overall manufacturing efficiency.
Optimizing Job Shop Scheduling in the Furniture Industry: A Reinforcement Learning Approach Considering Machine Setup, Batch Variability, and Intralogistics
Sep 18, 2024This paper explores the potential application of Deep Reinforcement Learning in the furniture industry. To offer a broad product portfolio, most furniture manufacturers are organized as a job shop, which ultimately results in the Job Shop Scheduling Problem (JSSP). The JSSP is addressed with a focus on extending traditional models to better represent the complexities of real-world production environments. Existing approaches frequently fail to consider critical factors such as machine setup times or varying batch sizes. A concept for a model is proposed that provides a higher level of information detail to enhance scheduling accuracy and efficiency. The concept introduces the integration of DRL for production planning, particularly suited to batch production industries such as the furniture industry. The model extends traditional approaches to JSSPs by including job volumes, buffer management, transportation times, and machine setup times. This enables more precise forecasting and analysis of production flows and processes, accommodating the variability and complexity inherent in real-world manufacturing processes. The RL agent learns to optimize scheduling decisions. It operates within a discrete action space, making decisions based on detailed observations. A reward function guides the agent's decision-making process, thereby promoting efficient scheduling and meeting production deadlines. Two integration strategies for implementing the RL agent are discussed: episodic planning, which is suitable for low-automation environments, and continuous planning, which is ideal for highly automated plants. While episodic planning can be employed as a standalone solution, the continuous planning approach necessitates the integration of the agent with ERP and Manufacturing Execution Systems. This integration enables real-time adjustments to production schedules based on dynamic changes.
Manufacturing Quality Control with Autoencoder-Based Defect Localization and Unsupervised Class Selection
Sep 13, 2023



Manufacturing industries require efficient and voluminous production of high-quality finished goods. In the context of Industry 4.0, visual anomaly detection poses an optimistic solution for automatically controlling product quality with high precision. Automation based on computer vision poses a promising solution to prevent bottlenecks at the product quality checkpoint. We considered recent advancements in machine learning to improve visual defect localization, but challenges persist in obtaining a balanced feature set and database of the wide variety of defects occurring in the production line. This paper proposes a defect localizing autoencoder with unsupervised class selection by clustering with k-means the features extracted from a pre-trained VGG-16 network. The selected classes of defects are augmented with natural wild textures to simulate artificial defects. The study demonstrates the effectiveness of the defect localizing autoencoder with unsupervised class selection for improving defect detection in manufacturing industries. The proposed methodology shows promising results with precise and accurate localization of quality defects on melamine-faced boards for the furniture industry. Incorporating artificial defects into the training data shows significant potential for practical implementation in real-world quality control scenarios.
DiAReL: Reinforcement Learning with Disturbance Awareness for Robust Sim2Real Policy Transfer in Robot Control
Jun 15, 2023Delayed Markov decision processes fulfill the Markov property by augmenting the state space of agents with a finite time window of recently committed actions. In reliance with these state augmentations, delay-resolved reinforcement learning algorithms train policies to learn optimal interactions with environments featured with observation or action delays. Although such methods can directly be trained on the real robots, due to sample inefficiency, limited resources or safety constraints, a common approach is to transfer models trained in simulation to the physical robot. However, robotic simulations rely on approximated models of the physical systems, which hinders the sim2real transfer. In this work, we consider various uncertainties in the modelling of the robot's dynamics as unknown intrinsic disturbances applied on the system input. We introduce a disturbance-augmented Markov decision process in delayed settings as a novel representation to incorporate disturbance estimation in training on-policy reinforcement learning algorithms. The proposed method is validated across several metrics on learning a robotic reaching task and compared with disturbance-unaware baselines. The results show that the disturbance-augmented models can achieve higher stabilization and robustness in the control response, which in turn improves the prospects of successful sim2real transfer.
A Reinforcement Learning Approach for Scheduling Problems With Improved Generalization Through Order Swapping
Mar 06, 2023The scheduling of production resources (such as associating jobs to machines) plays a vital role for the manufacturing industry not only for saving energy but also for increasing the overall efficiency. Among the different job scheduling problems, the JSSP is addressed in this work. JSSP falls into the category of NP-hard COP, in which solving the problem through exhaustive search becomes unfeasible. Simple heuristics such as FIFO, LPT and metaheuristics such as Taboo search are often adopted to solve the problem by truncating the search space. The viability of the methods becomes inefficient for large problem sizes as it is either far from the optimum or time consuming. In recent years, the research towards using DRL to solve COP has gained interest and has shown promising results in terms of solution quality and computational efficiency. In this work, we provide an novel approach to solve the JSSP examining the objectives generalization and solution effectiveness using DRL. In particular, we employ the PPO algorithm that adopts the policy-gradient paradigm that is found to perform well in the constrained dispatching of jobs. We incorporated an OSM in the environment to achieve better generalized learning of the problem. The performance of the presented approach is analyzed in depth by using a set of available benchmark instances and comparing our results with the work of other groups.
Analysis of Randomization Effects on Sim2Real Transfer in Reinforcement Learning for Robotic Manipulation Tasks
Jun 13, 2022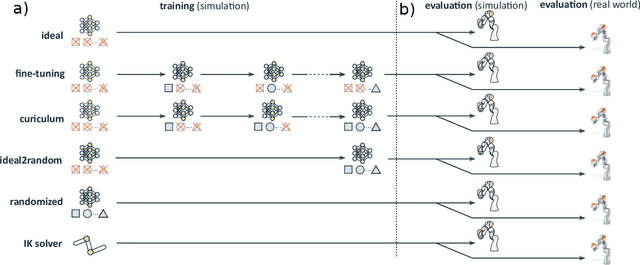
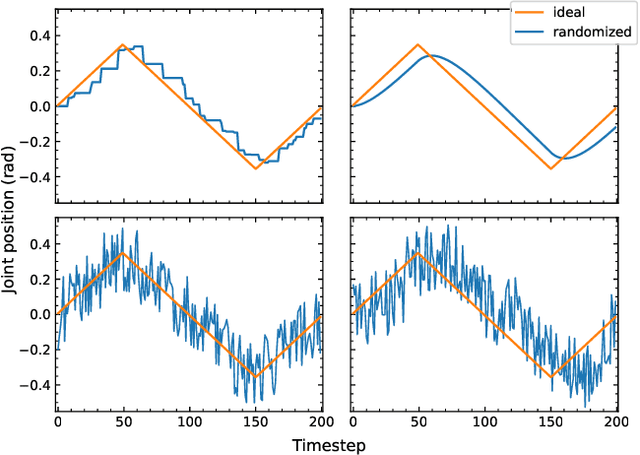

