 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sparsity: Challenging Common Sparsity Assumptions for Learning World Models in Robotic Reinforcement Learning Benchmarks
Nov 14, 2025
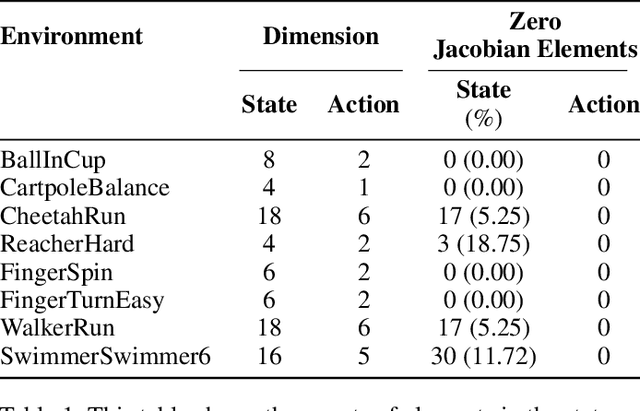

The use of learned dynamics models, also known as world models, can improve the sample efficiency of reinforcement learning. Recent work suggests that the underlying causal graphs of such dynamics models are sparsely connected, with each of the future state variables depending only on a small subset of the current state variables, and that learning may therefore benefit from sparsity priors. Similarly, temporal sparsity, i.e. sparsely and abruptly changing local dynamics, has also been proposed as a useful inductive bias. In this work, we critically examine these assumptions by analyzing ground-truth dynamics from a set of robotic reinforcement learning environments in the MuJoCo Playground benchmark suite, aiming to determine whether the proposed notions of state and temporal sparsity actually tend to hold in typical reinforcement learning tasks. We study (i) whether the causal graphs of environment dynamics are sparse, (ii) whether such sparsity is state-dependent, and (iii) whether local system dynamics change sparsely. Our results indicate that global sparsity is rare, but instead the tasks show local, state-dependent sparsity in their dynamics and this sparsity exhibits distinct structures, appearing in temporally localized clusters (e.g., during contact events) and affecting specific subsets of state dimensions. These findings challenge common sparsity prior assumptions in dynamics learning, emphasizing the need for grounded inductive biases that reflect the state-dependent sparsity structure of real-world dynamics.
Investigating the Benefits of Nonlinear Action Maps in Data-Driven Teleoperation
Oct 28, 2024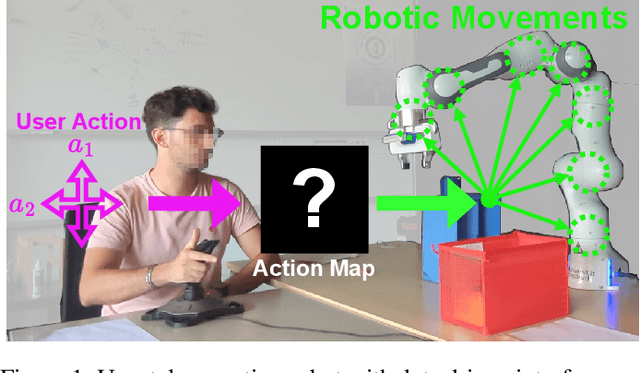

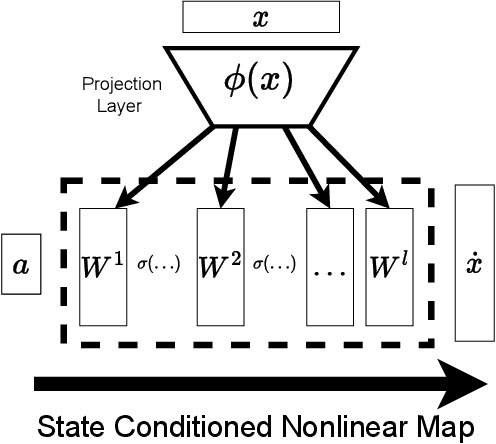

As robots become more common for both able-bodied individuals and those living with a disability, it is increasingly important that lay people be able to drive multi-degree-of-freedom platforms with low-dimensional controllers. One approach is to use state-conditioned action mapping methods to learn mappings between low-dimensional controllers and high DOF manipulators -- prior research suggests these mappings can simplify the teleoperation experience for users. Recent works suggest that neural networks predicting a local linear function are superior to the typical end-to-end multi-layer perceptrons because they allow users to more easily undo actions, providing more control over the system. However, local linear models assume actions exist on a linear subspace and may not capture nuanced actions in training data. We observe that the benefit of these mappings is being an odd function concerning user actions, and propose end-to-end nonlinear action maps which achieve this property. Unfortunately, our experiments show that such modifications offer minimal advantages over previous solutions. We find that nonlinear odd functions behave linearly for most of the control space, suggesting architecture structure improvements are not the primary factor in data-driven teleoperation. Our results suggest other avenues, such as data augmentation techniques and analysis of human behavior, are necessary for action maps to become practical in real-world applications, such as in assistive robotics to improve the quality of life of people living with w disability.
