 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Sparsity: Challenging Common Sparsity Assumptions for Learning World Models in Robotic Reinforcement Learning Benchmarks
Nov 14, 2025
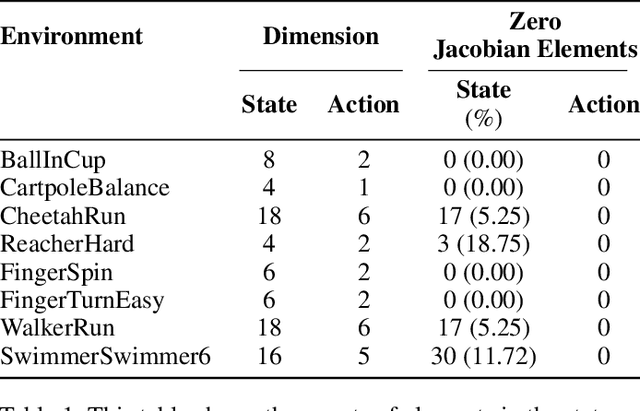

The use of learned dynamics models, also known as world models, can improve the sample efficiency of reinforcement learning. Recent work suggests that the underlying causal graphs of such dynamics models are sparsely connected, with each of the future state variables depending only on a small subset of the current state variables, and that learning may therefore benefit from sparsity priors. Similarly, temporal sparsity, i.e. sparsely and abruptly changing local dynamics, has also been proposed as a useful inductive bias. In this work, we critically examine these assumptions by analyzing ground-truth dynamics from a set of robotic reinforcement learning environments in the MuJoCo Playground benchmark suite, aiming to determine whether the proposed notions of state and temporal sparsity actually tend to hold in typical reinforcement learning tasks. We study (i) whether the causal graphs of environment dynamics are sparse, (ii) whether such sparsity is state-dependent, and (iii) whether local system dynamics change sparsely. Our results indicate that global sparsity is rare, but instead the tasks show local, state-dependent sparsity in their dynamics and this sparsity exhibits distinct structures, appearing in temporally localized clusters (e.g., during contact events) and affecting specific subsets of state dimensions. These findings challenge common sparsity prior assumptions in dynamics learning, emphasizing the need for grounded inductive biases that reflect the state-dependent sparsity structure of real-world dynamics.
Vision Transformers for Weakly-Supervised Microorganism Enumeration
Dec 03, 2024Microorganism enumeration is an essential task in many applications, such as assessing contamination levels or ensuring health standards when evaluating surface cleanliness. However, it's traditionally performed by human-supervised methods that often require manual counting, making it tedious and time-consuming. Previous research suggests automating this task using computer vision and machine learning methods, primarily through instance segmentation or density estimation techniques. This study conducts a comparative analysis of vision transformers (ViTs) for weakly-supervised counting in microorganism enumeration, contrasting them with traditional architectures such as ResNet and investigating ViT-based models such as TransCrowd. We trained different versions of ViTs as the architectural backbone for feature extraction using four microbiology datasets to determine potential new approaches for total microorganism enumeration in images. Results indicate that while ResNets perform better overall, ViTs performance demonstrates competent results across all datasets, opening up promising lines of research in microorganism enumeration. This comparative study contributes to the field of microbial image analysis by presenting innovative approaches to the recurring challenge of microorganism enumeration and by highlighting the capabilities of ViTs in the task of regression counting.