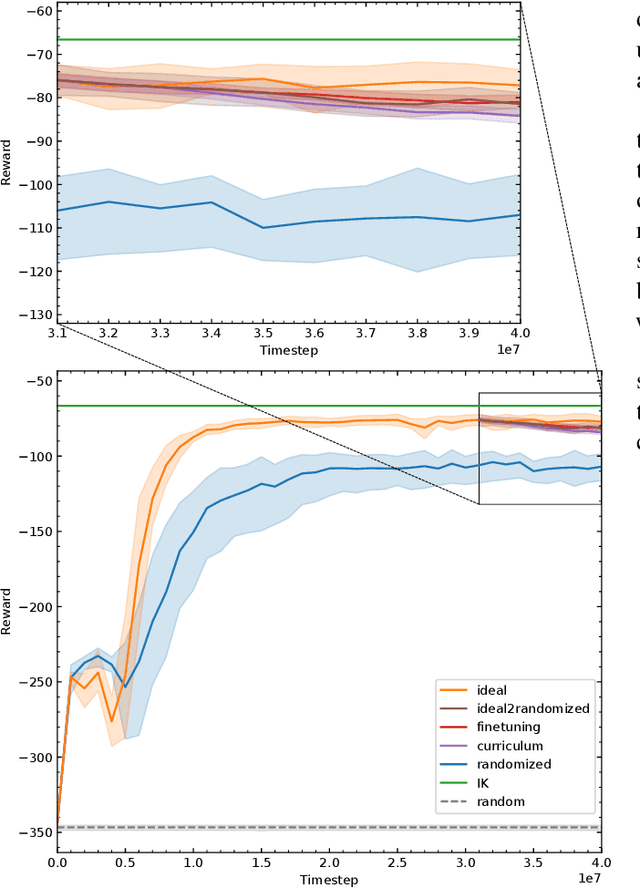
Randomization is currently a widely used approach in Sim2Real transfer for data-driven learning algorithms in robotics. Still, most Sim2Real studies report results for a specific randomization technique and often on a highly customized robotic system, making it difficult to evaluate different randomization approaches systematically. To address this problem, we define an easy-to-reproduce experimental setup for a robotic reach-and-balance manipulator task, which can serve as a benchmark for comparison. We compare four randomization strategies with three randomized parameters both in simulation and on a real robot. Our results show that more randomization helps in Sim2Real transfer, yet it can also harm the ability of the algorithm to find a good policy in simulation. Fully randomized simulations and fine-tuning show differentiated results and translate better to the real robot than the other approaches tested.
Artificial Intelligence Narratives: An Objective Perspective on Current Developments
Mar 18, 2021

This work provides a starting point for researchers interested in gaining a deeper understanding of the big picture of artificial intelligence (AI). To this end, a narrative is conveyed that allows the reader to develop an objective view on current developments that is free from false promises that dominate public communication. An essential takeaway for the reader is that AI must be understood as an umbrella term encompassing a plethora of different methods, schools of thought, and their respective historical movements. Consequently, a bottom-up strategy is pursued in which the field of AI is introduced by presenting various aspects that are characteristic of the subject. This paper is structured in three parts: (i) Discussion of current trends revealing false public narratives, (ii) an introduction to the history of AI focusing on recurring patterns and main characteristics, and (iii) a critical discussion on the limitations of current methods in the context of the potential emergence of a strong(er) AI. It should be noted that this work does not cover any of these aspects holistically; rather, the content addressed is a selection made by the author and subject to a didactic strategy.