Direct Imitation Learning-based Visual Servoing using the Large Projection Formulation
Jun 13, 2024


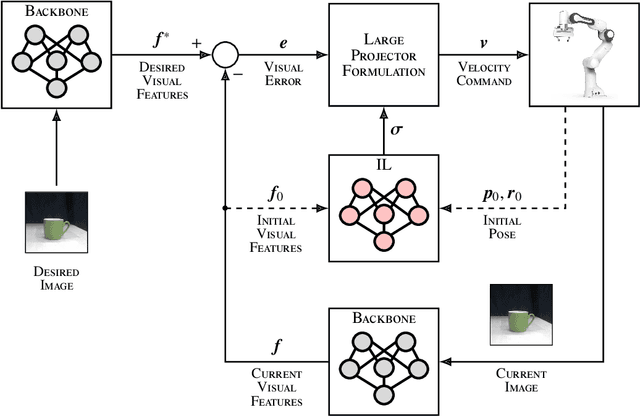
Today robots must be safe, versatile, and user-friendly to operate in unstructured and human-populated environments. Dynamical system-based imitation learning enables robots to perform complex tasks stably and without explicit programming, greatly simplifying their real-world deployment. To exploit the full potential of these systems it is crucial to implement closed loops that use visual feedback. Vision permits to cope with environmental changes, but is complex to handle due to the high dimension of the image space. This study introduces a dynamical system-based imitation learning for direct visual servoing. It leverages off-the-shelf deep learning-based perception backbones to extract robust features from the raw input image, and an imitation learning strategy to execute sophisticated robot motions. The learning blocks are integrated using the large projection task priority formulation. As demonstrated through extensive experimental analysis, the proposed method realizes complex tasks with a robotic manipulator.
Unsupervised Learning of Effective Actions in Robotics
Apr 03, 2024



Learning actions that are relevant to decision-making and can be executed effectively is a key problem in autonomous robotics. Current state-of-the-art action representations in robotics lack proper effect-driven learning of the robot's actions. Although successful in solving manipulation tasks, deep learning methods also lack this ability, in addition to their high cost in terms of memory or training data. In this paper, we propose an unsupervised algorithm to discretize a continuous motion space and generate "action prototypes", each producing different effects in the environment. After an exploration phase, the algorithm automatically builds a representation of the effects and groups motions into action prototypes, where motions more likely to produce an effect are represented more than those that lead to negligible changes. We evaluate our method on a simulated stair-climbing reinforcement learning task, and the preliminary results show that our effect driven discretization outperforms uniformly and randomly sampled discretizations in convergence speed and maximum reward.
Continual Domain Randomization
Mar 18, 2024Domain Randomization (DR) is commonly used for sim2real transfer of reinforcement learning (RL) policies in robotics. Most DR approaches require a simulator with a fixed set of tunable parameters from the start of the training, from which the parameters are randomized simultaneously to train a robust model for use in the real world. However, the combined randomization of many parameters increases the task difficulty and might result in sub-optimal policies. To address this problem and to provide a more flexible training process, we propose Continual Domain Randomization (CDR) for RL that combines domain randomization with continual learning to enable sequential training in simulation on a subset of randomization parameters at a time. Starting from a model trained in a non-randomized simulation where the task is easier to solve, the model is trained on a sequence of randomizations, and continual learning is employed to remember the effects of previous randomizations. Our robotic reaching and grasping tasks experiments show that the model trained in this fashion learns effectively in simulation and performs robustly on the real robot while matching or outperforming baselines that employ combined randomization or sequential randomization without continual learning. Our code and videos are available at https://continual-dr.github.io/.
Effect of Optimizer, Initializer, and Architecture of Hypernetworks on Continual Learning from Demonstration
Dec 31, 2023In continual learning from demonstration (CLfD), a robot learns a sequence of real-world motion skills continually from human demonstrations. Recently, hypernetworks have been successful in solving this problem. In this paper, we perform an exploratory study of the effects of different optimizers, initializers, and network architectures on the continual learning performance of hypernetworks for CLfD. Our results show that adaptive learning rate optimizers work well, but initializers specially designed for hypernetworks offer no advantages for CLfD. We also show that hypernetworks that are capable of stable trajectory predictions are robust to different network architectures. Our open-source code is available at https://github.com/sebastianbergner/ExploringCLFD.