Scalable and Efficient Continual Learning from Demonstration via Hypernetwork-generated Stable Dynamics Model
Nov 06, 2023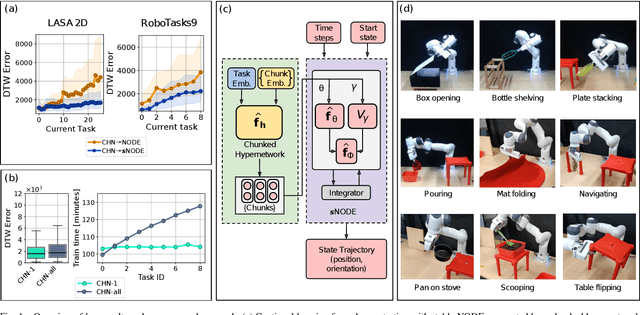
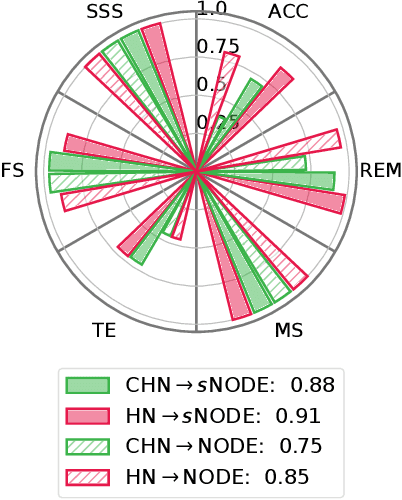
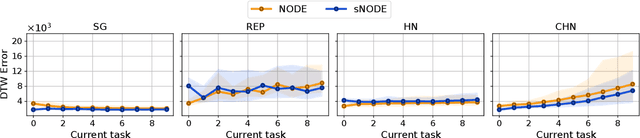
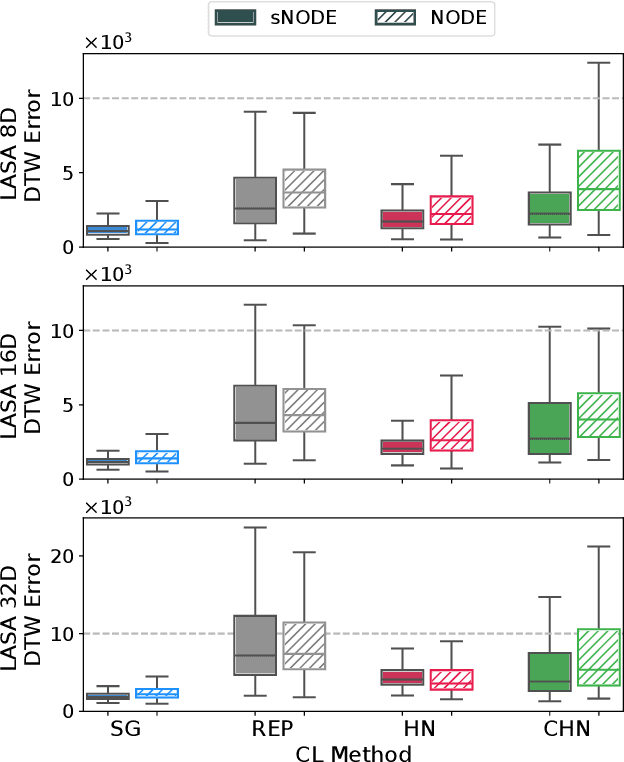
Learning from demonstration (LfD) provides an efficient way to train robots. The learned motions should be convergent and stable, but to be truly effective in the real world, LfD-capable robots should also be able to remember multiple motion skills. Multi-skill retention is a capability missing from existing stable-LfD approaches. On the other hand, recent work on continual-LfD has shown that hypernetwork-generated neural ordinary differential equation solvers, can learn multiple LfD tasks sequentially, but this approach lacks stability guarantees. We propose an approach for stable continual-LfD in which a hypernetwork generates two networks: a trajectory learning dynamics model, and a trajectory stabilizing Lyapunov function. The introduction of stability not only generates stable trajectories but also greatly improves continual learning performance, especially in the size-efficient chunked hypernetworks. With our approach, we can continually train a single model to predict the position and orientation trajectories of the robot's end-effector simultaneously for multiple real world tasks without retraining on past demonstrations. We also propose stochastic regularization with a single randomly sampled regularization term in hypernetworks, which reduces the cumulative training time cost for $N$ tasks from $\mathcal{O}(N^2)$ to $\mathcal{O}(N)$ without any loss in performance in real-world tasks. We empirically evaluate our approach on the popular LASA dataset, on high-dimensional extensions of LASA (including up to 32 dimensions) to assess scalability, and on a novel extended robotic task dataset (RoboTasks9) to assess real-world performance. In trajectory error metrics, stability metrics and continual learning metrics our approach performs favorably, compared to other baselines. Code and datasets will be shared after submission.