Unified Task and Motion Planning using Object-centric Abstractions of Motion Constraints
Dec 29, 2023In task and motion planning (TAMP), the ambiguity and underdetermination of abstract descriptions used by task planning methods make it difficult to characterize physical constraints needed to successfully execute a task. The usual approach is to overlook such constraints at task planning level and to implement expensive sub-symbolic geometric reasoning techniques that perform multiple calls on unfeasible actions, plan corrections, and re-planning until a feasible solution is found. We propose an alternative TAMP approach that unifies task and motion planning into a single heuristic search. Our approach is based on an object-centric abstraction of motion constraints that permits leveraging the computational efficiency of off-the-shelf AI heuristic search to yield physically feasible plans. These plans can be directly transformed into object and motion parameters for task execution without the need of intensive sub-symbolic geometric reasoning.
Colored Noise in PPO: Improved Exploration and Performance Through Correlated Action Sampling
Dec 18, 2023
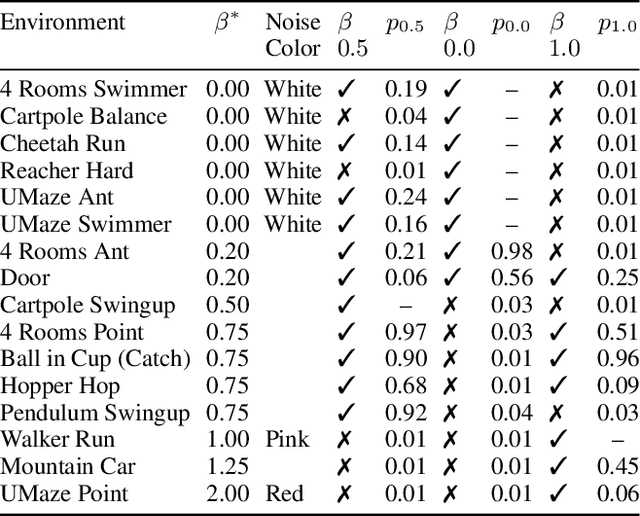


Proximal Policy Optimization (PPO), a popular on-policy deep reinforcement learning method, employs a stochastic policy for exploration. In this paper, we propose a colored noise-based stochastic policy variant of PPO. Previous research highlighted the importance of temporal correlation in action noise for effective exploration in off-policy reinforcement learning. Building on this, we investigate whether correlated noise can also enhance exploration in on-policy methods like PPO. We discovered that correlated noise for action selection improves learning performance and outperforms the currently popular uncorrelated white noise approach in on-policy methods. Unlike off-policy learning, where pink noise was found to be highly effective, we found that a colored noise, intermediate between white and pink, performed best for on-policy learning in PPO. We examined the impact of varying the amount of data collected for each update by modifying the number of parallel simulation environments for data collection and observed that with a larger number of parallel environments, more strongly correlated noise is beneficial. Due to the significant impact and ease of implementation, we recommend switching to correlated noise as the default noise source in PPO.
Regularity as Intrinsic Reward for Free Play
Dec 03, 2023We propose regularity as a novel reward signal for intrinsically-motivated reinforcement learning. Taking inspiration from child development, we postulate that striving for structure and order helps guide exploration towards a subspace of tasks that are not favored by naive uncertainty-based intrinsic rewards. Our generalized formulation of Regularity as Intrinsic Reward (RaIR) allows us to operationalize it within model-based reinforcement learning. In a synthetic environment, we showcase the plethora of structured patterns that can emerge from pursuing this regularity objective. We also demonstrate the strength of our method in a multi-object robotic manipulation environment. We incorporate RaIR into free play and use it to complement the model's epistemic uncertainty as an intrinsic reward. Doing so, we witness the autonomous construction of towers and other regular structures during free play, which leads to a substantial improvement in zero-shot downstream task performance on assembly tasks.