Affordance detection with Dynamic-Tree Capsule Networks
Nov 09, 2022



Affordance detection from visual input is a fundamental step in autonomous robotic manipulation. Existing solutions to the problem of affordance detection rely on convolutional neural networks. However, these networks do not consider the spatial arrangement of the input data and miss parts-to-whole relationships. Therefore, they fall short when confronted with novel, previously unseen object instances or new viewpoints. One solution to overcome such limitations can be to resort to capsule networks. In this paper, we introduce the first affordance detection network based on dynamic tree-structured capsules for sparse 3D point clouds. We show that our capsule-based network outperforms current state-of-the-art models on viewpoint invariance and parts-segmentation of new object instances through a novel dataset we only used for evaluation and it is publicly available from github.com/gipfelen/DTCG-Net. In the experimental evaluation we will show that our algorithm is superior to current affordance detection methods when faced with grasping previously unseen objects thanks to our Capsule Network enforcing a parts-to-whole representation.
Improving the Trainability of Deep Neural Networks through Layerwise Batch-Entropy Regularization
Aug 01, 2022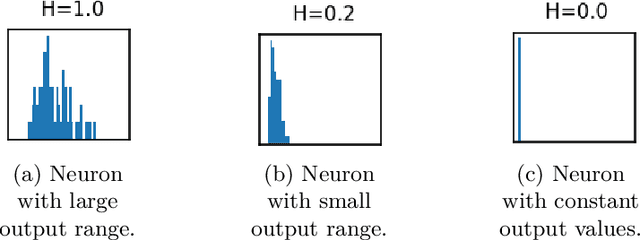
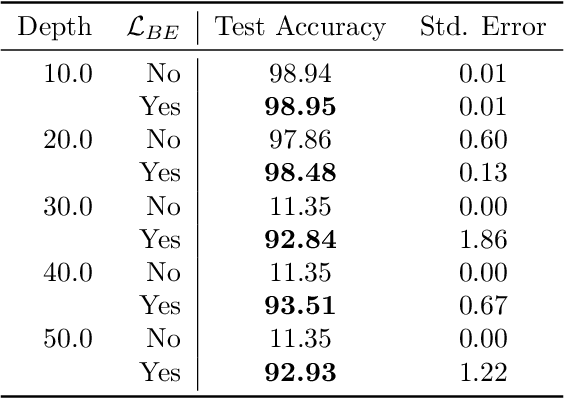
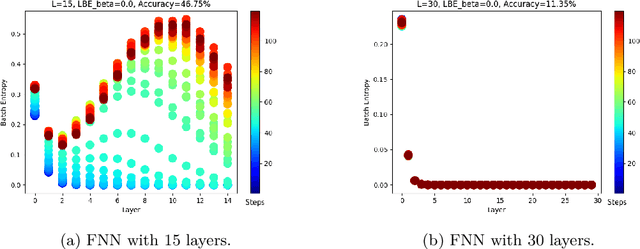
Training deep neural networks is a very demanding task, especially challenging is how to adapt architectures to improve the performance of trained models. We can find that sometimes, shallow networks generalize better than deep networks, and the addition of more layers results in higher training and test errors. The deep residual learning framework addresses this degradation problem by adding skip connections to several neural network layers. It would at first seem counter-intuitive that such skip connections are needed to train deep networks successfully as the expressivity of a network would grow exponentially with depth. In this paper, we first analyze the flow of information through neural networks. We introduce and evaluate the batch-entropy which quantifies the flow of information through each layer of a neural network. We prove empirically and theoretically that a positive batch-entropy is required for gradient descent-based training approaches to optimize a given loss function successfully. Based on those insights, we introduce batch-entropy regularization to enable gradient descent-based training algorithms to optimize the flow of information through each hidden layer individually. With batch-entropy regularization, gradient descent optimizers can transform untrainable networks into trainable networks. We show empirically that we can therefore train a "vanilla" fully connected network and convolutional neural network -- no skip connections, batch normalization, dropout, or any other architectural tweak -- with 500 layers by simply adding the batch-entropy regularization term to the loss function. The effect of batch-entropy regularization is not only evaluated on vanilla neural networks, but also on residual networks, autoencoders, and also transformer models over a wide range of computer vision as well as natural language processing tasks.