Scalable and Efficient Continual Learning from Demonstration via Hypernetwork-generated Stable Dynamics Model
Nov 06, 2023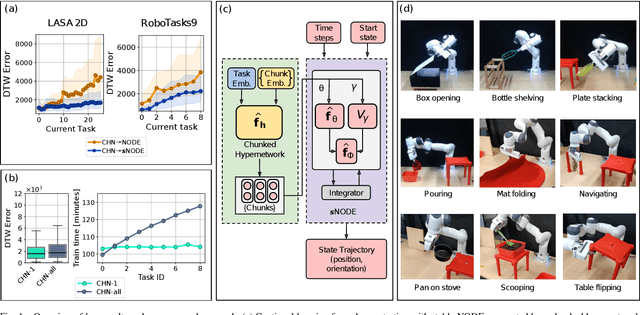
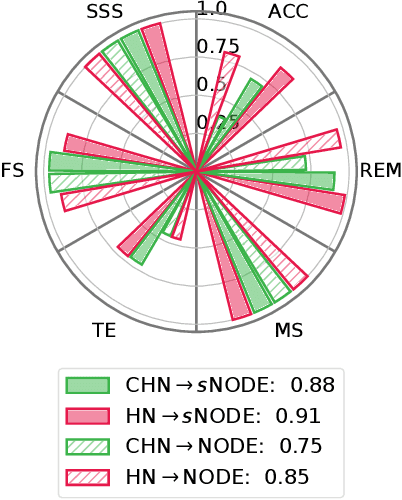
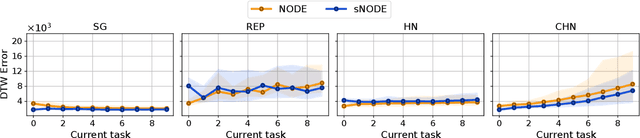
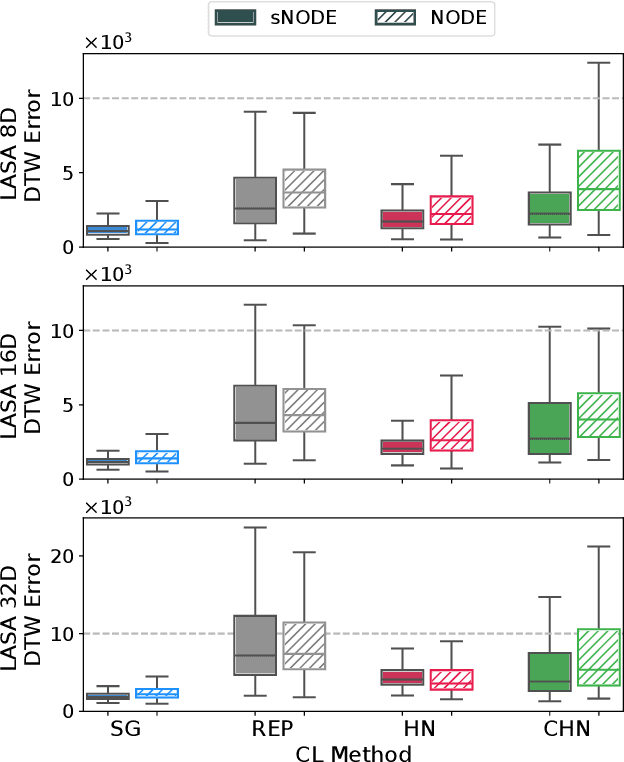
Learning from demonstration (LfD) provides an efficient way to train robots. The learned motions should be convergent and stable, but to be truly effective in the real world, LfD-capable robots should also be able to remember multiple motion skills. Multi-skill retention is a capability missing from existing stable-LfD approaches. On the other hand, recent work on continual-LfD has shown that hypernetwork-generated neural ordinary differential equation solvers, can learn multiple LfD tasks sequentially, but this approach lacks stability guarantees. We propose an approach for stable continual-LfD in which a hypernetwork generates two networks: a trajectory learning dynamics model, and a trajectory stabilizing Lyapunov function. The introduction of stability not only generates stable trajectories but also greatly improves continual learning performance, especially in the size-efficient chunked hypernetworks. With our approach, we can continually train a single model to predict the position and orientation trajectories of the robot's end-effector simultaneously for multiple real world tasks without retraining on past demonstrations. We also propose stochastic regularization with a single randomly sampled regularization term in hypernetworks, which reduces the cumulative training time cost for $N$ tasks from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$ without any loss in performance in real-world tasks. We empirically evaluate our approach on the popular LASA dataset, on high-dimensional extensions of LASA (including up to 32 dimensions) to assess scalability, and on a novel extended robotic task dataset (RoboTasks9) to assess real-world performance. In trajectory error metrics, stability metrics and continual learning metrics our approach performs favorably, compared to other baselines. Code and datasets will be shared after submission.