Continual Learning from Demonstration of Robotic Skills
Feb 15, 2022

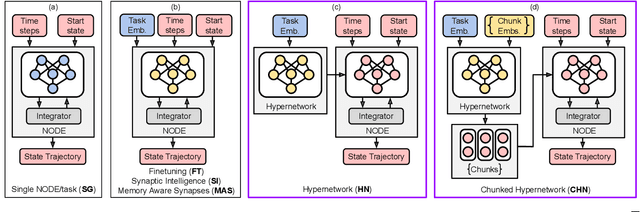
Methods for teaching motion skills to robots focus on training for a single skill at a time. Robots capable of learning from demonstration can considerably benefit from the added ability to learn new movements without forgetting past knowledge. To this end, we propose an approach for continual learning from demonstration using hypernetworks and neural ordinary differential equation solvers. We empirically demonstrate the effectiveness of our approach in remembering long sequences of trajectory learning tasks without the need to store any data from past demonstrations. Our results show that hypernetworks outperform other state-of-the-art regularization-based continual learning approaches for learning from demonstration. In our experiments, we use the popular LASA trajectory benchmark, and a new dataset of kinesthetic demonstrations that we introduce in this paper called the HelloWorld dataset. We evaluate our approach using both trajectory error metrics and continual learning metrics, and we propose two new continual learning metrics. Our code, along with the newly collected dataset, is available at https://github.com/sayantanauddy/clfd.
Momentum Capsule Networks
Jan 26, 2022
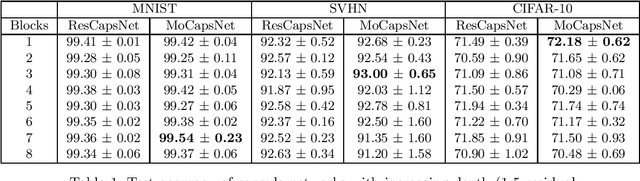
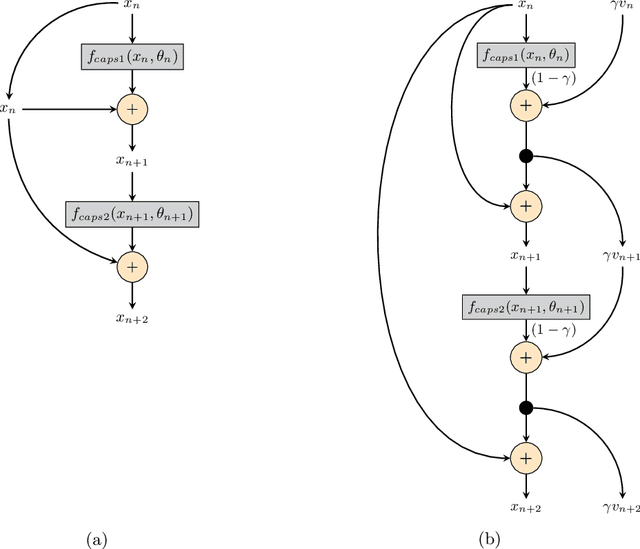
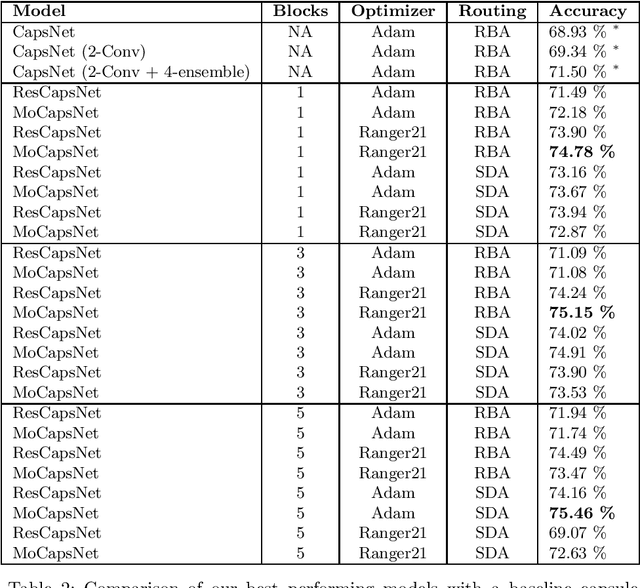
Capsule networks are a class of neural networks that achieved promising results on many computer vision tasks. However, baseline capsule networks have failed to reach state-of-the-art results on more complex datasets due to the high computation and memory requirements. We tackle this problem by proposing a new network architecture, called Momentum Capsule Network (MoCapsNet). MoCapsNets are inspired by Momentum ResNets, a type of network that applies reversible residual building blocks. Reversible networks allow for recalculating activations of the forward pass in the backpropagation algorithm, so those memory requirements can be drastically reduced. In this paper, we provide a framework on how invertible residual building blocks can be applied to capsule networks. We will show that MoCapsNet beats the accuracy of baseline capsule networks on MNIST, SVHN and CIFAR-10 while using considerably less memory. The source code is available on https://github.com/moejoe95/MoCapsNet.
Arguments for the Unsuitability of Convolutional Neural Networks for Non--Local Tasks
Feb 23, 2021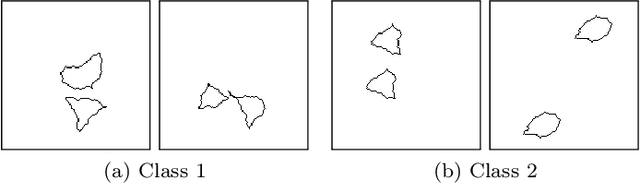
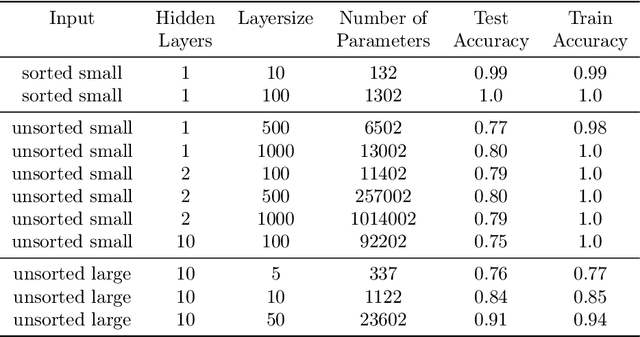
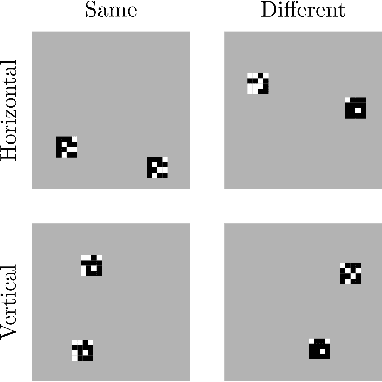
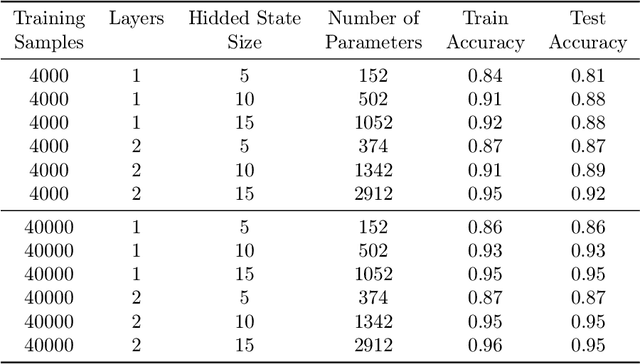
Convolutional neural networks have established themselves over the past years as the state of the art method for image classification, and for many datasets, they even surpass humans in categorizing images. Unfortunately, the same architectures perform much worse when they have to compare parts of an image to each other to correctly classify this image. Until now, no well-formed theoretical argument has been presented to explain this deficiency. In this paper, we will argue that convolutional layers are of little use for such problems, since comparison tasks are global by nature, but convolutional layers are local by design. We will use this insight to reformulate a comparison task into a sorting task and use findings on sorting networks to propose a lower bound for the number of parameters a neural network needs to solve comparison tasks in a generalizable way. We will use this lower bound to argue that attention, as well as iterative/recurrent processing, is needed to prevent a combinatorial explosion.
Evaluating the Progress of Deep Learning for Visual Relational Concepts
Jan 29, 2020
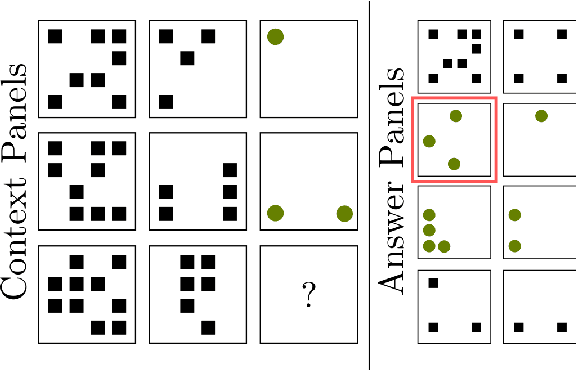
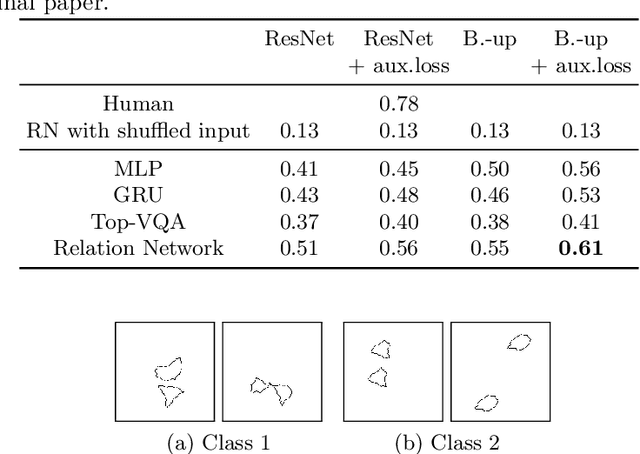
Convolutional Neural Networks (CNNs) have become the state of the art method for image classification in the last 7 years, but despite the fact that they achieve super human performance on many classification datasets, there are lesser known datasets where they almost fail completely and perform much worse than humans. We will show that these problems correspond to relational concepts as defined by the field of concept learning. Therefore, we will present current deep learning research for visual relational concepts. Analyzing the current literature, we will hypothesise that iterative processing of the input, together with shifting attention between the iterations will be needed to efficiently and reliably solve real world relational concept learning. In addition, we will conclude that many current datasets overestimate the performance of tested systems by providing data in an already pre-attended form.
25 years of CNNs: Can we compare to human abstraction capabilities?
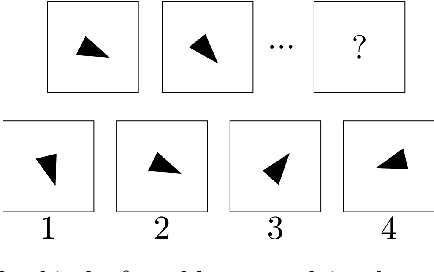
Jul 28, 2016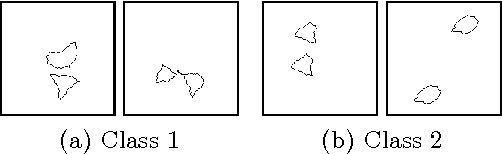
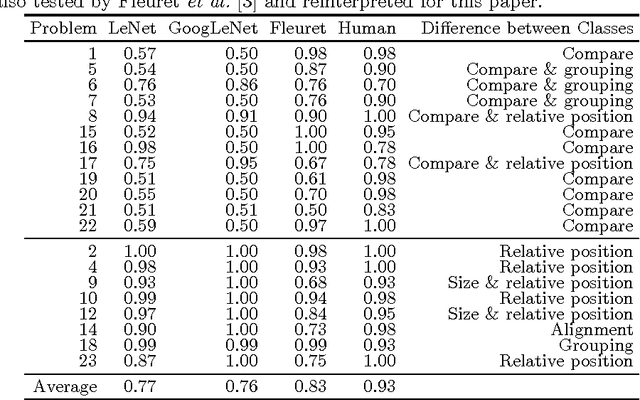
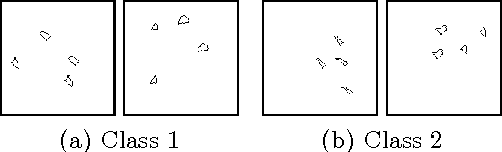

We try to determine the progress made by convolutional neural networks over the past 25 years in classifying images into abstractc lasses. For this purpose we compare the performance of LeNet to that of GoogLeNet at classifying randomly generated images which are differentiated by an abstract property (e.g., one class contains two objects of the same size, the other class two objects of different sizes). Our results show that there is still work to do in order to solve vision problems humans are able to solve without much difficulty.